在自定义宝可梦数据集上使用resnet18网络
目录结构
train
validation
test
一般来说现在都是用Adam这个优化器,这个优化器算是性能最好的
SGD不能优化的,Adam都能很好的优化
如果没有特别的要求一般来说都是用Adam这个优化器
train.py
import torch from torch import optim, nn import visdom import torchvision from torch.utils.data import DataLoader from pokemon import Pokemon from resnet import ResNet18 batchsz = 32 lr = 1e-3 epochs = 10 device = torch.device('cuda') torch.manual_seed(1234) train_db = Pokemon('dataset/pokemon',224,mode='train') val_db = Pokemon('dataset/pokemon',224,mode='val') test_db = Pokemon('dataset/pokemon',224,mode='test') train_loader = DataLoader(train_db, batch_size=batchsz, shuffle=True, num_workers=4) val_loader = DataLoader(val_db, batch_size=batchsz, shuffle=True, num_workers=2) test_loader = DataLoader(test_db, batch_size=batchsz, shuffle=True, num_workers=2) viz = visdom.Visdom() def evalute(model, loader): correct = 0 total = len(loader.dataset) for x,y in loader: x,y = x.to(device), y.to(device) with torch.no_grad(): logits = model(x) pred = logits.argmax(dim=1) correct += torch.eq(pred, y).sum().float().item() return correct/total def main(): model = ResNet18(5).to(device) optimizer = optim.Adam(model.parameters()) # criteon = nn.CrossEntropyLoss() #接受的是logits best_acc, best_epoch = 0, 0 best_acc, best_epoch = 0,0 global_step=0 viz.line([0],[-1], win='loss', opts=dict(title='loss')) viz.line([0],[-1], win='val_acc', opts=dict(title='val_acc')) for epoch in range(epochs): for step, (x,y) in enumerate(train_loader): #x: [b,3,224,224] y:[b] x,y = x.to(device), y.to(device) logits = model(x) loss = criteon(logits,y) optimizer.zero_grad() loss.backward() optimizer.step() viz.line([loss.item()],[global_step], win='loss', update='append') global_step += 1 if epoch % 1 ==0: #2个epoch做一个validation val_acc = evalute(model, val_loader) if val_acc > best_acc: best_epoch = epoch best_acc = val_acc torch.save(model.state_dict(), 'best.mdl') viz.line([val_acc],[global_step], win='val_acc', update='append') print('best acc:', best_acc, 'best epoch:',best_epoch) model.load_state_dict(torch.load('best.mdl')) print('loaded from ckpt!') test_acc = evalute(model, test_loader) print('test acc:', test_acc) if __name__=='__main__': main()pokemon.py
import torch import os,glob import random,csv import visdom import time from torch.utils.data import Dataset from torchvision import transforms from PIL import Image class Pokemon(Dataset): def __init__(self,root, resize, mode): super(Pokemon,self).__init__() self.root = root self.resize = resize #----------------编号----------------------------------- self.name2label = {} #给不同类别的图片编号,比如妙蛙种子是0 for name in sorted(os.listdir(os.path.join(root))): if not os.path.isdir(os.path.join(root,name)): continue self.name2label[name] = len(self.name2label.keys()) # print(self.name2label) #----------------------------------------------------- #------------------------裁剪----------------------- #image, label self.images, self.labels = self.load_csv('images.csv') if mode=='train': #选60%的数据用于train self.images = self.images[:int(0.6*len(self.images))] self.labels = self.labels[:int(0.6*len(self.labels))] elif mode == 'val': #20%的数据用于validationn self.images = self.images[int(0.6*len(self.images)):int(0.8*len(self.images))] self.labels = self.labels[int(0.6*len(self.labels)):int(0.8*len(self.labels))] else: #20%的数据用于test self.images = self.images[int(0.8*len(self.images)):] self.labels = self.labels[int(0.8*len(self.labels)):] #----------------------------------------------------------- def load_csv(self,filename): #print(self.root) if not os.path.exists(os.path.join(self.root,filename)): images = [] for name in self.name2label.keys(): #'pokemon\\mewtwo\\00001.png' images += glob.glob(os.path.join(self.root, name,'*.png')) images += glob.glob(os.path.join(self.root,name,'*.jpg')) images += glob.glob(os.path.join(self.root, name, '*.jpeg')) #1167,'dataset/pokemon\\bulbasaur\\00000000.png' print(len(images),images) #打乱一下 random.shuffle(images) with open(os.path.join(self.root,filename),mode='w',newline='') as f: writer = csv.writer(f) for img in images: name = img.split(os.sep)[-2] label = self.name2label[name] #'dataset/pokemon\\bulbasaur\\00000000.png',0 writer.writerow([img,label]) print('write into csv file:',filename) #read from csv file images, labels = [],[] with open(os.path.join(self.root, filename)) as f: reader = csv.reader(f) for row in reader: #'dataset/pokemon\\bulbasaur\\00000000.png',0 img,label = row label = int(label) images.append(img) labels.append(label) assert len(images) == len(labels) return images, labels def __len__(self): return len(self.images) def denormalize(self, x_hat): mean = [0.485,0.456,0.406] std = [0.229,0.224,0.225] #normalize的流程: x_hat = (x-mean)/std #我们要denormalize: x_hat*std + mean #x: [c,h,w] #mean: [3] => [3,1,1] mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1) std = torch.tensor(std).unsqueeze(1).unsqueeze(1) x = x_hat * std + mean return x def __getitem__(self, idx): #idx的范围 [0~len(images)] #img:'dataset/pokemon\\bulbasaur\\00000000.png' #label : 0/1/2/3/4 img,label = self.images[idx],self.labels[idx] tf = transforms.Compose([ lambda x:Image.open(x).convert('RGB'), #string path => image data transforms.Resize((int(self.resize*1.25), int(self.resize*1.25))), transforms.RandomRotation(15), transforms.CenterCrop(self.resize), transforms.ToTensor(), transforms.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225]) ]) img = tf(img) label = torch.tensor(label) return img,label def main(): viz = visdom.Visdom() db = Pokemon('dataset/pokemon',224,'train') x,y = next(iter(db)) print('sample:', x.shape, y.shape, y) viz.image(db.denormalize(x), win='sample_x', opts=dict(title='sample_x')) if __name__ == '__main__': main()resnet.py
import torch from torch import nn from torch.nn import functional as F class ResBlk(nn.Module): """ resnet block """ def __init__(self, ch_in, ch_out, stride=1): """ :param ch_in: :param ch_out: """ super(ResBlk, self).__init__() self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1) self.bn1 = nn.BatchNorm2d(ch_out) self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1) self.bn2 = nn.BatchNorm2d(ch_out) self.extra = nn.Sequential() if ch_out != ch_in: # [b, ch_in, h, w] => [b, ch_out, h, w] self.extra = nn.Sequential( nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride), nn.BatchNorm2d(ch_out) ) def forward(self, x): """ :param x: [b, ch, h, w] :return: """ out = F.relu(self.bn1(self.conv1(x))) out = self.bn2(self.conv2(out)) # short cut. # extra module: [b, ch_in, h, w] => [b, ch_out, h, w] # element-wise add: out = self.extra(x) + out out = F.relu(out) return out class ResNet18(nn.Module): def __init__(self, num_class): super(ResNet18, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(3, 16, kernel_size=3, stride=3, padding=0), nn.BatchNorm2d(16) ) # followed 4 blocks # [b, 16, h, w] => [b, 32, h ,w] self.blk1 = ResBlk(16, 32, stride=3) # [b, 32, h, w] => [b, 64, h, w] self.blk2 = ResBlk(32, 64, stride=3) # # [b, 64, h, w] => [b, 128, h, w] self.blk3 = ResBlk(64, 128, stride=2) # # [b, 128, h, w] => [b, 256, h, w] self.blk4 = ResBlk(128, 256, stride=2) # [b, 256, 7, 7] self.outlayer = nn.Linear(256*3*3, num_class) def forward(self, x): """ :param x: :return: """ x = F.relu(self.conv1(x)) # [b, 64, h, w] => [b, 1024, h, w] x = self.blk1(x) x = self.blk2(x) x = self.blk3(x) x = self.blk4(x) # print(x.shape) x = x.view(x.size(0), -1) x = self.outlayer(x) return x def main(): blk = ResBlk(64, 128) tmp = torch.randn(2, 64, 224, 224) out = blk(tmp) print('block:', out.shape) model = ResNet18(5) tmp = torch.randn(2, 3, 224, 224) out = model(tmp) print('resnet:', out.shape) p = sum(map(lambda p:p.numel(), model.parameters())) #打印参数量 print('parameters size:', p) if __name__ == '__main__': main()
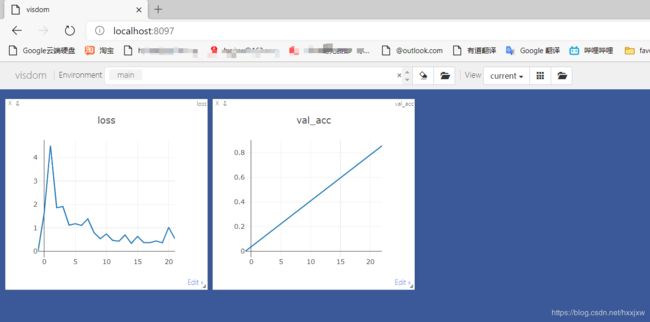
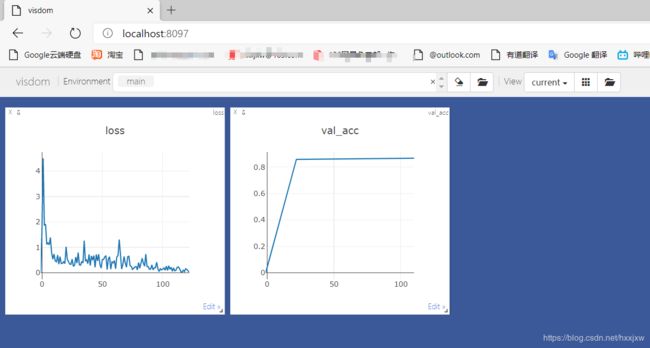
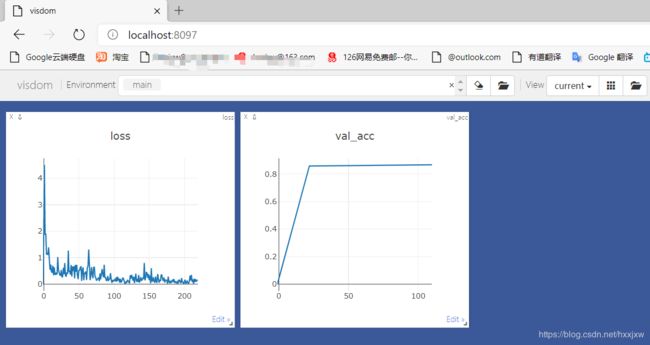
运行train.py
训练完成之后