Redis的主从复制是如何工作的?如何在同步数据的同时,还保持着高性能,你了解吗?
-
- https://redis.io/topics/replication
注意以下基于 redis 5 最新版本,slave名词和配置项已经被官方改为replica,其实是一个东西,都指从节点。
- https://redis.io/topics/replication
主从复制的基本流程
# Master-Replica replication. Use replicaof to make a Redis instance a copy of
# another Redis server. A few things to understand ASAP about Redis replication.
#
# +------------------+ +---------------+
# | Master | ---> | Replica |
# | (receive writes) | | (exact copy) |
# +------------------+ +---------------+
#
# 1) Redis replication is asynchronous, but you can configure a master to
# stop accepting writes if it appears to be not connected with at least
# a given number of replicas.
# 2) Redis replicas are able to perform a partial resynchronization with the
# master if the replication link is lost for a relatively small amount of
# time. You may want to configure the replication backlog size (see the next
# sections of this file) with a sensible value depending on your needs.
# 3) Replication is automatic and does not need user intervention. After a
# network partition replicas automatically try to reconnect to masters
# and resynchronize with them.
#
# replicaof
主 Master 与 从 replica 复制的基本流程
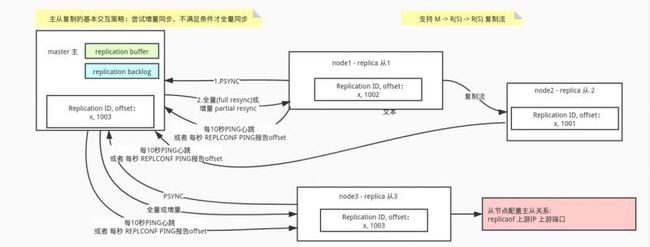
- 主 Master 和 replica 连接稳定时,Master 持续进行增量同步(
partial resync),发送增量数据给 replica, replica接受到数据后更新自己的数据,并以每秒REPLCONFACK PING 给 Master 报告处理的情况。 - 如果replica与Master断开再重连时,replica 尝试发送
PSYNC命令给 Master, 如果条件满足(比如引用的是已知的历史副本,或backlog积压足够)则触发继续增量同步(partial resync)。否则将触发一次 Master 向该 replica 全量同步(full resync)

从以上基本流程中,我们可以看出来如果网络存在问题,我们可以会导致全量同步(full resync),这样会严重影响从replica追赶master的数据进度。
那么如何解决呢?
可以从两个方面:主从响应时间策略、主从空间堆积策略。
主从响应时间策略
- 1、每repl-ping-replica-period 秒PING一次 Master,检测 Master是否挂了。
repl-ping-replica-period 10
- 2、replica(salve)和 Master之间的复制超时时间,默认为60s
- a) replica 角度,在全量同步SYNC期间,没有收到master传输的 RDB 数据
- b) replica 角度,没有收到master发送的数据包或者replica发送的PING响应
- c) master角度,没有收到replica 的REPCONF ACK PINGs(复制偏移量offset)。
当redis检测到repl-timeout超时(默认值60s),将会关闭主从之间的连接,redis replica 发起重新建立主从连接的请求。
repl-timeout 60
主从空间堆积策略
Master 在接受数据写入后,会写到 replication buffer(这个主要用于主从复制的数据传输缓冲),同时也写到 积压replication backlog。
当replica断开重连 PSYNC (包含replication ID,和目前已处理的offset),如果replication backlog 中可以找到历史副本,则触发增量同步(partial resync),否则将触发
一次 Master 向该 replica 全量同步(full resync)。
# Set the replication backlog size. The backlog is a buffer that accumulates
# replica data when replicas are disconnected for some time, so that when a replica
# wants to reconnect again, often a full resync is not needed, but a partial
# resync is enough, just passing the portion of data the replica missed while
# disconnected.
#
# The bigger the replication backlog, the longer the time the replica can be
# disconnected and later be able to perform a partial resynchronization.
#
# The backlog is only allocated once there is at least a replica connected.
#
# repl-backlog-size 1mb
积压replication backlog的相关参数:
# 增量同步窗口
repl-backlog-size 1mb
repl-backlog-ttl 3600
full resync 全量同步工作流程
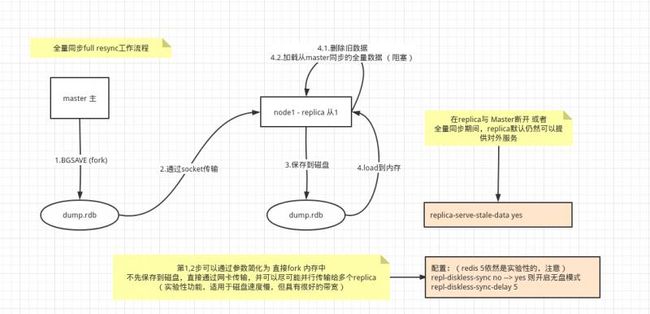
全量同步的工作流程:
- replica发送PSYNC。
(假设满足全量同步的条件) - Master 通过子进程处理全量同步,子进程通过
BGSAVE命令,fork一个子进程写入快照 dump.rdb。同时,Master 开始缓冲从客户端收到的所有新写命令到replication buffer。 - Master子进程通过网卡传输 rdb数据给 replica。
- replica 保存 rdb数据到磁盘,然后加载到内存(删除旧数据,并阻塞加载新数据)
(后续就是增量同步)
其中 master 如果磁盘慢,而带宽比较好,可以使用无盘模式(需要注意,这是实验性的):
repl-diskless-sync no --> yes 则开启无盘模式
repl-diskless-sync-delay 5
replica在全量同步或断开连接期间,默认是可以提供服务的。
replica-serve-stale-data yes
replica在在 replica加载到内存的时间窗口,replica会阻塞客户端的连接。
如果保证数据安全交付 (Allow writes only with N attached replicas )
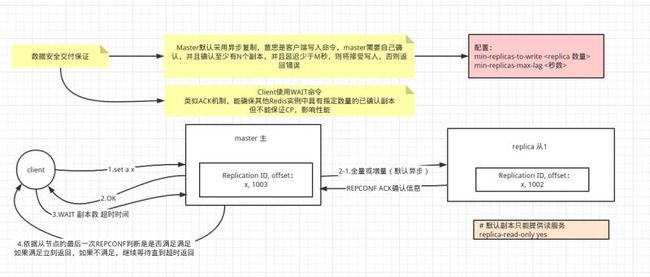
Master默认采用异步复制,意思是客户端写入命令,master需要自己确认,并且确认至少有N个副本,并且延迟少于M秒,则将接受写入,否则返回错误
# 默认是没开启的
min-replicas-to-write
min-replicas-max-lag <秒数>
另外客户端Client可以使用WAIT命令类似ACK机制,能确保其他Redis实例中具有指定数量的已确认副本。
127.0.0.1:9001>set a x
OK.
127.0.0.1:9001>wait 1 1000
1
故障转移

replication ID 的作用主要是标识来自 当前 master 的数据集标识。
replication ID 有两个:master_replid,master_replid2
127.0.0.1:9001> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=9011,state=online,offset=437,lag=1
master_replid:9ab608f7590f0e5898c4574299187a52ad0db7ec
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:437
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:437
当 master 挂了,其中一个replica 升级为 master,它将开启一个新纪元,生成新的 replication ID : master_replid
同时旧的 master_replid 设置到 master_replid2。
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=9021,state=online,offset=34874,lag=0
slave1:ip=127.0.0.1,port=9001,state=online,offset=34741,lag=0
master_replid:dfa343264a79179c1061f8fb81d49077db8e4e5f
master_replid2:9ab608f7590f0e5898c4574299187a52ad0db7ec
master_repl_offset:34874
second_repl_offset:6703
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:34874
这样其他replica 连接新的 master 就不需要又来一次全量同步,可以继续副本同步完,再使用新的纪元数据。
replica如何处理已过期的 Key ?
- replica 不主动让已过期的key 被删除掉,只有当 Master 通过LRU等内存淘汰策略或主动访问过期,合成 DEL 命令给到 replica ,replica 才会删掉它
- 以上存在一个时间差,replica 内部采用逻辑时钟,当客户端client尝试读取一个过期key的时候,replica 会报告不存在。
@SvenAugustus(https://www.flysium.xyz/)
更多请关注微信公众号【编程不离宗】,专注于分享服务器开发与编程相关的技术干货:
