程序(进程)在cpu中的执行过程
渣理解:
内存
CPU
进程
程序
程序编译好后,存于某个地方(外存),
当程序被要求运行时,做的事情如下:
1.把可执行程序相关数据代码等加载到内存的相应段?
2.等待cpu调度到此程序,也即是获取cpu的使用权
3.运行balabala...
那我fork一个进程又是什么回事???
复制与当前程序(进程)一模一样的资源与代码???丢到进程调度队列那里去,让它有机会执行,同时我传一些特殊数据给它,让它做我需要它做的事情?
不是,它是每个进程有一个对应的程序的,还是不懂。
1. 进程是程序的一次运行活动,属于一种动态的概念。 程序是一组有序的静态指令,是一种静 态 的 概 念。 但 是, 进 程 离 开 了程 序 也 就 没 有 了 存 在 的 意 义。 因 此, 我 们 可 以 这 样 说: 进 程 是 执 行 程 序 的 动 态 过 程, 而 程 序 是 进程 运 行 的 静 态 文 本。 如 果 我 们 把 一 部 动 画 片 的 电 影 拷 贝 比 拟 成 一 个 程 序, 那 么 这 部 动 画 片 的 一次 放 映 过 程 就 可 比 为 一 个 进 程。
2. 一 个 进 程 可 以 执 行 一 个 或 多个 程 序。 例 如: 一 个 进 程 进 行C 源 程 序 编 译 时,它 要 执 行 前 处 理、 词 法 语 法 分 析、 代 码 生 成 和 优 化 等 几 个 程 序。 反 之, 同 一 程 序 也 可 能 由 多 个 进程 同 时 执 行, 例 如: 上 述C 编 译 程 序 可 能 同 时 被 几 个 程 序 执 行, 它 们对 相 同 或 不 同 的 源 程 序 分 别 进 行 编 译, 各 自 产 生 目 标 程 序。 我 们 再 次 以 动 画 片 及 其 放 映 活 动 为例, 一 次 电 影 放 映 活 动 可 以 连 续 放 映 几 部 动 画 片, 这 相 当 于 一 个 进 程 可 以 执 行 几 个 程 序。 反 之,一 部 动 画 片 可 以 同 时 在 若 干 家 电 影 院 中 放 映, 这 相 当 于 多 个 进 程 可 以 执 行 几 个 同 一 程 序。 不 过要 注 意 的 是, 几 家 电 影 院 放 映 同 一 部 电 影, 如 果 使 用 的 是 同 一 份 拷 贝, 那 么 实 际 上 是 交 叉 进 行 的。但 在 多 处 理 机 情 况 下, 几 个 进 程 却 完 全 可 以 同 时 使 用 一 个 程 序 副 本。
3. 程 序 可 以 作 为 一 种 软 件 资 源长 期 保 持 着, 而 进 程 则 是 一 次 执 行 过 程, 它 是 暂时 的, 是 动 态 地 产 生 和 终 止 的。 这 相 当 于 电 影 拷 贝 可 以 长 期 保 存, 而 一 次 放 映 活 动 却 只延 续1~2 小 时。
进 程 需 要 使 用 一 种 机 构才 能 执 行 程 序, 这 种 机 构 称 之 为 处 理 机(Processor)。 处 理 机 执 行 指令, 根 据 指 令 的 性 质, 处 理 机 可 以 单 独 用 硬 件 或 软、 硬 件 结 合 起 来 构 成。 如 果 指 令 是 机 器 指 令, 那么 处 理 机 就 是 我 们 一 般 所 说 的 中 央 处 理 机(CPU)。
--------------------- 本文来自 fuqin163 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/fuqin163/article/details/1546919?utm_source=copy
https://blog.csdn.net/woaigaolaoshi/article/details/51039505
cpu主要是由运算器、寄存器、控制器和译码器组成,当我们运行一段代码的时候,代码被加载进寄存器中,(单cpu单核的情况)当有另一个进程需要运行的时候,第一个进程就会被存入pcb的栈中,等到一定的时间在重新加载到寄存器中运行。
一般情况下,cpu处理数据能力有1Ghz=1ns,多进程的时候cpu采取分时复用的方式进行,每个进程10ms或者其他时间的进行交换,由于运行速度很快所以用户感觉不到在交换,觉得是在同时运行。
进程有四种状态,运行态,就绪态,睡眠态,停止态。其中的状态转变如图所示。
--------------------- 本文来自 qyy1028 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/qianyayun19921028/article/details/81362016?utm_source=copy
线程和进程、程序、应用程序之间的关系
看到一种说法是“一个程序至少有一个进程,一个进程至少有一个线程”,这种把程序与进程,进程与线程的关系混淆的说法是错误的。
程序(program)只能有一个进程,一个进程就是一个程序。有人说,我打开一个程序,比如chrome,有十多个进程呢,这是咋回事。那就是十多个程序,操作系统给他们分配了彼此独立的内存,相互执行不受彼此约束,分配同样时间的CPU。对于用户而言,他们是一个整体,我们通常称之为应用程序(application)。对于计算机而言,一个进程就是一个程序,多个进程(比如一个浏览器的多个进程)对计算机而言就是多个不同的程序,它不会把它们理解为一个完整的“程序”。
其实进程之间的关系只有父子关系,没有主从关系,他们之间是并行独立的。但是线程之间是有主从关系的,而且他们共享的是同一个内存块(包括程序、数据和堆栈)。
打个比方,进程之间是父子关系,父进程fork子进程,就好比你养了个儿子。这个子进程会拷贝一份内存块,把程序和数据都复制过去,你儿子跟你长的也很像。但是一旦出生下来了,你们就是两个独立的个体,法律上都是平等的。子进程之后就完全独立了,父进程与子进程之间的关系,与其他进程的关系都是一样的,平等的,谁也管不着谁了,他们也只能采用进程间通信才能相互了解。父亲死了,儿子还活着;父进程over了,子进程可以照样活的好好的。(除非程序员认定有一个进程over了,其他进程没有存在的意义,比如浏览器负责渲染的进程如果down掉了,其他进程自动kill掉)。
但是进程的不同线程的关系可不是这样的。进程可以由多个线程组成,这称之为多线程程序,他们之间的关系就好比你的大脑与四肢和身体其他部分的关系一样。大脑就是主线程,其他部分就是子线程。子线程由主线程派生,而依附于主线程。主线程一旦over,进程就over了,其他子线程更是over了。他们的内存和数据都是同一份,没有进行隔离(既方便,也危险),不需要额外的通信函数。
父亲死了,儿子依旧活下去,你头断了,人还能活吗?
了解进程与线程的关系,就要了解他们的区别。一个计算机可以有多个进程,这称之为多任务,他们共享的是CPU,硬盘,打印机,显示器,但他们的内存是独立的,所以需要进程间通信,这是计算机发展的第一步。一个进程可以有多个线程,这称之为多线程,他们除了共享进程间的共享内容之外,还共享内存,这是计算机发展的第二步,主要是为了满足并行运算时共享数据,无需额外的通信。
所以正确的结论是:一个程序(program)就是一个正在执行的进程,而每个进程,可以是单线程的,也可以是多线程的。一个应用程序(application)通常由多个程序组成。
还是强调下程序(program)和应用程序(application)的区别。一个程序就是一个进程,永远不要说一个程序可能有多个进程。你打开一个应用程序(比如chrome),会有十多个进程,对于计算机而言,它们都是独立的。好比,父亲和儿子在外人看来是一家人,但是对于法律上来说,就是独立的法人。
https://blog.csdn.net/jxq0816/article/details/50200023
1)进程是程序及其数据在计算机的一次运行活动,是一个运行过程,是一个动态的概念。进程的运行实体是程序,离开程序的进程没有存在的意义。而程序是一组有序的指令集合,是一种静态概念。
2)进程是程序的一次执行过程,它是动态地创建和消亡的,具有一定的生命周期,是暂时存在的;而程序则是一组代码的集合,它是永久存在的,可长期保存。
3)一个进程可以执行一个或几个程序,一个程序也可以构成多个进程。进程可以创建进程,而程序不能形成新的程序。
4)进程和程序的组成不同。从静态角度看,进程由程序、数据和进程控制块(PCB)三部分组成。而程序是一组有序的指令集合。
--------------------- 本文来自 姜兴琪 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/jxq0816/article/details/50200023?utm_source=copy
https://blog.csdn.net/dong_daxia/article/details/80289951
http://www.cnblogs.com/clover-toeic/p/3754433.html
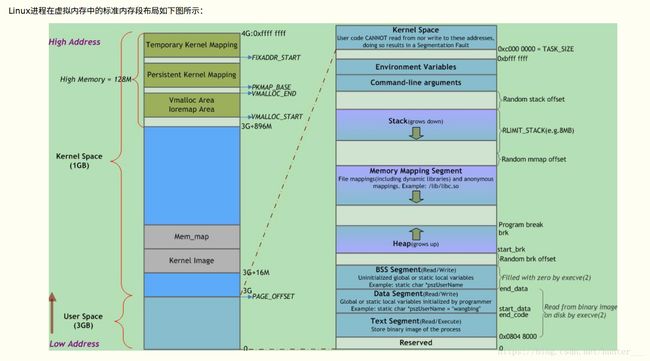
在将应用程序加载到内存空间执行时,操作系统负责代码段、数据段和BSS段的加载,并在内存中为这些段分配空间。栈也由操作系统分配和管理;堆由程序员自己管理,即显式地申请和释放空间。
BSS段、数据段和代码段是可执行程序编译时的分段,运行时还需要栈和堆。
6 数据段(Data)
数据段通常用于存放程序中已初始化且初值不为0的全局变量和静态局部变量。数据段属于静态内存分配(静态存储区),可读可写。
数据段保存在目标文件中(在嵌入式系统里一般固化在镜像文件中),其内容由程序初始化。例如,对于全局变量int gVar = 10,必须在目标文件数据段中保存10这个数据,然后在程序加载时复制到相应的内存。
数据段与BSS段的区别如下:
1) BSS段不占用物理文件尺寸,但占用内存空间;数据段占用物理文件,也占用内存空间。
对于大型数组如int ar0[10000] = {1, 2, 3, ...}和int ar1[10000],ar1放在BSS段,只记录共有10000*4个字节需要初始化为0,而不是像ar0那样记录每个数据1、2、3...,此时BSS为目标文件所节省的磁盘空间相当可观。
2) 当程序读取数据段的数据时,系统会出发缺页故障,从而分配相应的物理内存;当程序读取BSS段的数据时,内核会将其转到一个全零页面,不会发生缺页故障,也不会为其分配相应的物理内存。
运行时数据段和BSS段的整个区段通常称为数据区。某些资料中“数据段”指代数据段 + BSS段 + 堆。
7 代码段(text)
代码段也称正文段或文本段,通常用于存放程序执行代码(即CPU执行的机器指令)。一般C语言执行语句都编译成机器代码保存在代码段。通常代码段是可共享的,因此频繁执行的程序只需要在内存中拥有一份拷贝即可。代码段通常属于只读,以防止其他程序意外地修改其指令(对该段的写操作将导致段错误)。某些架构也允许代码段为可写,即允许修改程序。
代码段指令根据程序设计流程依次执行,对于顺序指令,只会执行一次(每个进程);若有反复,则需使用跳转指令;若进行递归,则需要借助栈来实现。
代码段指令中包括操作码和操作对象(或对象地址引用)。若操作对象是立即数(具体数值),将直接包含在代码中;若是局部数据,将在栈区分配空间,然后引用该数据地址;若位于BSS段和数据段,同样引用该数据地址。
代码段最容易受优化措施影响。
【扩展阅读】分段的好处
进程运行过程中,代码指令根据流程依次执行,只需访问一次(当然跳转和递归可能使代码执行多次);而数据(数据段和BSS段)通常需要访问多次,因此单独开辟空间以方便访问和节约空间。具体解释如下:
当程序被装载后,数据和指令分别映射到两个虚存区域。数据区对于进程而言可读写,而指令区对于进程只读。两区的权限可分别设置为可读写和只读。以防止程序指令被有意或无意地改写。
现代CPU具有极为强大的缓存(Cache)体系,程序必须尽量提高缓存命中率。指令区和数据区的分离有利于提高程序的局部性。现代CPU一般数据缓存和指令缓存分离,故程序的指令和数据分开存放有利于提高CPU缓存命中率。
当系统中运行多个该程序的副本时,其指令相同,故内存中只须保存一份该程序的指令部分。若系统中运行数百进程,通过共享指令将节省大量空间(尤其对于有动态链接的系统)。其他只读数据如程序里的图标、图片、文本等资源也可共享。而每个副本进程的数据区域不同,它们是进程私有的。
此外,临时数据及需要再次使用的代码在运行时放入栈区中,生命周期短。全局数据和静态数据可能在整个程序执行过程中都需要访问,因此单独存储管理。堆区由用户自由分配,以便管理。
YouTube上的一个视频How does CPU execute program,是一个很好的CPU执行程序原理的总结,英文水平还行的人建议看原视频,就不用听我瞎BB了。虽然没有字幕,如果能看懂里面的PPT,就基本能理解了。
以下内容主要是将视频内容大致解释一下,是写给英文水平欠缺一点或者没办法看原视频的人看的。如有错误,欢迎指正。
相关术语
RAM:指内存,断电后内容无法保存,因此叫做易失性存储;另一个相关的概念是ROM,一般指外存,例如硬盘。RAM的速度远快于ROM,CPU与内存直接进行数据交换。
CPU:计算机的所有计算操作都由它执行,只要先记住它是一块有输入和输出的集成电路就行了。
Instruction:指令,是CPU进行操作的基本单元,大致包含操作对象、操作对象的地址、对操作对象进行何种操作。
RAM相关结构
程序要想被CPU执行,首先要被编译成CPU可以执行的指令操作,这里就不详细介绍,本文就假设程序已经被编译好了,放在了内存中。内存中存放的数据分为两类,一类是指令;另一类是数据,不管是指令还是数据都有其对应的地址。
下图就是接下来我们将会涉及的内存结构,这是从视频中直接截取下来的,大家将就着看。
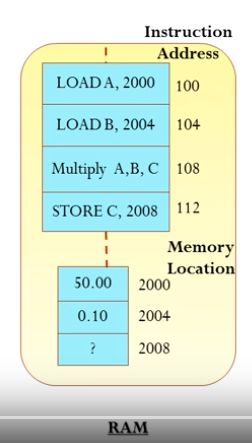
在上图中,现在已经存放了地址为100、104、108、112的一系列指令;地址为2000、2004、2008的一系列数据。
CPU相关结构
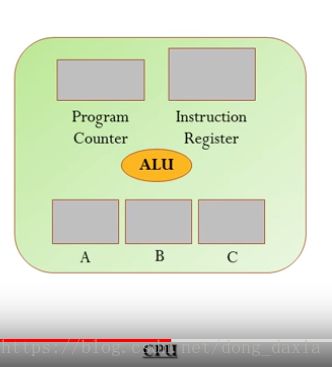
这里只放出CPU的执行指令时涉及的基本结构,真实的情况还会复杂很多。
这里涉及到的结构有Program Counter(程序计数器)、Instruction Register(指令寄存器)、Data Register(数据寄存器)、ALU(算数逻辑单元),可以将计数器、寄存器都可以简单理解为存放数据的器件。上述程序计数器用来存放指令的地址;指令寄存器用来存放指令(初学者可能会搞混数据和地址的区别,稍加区分就可以分辨);数据寄存器存放参与计算的数据,下图中的A、B、C都是数据寄存器;ALU就是用于计算的器件。
执行过程
本文内容为便于理解,仅涉及到CPU和内存间的数据交换。
在了解了RAM和CPU相关结构之后,接下来就可以正式开始说明执行的过程,其实就是对以上叙述内容的一个组合。
- 程序计数器初始内容为100,指向内存中的某一项指令,注意100指的是地址;
- 指令寄存器根据程序计算器的指向地址,将内存中地址为100的指令抓取到自身,此时存放LOAD A,2000;
- CPU按照指令内容,将内存地址为2000的数据,上载到数据寄存器A中,此时CPU和RAM的状态如下图所示;
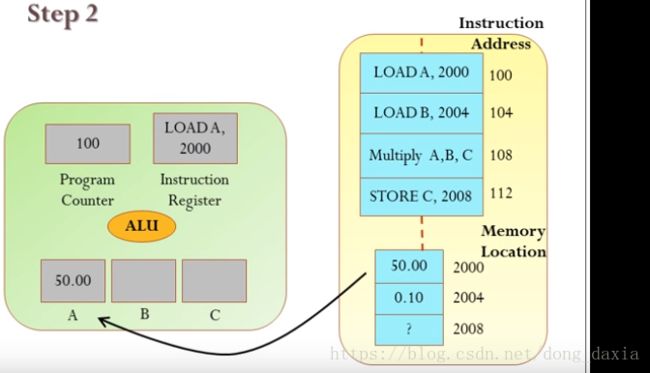
- 以上3步已完成一个指令的基本操作步骤。接下来程序计数器依次指向104指令地址、108指令地址、112指令地址,分别完成将2004地址的数据赋值给B数据寄存器;ALU将A、B内的数据相乘赋值给C数据寄存器;将C数据寄存器数据写入内容地址2008中。
- 这样就完成了50×0.1这个简单程序的计算,最后CPU和RAM所处状态如下图所示。
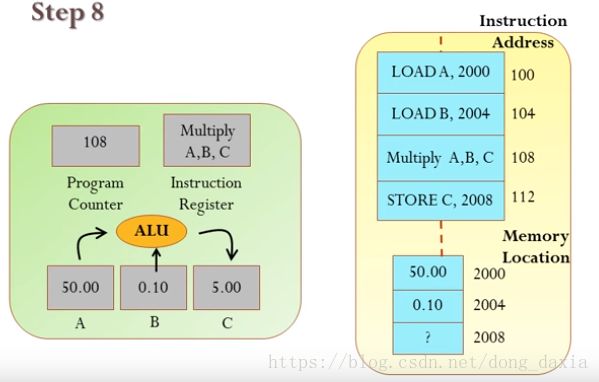
--------------------- 本文来自 董大虾 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/dong_daxia/article/details/80289951?utm_source=copy
程序的运行机制——CPU、内存、指令的那些事
2017年03月11日 09:55:49 wxfbolg 阅读数:3109 标签: 内存 cpu 计算机 更多
个人分类: 计算机组成原理
- 序言
说起计算机大家并不陌生,在计算机上又运行着各种程序,如QQ、微信等。这些程序有可以为我们做很多事情,能聊天、能玩游戏等等。那么这些看似复杂的程序在计算机中到底是怎么运行起来的呢?其实非常简单,我们不妨一起探讨一下。
作为程序员我们必须理解CPU是如何运行的,特别是要弄清楚负责保存指令和数据的寄存器的机制。了解了寄存器,也就自然而然的理解了程序的运行机制。 - CPU的构成
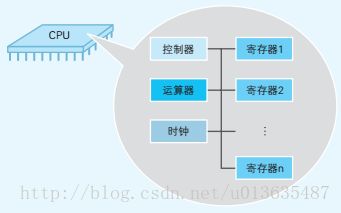
在程序运行流程中,CPU所负责的就是解析和运算最终转换成机器语言的程序内容。CPU从功能上来看由寄存器、控制器、运算器、时钟构成。
 |
 |
|---|---|
| CPU的构成 | CPU是寄存器的集合体 |
寄存器:用来暂存指令、数据等处理对象。
控制器:负责把内存上的指令、数据等读入寄存器、并根据指令的执行结果来控制计算机。
运算器:负责运算从内存读入寄存器的数据。
时钟:负责发出CPU开始计时的时钟信号
- 内存的作用
内存指的就是计算机的主存储器,其主要负责存储指令和数据。CPU通过内存地址值来读取或写入指令和数据。注意:内存中的指令和数据会随着计算机的关机日自动清除。
在理解了CPU和内存后,大家对程序的运行机制的理解是不是也加深了一些?程序启动后,根据时钟信号,控制器会从内存中读取指令和数据。通过对这些指令加以解析和运行,运算器就会对数据进行运算,控制器根据运算结果控制计算机。 - 决定程序流程的程序计数器
下面我们通过将123和456两个数相加,并将结果输出到显示器的实例,说一下程序计数器是如何工作的。
当用户发出启动程序的指示后,操作系统会把硬盘中保存的程序复制到内存中。如下图是程序启动时内存内容的模型。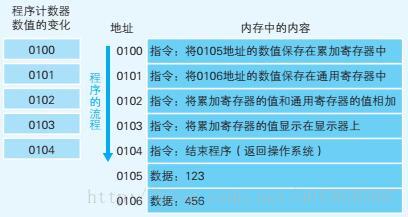
操作系统把程序复制到内存后,会将程序计数器设定为0100(假设内存地址0100是程序运行的开始地址),然后程序便开始运行。CPU每执行一个指令,程序计数器的值就会自动加1。所以,程序计数器决定着程序的流程。 -
指令
从功能方面来看,机器语言指令可分为数据传送指令、算数指令、跳转指令、call/return指令。数据传送指令:寄存器和内存、内存和内存、寄存器和外围设备之间的数据读写操作
运算指令:用累加寄存器执行算术运算、逻辑运算、比较运算和位移运算
跳转指令:实现条件分支、循环、强制跳转等
call/return指令:函数的调用/返回调用前的地址 -
函数调用
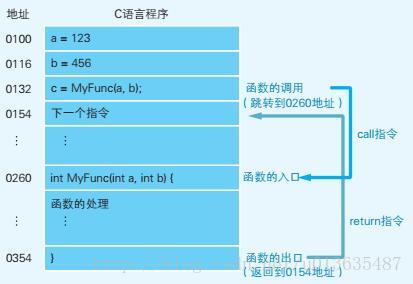
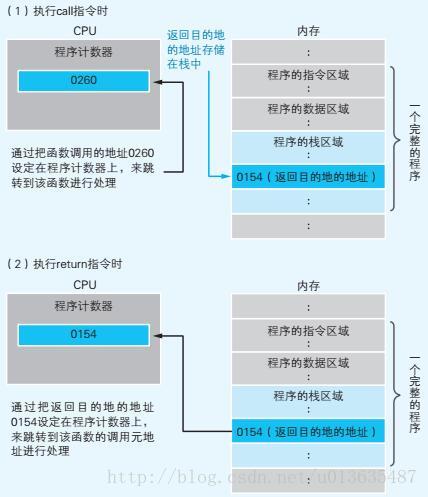
call指令和return指令是如何实现函数调用的呢?
其实call指令在将函数的入口地址设定到程序计数器之前,call指令会把调用函数后要执行的指令地址存储在名为栈的主存内。函数处理完毕后,再通过函数的出口来执行return命令。return命令的功能就是把保存的栈中的地址设定到程序计数器中。如下面的图示,MyFunc函数被调用之前,0154地址保存在栈中。MyFunc函数的处理完毕后,栈中的0154地址就会被读取出来,然后再被设定到程序计数器中。
 |
 |
|---|---|
| 程序调用函数示例 | 函数调用中程序计数器和栈的职能 |
一个程序从源代码到可执行程序的过程
https://blog.csdn.net/qq_39755395/article/details/78293733?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromMachineLearnPai2-1.nonecase