基于opencv和Tensorflow的实时手势识别(2)
在第(1)个博客中,我们搭建了能够录制、并保存手势的python代码。我录制了几个动作如下:


本节,利用录制的数据搭建一个简单的网络进行训练和测试。先不用考虑和上一个代码进行融合,那么本节的代码就变得简单的多。
(1)分析:
输入的图片大小是200*200
这里我们采用网络的架构如下:

**注: 在tensorflow中tf.nn.conv2d()中padding的参数有两种“SAME”和“VALID”:
使用“SAME”计算输入大小公式为:w := w/s (其中w为输入大小,s为步长)
使用“VALID”:w := {(w-F+1)/s}向上去整。 其中F为卷积核大小.**
下面给出实现代码:
import os
import numpy as np
import tensorflow as tf
from sklearn import model_selection, utils
from PIL import Image
import random
# 首先要读取图片信息并导入。
PATH = './img' # 所有的手势图片都放在里面
img_rows = 200
imgs_cols = 200
img_channels = 1
batch_size = 32
nb_classes = 5 # 类别
def modlist(path):
# 列出path里面所有文件信息
listing = os.listdir(path)
retlist = []
for name in listing:
if name.startwoth('.'):
continue
retlist.ppend(name)
return retlist
def Initializer():
# 初始化数据,产生训练测试数据和标签
imlist = modlist(PATH)
total_images = len(imlist) # 样本数量
immatrix = np.array([np.array(Image.open(PATH+'/'+image).convert('L')).flatten() for image in imlist], dtype='float32')
# 注 PIL 中图像共有9中模式 模式“L”为灰色图像 0黑 255白
# 转换公式 L = R * 299/1000 + G * 587/1000+ B * 114/1000
# 开始创建标签
label = np.ones((total_images, ), dtype=int)
samples_per_class = total_images / nb_classes # 每类样本的数量,(由于录制的时候录制的一样多,这里可以这样写,如果不一样多,标签就需要根据文件名来进行获取)
s = 0
r = samples_per_class
# 开始赋予标签(01234)
for index in range(nb_classes):
# 0-300: 0
# 301-601:1
#...
label[int(s):int(r)] = index
s = r
r = s + samples_per_class
data, label = utils.shuffle(immatrix, label, randomstate=2)
X_train, X_test, y_train, y_test = model_selection.train_test_split(data, label, test_size=0.2, random_state=4)
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, img_channels) # tensorflow的图像格式为[batch, W, H, C]
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, img_channels) # tensorflow的图像格式为[batch, W, H, C]
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
return X_train, X_test, y_train, y_test
def get_batch(X, y, batch_size):
# tensorflow 利用batch的思想来加快训练速度
data = []
label = []
m = X.shape[0]
for _ in range(batch_size):
index = random.randrange(m) # 随机选择一个整数
data.append(X[index])
tmp = np.zeros(NUM_LABELS, dtype=np.float32)
tmp[y[index]] = 1.0
label.append(tmp)
return np.array(data), np.array(label) # 输出为ndarray
# 测试数据
# a, b, c, d = Initializer()
# print(a.shape) # 1204*200*200*1 每一行一个样本 (训练样本)
# print(b.shape) # 301*200*200*1
# print(c)
# print(d)注:
该方法中是首先将所有图片读取出来,放一个矩阵。显然对于数据量大的,该方法不合适。最佳的方法是首先将图片制作成TFrecord格式,然后在读取。【后面我们会补充一节,tensorflow读取以及存储方式等】
接下来开始搭建网络:
INPUT_NODE = img_rows * img_cols
OUTPUT_NODE = 5
Image_size = 200
NUM_LABELS = 5
# 第一层卷积层的尺寸和深度
CONV1_DEEP = 32
CONV1_SIZE= 5
# 第二层卷积层的尺寸和深度
CONV2_DEEP = 64
CONV2_SIZE= 3
# 第一层卷积层的尺寸和深度
CONV3_DEEP = 64
CONV3_SIZE= 5
# 第二层卷积层的尺寸和深度
CONV4_DEEP = 64
CONV4_SIZE= 5
FC_SIZE1 = 512
FC_SIZE2 = 128
# 训练用参数
REGULARIZATION_RATE = 0.001
TRAINING_STEPS = 30000
MODEL_SAVE_PATH = './model'
MODEL_NAME = 'model.ckpt'
def get_batch(X, y, batch_size):
data = []
label = []
m = X.shape[0]
for _ in range(batch_size):
index = random.randrange(m)
data.append(X[index])
tmp = np.zeros(NUM_LABELS, dtype=np.float32)
tmp[y[index]] = 1.0
label.append(tmp)
return np.array(data), np.array(label)
# 定义前向卷积 添加:dropout 训练有 测试没有
def inference(input_tensor, train, regularizer):
with tf.name_scope('layer1-conv1'):
conv1_weights = tf.get_variable("weight", [CONV1_SIZE, CONV1_SIZE, img_channels, CONV1_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv1_biases = tf.get_variable("bias", [CONV1_DEEP], initializer=tf.constant_initializer(0.0))
conv1 = tf.nn.conv2d(input_tensor, conv1_weights, strides=[1, 1, 1, 1], padding="VALID") # 196*196*32
relu1 = tf.nn.relu(tf.nn.bias_add(conv1, conv1_biases))
with tf.name_scope('layer2-pool1'):
pool1 = tf.nn.max_pool(relu1, ksize=[1,2,2,1], strides=[1, 2, 2, 1], padding="SAME") # 98*98*32
with tf.variable_scope('layer3-conv2'):
conv2_weight = tf.get_variable("weight", [CONV2_SIZE, CONV2_SIZE, CONV1_DEEP, CONV2_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv2_biases = tf.get_variable('bias', [CONV2_DEEP], initializer=tf.constant_initializer(0.0))
conv2 = tf.nn.conv2d(pool1, conv2_weight, strides=[1,1,1,1], padding="VALID") # 96*96*64
relu2 = tf.nn.relu(tf.nn.bias_add(conv2, conv2_biases))
with tf.name_scope('layer4-pool2'):
pool2 = tf.nn.max_pool(relu2, ksize=[1,2,2,1], strides=[1,2,2,1], padding="SAME") # 48*48*64
with tf.variable_scope('layer5-conv3'):
conv3_weight = tf.get_variable("weight", [CONV3_SIZE, CONV3_SIZE, CONV2_DEEP, CONV3_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv3_biases = tf.get_variable('bias', [CONV3_DEEP], initializer=tf.constant_initializer(0.0))
conv3 = tf.nn.conv2d(pool2, conv3_weight, strides=[1,1,1,1], padding="VALID") # 44*44*64
relu3 = tf.nn.relu(tf.nn.bias_add(conv3, conv3_biases))
with tf.name_scope('layer6-pool3'):
pool3 = tf.nn.max_pool(relu3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME") # 22*22*64
with tf.variable_scope('layer7-conv4'):
conv4_weight = tf.get_variable("weight", [CONV4_SIZE, CONV4_SIZE, CONV3_DEEP, CONV4_DEEP],
initializer=tf.truncated_normal_initializer(stddev=0.1))
conv4_biases = tf.get_variable('bias', [CONV4_DEEP], initializer=tf.constant_initializer(0.0))
conv4 = tf.nn.conv2d(pool3, conv4_weight, strides=[1, 1, 1, 1], padding="VALID") # 18*18*64
relu4 = tf.nn.relu(tf.nn.bias_add(conv4, conv4_biases))
with tf.name_scope('layer8-pool4'):
pool4 = tf.nn.max_pool(relu4, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME") # 9*9*64
# 然后将第8层的输出变为第9层输入的格式。 后面全连接层需要输入的是向量 将矩阵拉成一个向量
pool_shape = pool4.get_shape().as_list()
# pool_shape[0]为一个batch中数据个数
nodes = pool_shape[1] * pool_shape[2] * pool_shape[3]
reshaped = tf.reshape(pool4, [pool_shape[0], nodes])
with tf.variable_scope('layer9-fc1'):
fc1_weights = tf.get_variable("weight", [nodes, FC_SIZE1],
initializer=tf.truncated_normal_initializer(stddev=0.1))
# 只有全连接层加入正则化
if regularizer != None:
tf.add_to_collection('loss', regularizer(fc1_weights))
fc1_biases = tf.get_variable('bias', [FC_SIZE1], initializer=tf.constant_initializer(0.1))
fc1 = tf.nn.relu(tf.matmul(reshaped, fc1_weights) + fc1_biases)
if train:
fc1 = tf.nn.dropout(fc1, 0.5)
with tf.variable_scope('layer10-fc2'):
fc2_weights = tf.get_variable("weight", [FC_SIZE1, FC_SIZE2],
initializer=tf.truncated_normal_initializer(stddev=0.1))
# 只有全连接层加入正则化
if regularizer != None:
tf.add_to_collection('loss', regularizer(fc2_weights))
fc2_biases = tf.get_variable('bias', [FC_SIZE2], initializer=tf.constant_initializer(0.1))
fc2 = tf.nn.relu(tf.matmul(fc1, fc2_weights) + fc2_biases)
if train:
fc2 = tf.nn.dropout(fc2, 0.5)
with tf.variable_scope('layer11-fc3'):
fc3_weights = tf.get_variable("weight", [FC_SIZE2, NUM_LABELS],
initializer=tf.truncated_normal_initializer(stddev=0.1))
# 只有全连接层加入正则化
if regularizer != None:
tf.add_to_collection('losses', regularizer(fc3_weights))
fc3_biases = tf.get_variable('bias', [NUM_LABELS], initializer=tf.constant_initializer(0.1))
logit = tf.matmul(fc2, fc3_weights) + fc3_biases
return logit # 注 : 这里没有经过softmax,后面在计算cross_entropy时候利用内置的函数会计算。开始训练
def train(X_train, y_train):
x = tf.placeholder(tf.float32, [batch_size, img_rows, img_cols, img_channels], name='x-input')
y = tf.placeholder(tf.float32, [batch_size, OUTPUT_NODE], name='y-input')
# 正则化
regularizer = tf.contrib.layers.l2_regularizer(REGULARIZATION_RATE)
# 前向传播
y_ = inference(x, train=True, regularizer=regularizer) # 预测值
global_step = tf.Variable(0, trainable=False) # 不可训练
#定义损失函数
# 滑动平均
# variable_averages = tf.train.ExponentialMovingAverage(MOVING_AAVERAGE_DECAY, global_step)
# variable_averages_op = variable_averages.apply(tf.trainable_variables())
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=tf.arg_max(y, 1), logits=y_) #
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection('losses')) # 计算总loss
# learninig_rate = tf.train.exponential_decay(LEARNING_RATE_BASE, global_step, 1204//batch_szie, LEARNING_RATE_DECAY)
train_step = tf.train.GradientDescentOptimizer(0.0005).minimize(loss, global_step=global_step)
# with tf.control_dependencies([train_step, variable_averages_op]):
# train_op = tf.no_op(name='train')
# train_op = tf.group(train_step, variable_averages_op)
# 保存模型
saver = tf.train.Saver()
pointer = 0
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
for i in range(TRAINING_STEPS):
xs, ys = get_batch(X_train, y_train, batch_size=batch_size)
# xs, ys = get_next_batch(X_train, y_train, batch_size=batch_szie)
# ys = tf.reshape(tf.one_hot(ys, depth=5), [batch_szie, OUTPUT_NODE])
_, loss_value, step = sess.run([train_step, loss, global_step], feed_dict={x: xs, y: ys})
print("----------------------", i, " : ", loss_value, "-------------------------------")
if step % 1000 == 0:
print("After %d training step(s), loss on training batch is %g." % (step, loss_value))
saver.save(sess, os.path.join(MODEL_SAVE_PATH, MODEL_NAME), global_step=global_step) # 保存模型。注:
(1) tf.nn.sparse_softmax_cross_entropy_with_logits()把softmax和cross entropy放到一个函数里计算,就是为了提高运算速度,并且计算出来的是“稀疏的”。【在传入参数时,必须要指明传入是哪一个 (labels=, logits=)】
首先看输入logits,它的shape是[batch_size, num_classes] ,一般来讲,就是神经网络最后一层的输入z。
另外一个输入是labels,它的shape也是[batch_size, 1],就是我们神经网络期望的输出。并且是一维的,也就是没有one-hot的
(2) tf.nn.softmax_cross_entropy_with_logits()
与(1)的区别是 labels 传入的是one-hot向量
(3)在tf.Session() 中一定不要在定义“op操作”,否则每次执行的时候,都会给Graph中加上一个节点,导致越来越慢,最终程序崩溃。
(4) sess.run中feeddict进去的都是ndarray,而不是tensor
测试:
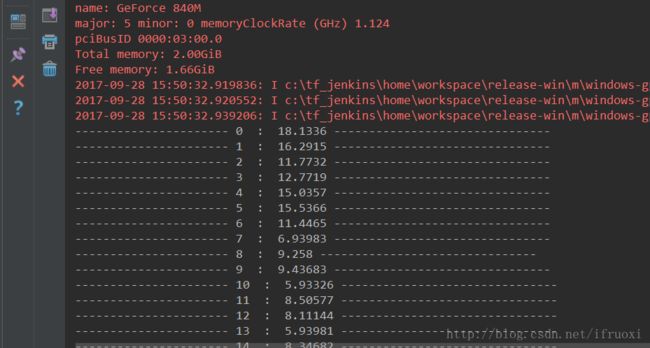
刚开始loss下降还是很快的,但是到后面loss稳定在1左右下不去。应该是 参数 没调好。调参是一个“大工程”,这里就不详述了。
这里没有给出测试的代码,下一博客会给出,并进行代码融合。