Monte Carlo Integration
Monte Carlo integration uses a different perspective from Quadrature Integration to consider the problem of integration. Quadrature Integration from discrete to continuous, mainly uses the concept of limit convergence and continuous. Monte Carlo integral extended sampling and mathematical expectation of random variables.
Probability Background
Cumulative Distributions and Density Functions
The cumulative distribution function, or CDF, of a random variable \(X\) is the probability that a value chosen from the variable’s distribution is less than or equal to some thresold \(x\):
The corresponding probability density function, or PDF, is the derivative of the CDF:
and we can calculate the probility within an interval:
Expected Values and Variance
The expected value or expectation of a random variable \(Y = f(x)\) over a domain \(\mu(x)\) is defined as:
while its variance is:
The basic knowledge of probability statistics is this, and we will explain it when we use if have others
TheMonte Carlo Estimator
The Basic Estimator
Monte Carlo integration uses random sampling of a function to numerically compute an estimate of its integral. Suppose that we want to integrate the one-dimensional function \(f (x)\) from \(a\) to \(b\):
We can approximate this integral by averaging samples of the function \(f\) at uniform random points within the interval. Given a set of \(N\) uniform random variables \(X_i\in \left[ a,b \right)\) with a corresponding PDF of \(1/(b-a)\), theMonte Carlo estimator for computing \(F\) is:
I think using an example directly, with \(N=4\) and interval \([a,b)\), using uniformly distributed probability density, using random sampling can explain this formula very well.

We use random sampling to get the value of random variable as shown above, as \(f(X_0)\), \(f(X_1)\), \(f(X_2)\), \(f(X_3)\).
Then we use the following picture to simulate integration.

But this integration process is a combination of sampling and statistical calculation of digital characteristics, which is Expected Values. This process is the process of formula (1). If we extend the number 4 to \(N\), we get the result of formula(1).
Expected Value and Convergence
Another question is, in the above question, how do we prove \(\left\langle F^{N}\right\rangle = F\ =\ \int_a^b{f\left( x \right) dx}\) , wo first introducte a Theorem
Law of Large Numbers
Let \(X_1, X_2, \dots\) be i.i.d(independent and identically distributed) with \(E[X_i] = \mu \in R\), \(Var(X_i) = \sigma^2 \in (0, \infty)\) , if, \(\bar{X}_{n}=\frac{1}{n} \sum_{i=1}^{n} X_{i}\) then, \(\bar{X}_{n} \rightarrow \mu\) in \(L^2\) .
we can get a result according to LLN :
and there is another problem is:
Therefore,
Multidimensional Integration
Monte Carlo integration can be generalized to use random variables drawn from arbitrary PDFs and to compute multidimensional integrals, such as:
with the following modification to Equation (1):
It is similarly easy to show that this generalized estimator also has the correct expected value:
In addition to the convergence rate, a secondary benefit ofMonte Carlo integration over traditional numerical integration techniques is the ease of extending it to multiple dimensions. Deterministic quadrature techniques require using \(N^d\) samples for a d-dimensional integral. In contrast,Monte Carlo techniques provide the freedom of choosing any arbitrary number of samples. That means, we don't need to calculate every d-dimensional cube very clearly.
Sources of Variance
For the Variance of The Basic Estimator of Monte Carlo integration, Since the samples in Monte Carlo Method are independent, using Equation the variance of \(\left\langle F^{N}\right\rangle\) can be simplified to:
and hence:
where \(Y_i = f(X_i) / pdf(X_i)\) and \(Y\) represents the evaluation of any specific \(Y_i\) , This derivation proves that the standard deviation converges with \(O(\sqrt N)\) . Moreover, this expression shows that by reducing the variance of each \(Y_i\) we can reducet he overall variance of \(\left\langle F^{N}\right\rangle\).
Variance Reduction
Earlier we calculated the variance of the Monte Carlo method to calculate the integral. This variance comes from the difference between the probability density function(PDF) that the sample conforms to and the integral function we seek. From the perspective of mathematical expectations, Monte Carlo integration can converge to traditional numerical integration, and the variance reflects the volatility of the sample. This means that if the sampling process is more similar to the integrand, the smaller the variance.
Importance Sampling
To demonstrate the effect of importance sampling, consider a PDF which is exactly proportional to the function being integrated, \(pdf(x) = cf(x)\) for some normalization constant \(c\). Since \(c\) is a constant, if we apply this PDF to theMonte Carlo estimator in Equation(3) , each sample \(X_i\) would have the same value.
Since the PDF must integrate to one, it is easy to derive the value of \(c\):
However, \(C\) is actually what we want to know, so, This best case is therefore not a realistic situation.
and we could use a figure to express the importance between the \(pdf(x)\) and \(f(x)\)
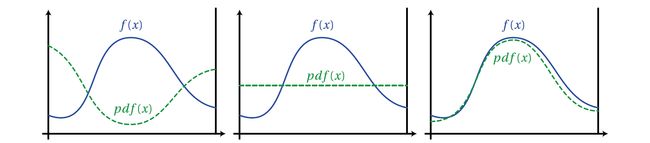
Comparison of three probability density functions. The PDF on the right provides variance reduction over the uniform PDF in the center. However, using the PDF on the left would significantly increase variance over simple uniform sampling. This is also easy to explain. For example, in the figure on the left, the probability of the distribution of \(X_i\) obtained by using the density function \(pdf(x)\) at both ends is greater than the probability of being distributed in the middle.
Importance Sampling Complex Functions
Most of the time, the integrand \(f (x)\) is very complicated, and we cannot guess its full behavior ahead of time. However, we may know something about its general structure. For instance, the integrand function \(f (x)\) may in fact be the combination of more than one function, e.g., \(f(x) = g(x)h(x)\) . In these situations, it may not be possible to create a PDF exactly proportional to \(f (x)\), but, if we know one of the functions in advance, we may be able to construct a PDF proportional to a portion of \(f (x)\), e.g., \(pdf_g (x) \propto g (x)\). In this situation, the Monte Carlo estimator simplifies to:
The above is a method to simplify the integration function \(f\). In addition, the operation of \(f\) can also be operated by polynomials, for example:Control variates is another variance-reduction technique which relies on some prior knowledge of the behavior of \(f\) . The idea behind control variates is to find a function g which can be analytically integrated and subtract it from the integral of \(f\):
We can then applyMonte Carlo integration to the modified integrand \(f (x)-g (x)\):
The ultimate goal of sampling in different ways is to make the variance of the Monte Carlo method small enough, In order to achieve this, we can operate in addition to the probability density function used for sampling, and also the sampling interval. Stratified Sampling is the principle used.
Stratified Sampling
Stratified sampling works by splitting up the original integral into a sum of integrals over sub-domains. In its simplest form, stratified sampling divides the domain \([a,b]\) into \(N\) sub-domains (or interval) and places a random sample within each of these intervals. If using a uniform PDF, with \(\xi _i\in \left[ 0,1 \right)\) , this can be expressed as:
This method changes the sampling interval on the basis of the basic Monte Carlo method to make the sampling more uniform. The probability density function of the sampling used in each interval is still uniformly distributed.
Most of the time, stratification can be added by simply replacing a canonical random number \(\xi _i\in \left[ 0,1 \right)\) with a sequence of stratified random numbers in the same range \(\xi _{i}^{N}=\frac{i+\xi _i}{N}\).
Comparison to Deterministic Quadrature
Stratified sampling incorporates ideas from deterministic quadrature, while still retaining the statistical properties ofMonte Carlo integration. It is informative to compare Equation 10 to a simple Riemann summation of the integral:
The Stratified samplingprocess can also be seen as Monte Carlo integration for each interval.
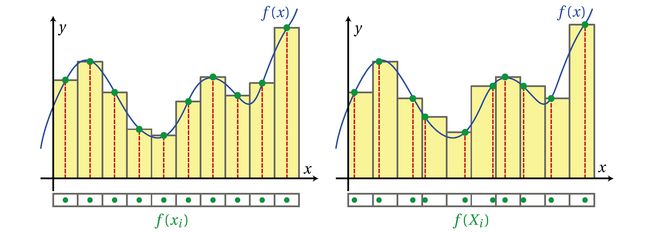
Deterministic quadrature techniques such as a Riemann summation (left) sample the function at regular intervals. Conceptually, stratifiedMonte Carlo integration (right) performs a very similar summation, but instead evaluates the function at a random location within each of the strata.