网易HubbleData之web端js-sdk数据采集库讲解
背景
网易HubbleData是一个洞察用户行为的数据分析系统,提供一套完整的数据解决方案。公司内部的诸如考拉、易信、LOFTER、美学、漫画等几十款产品都已接入使用。
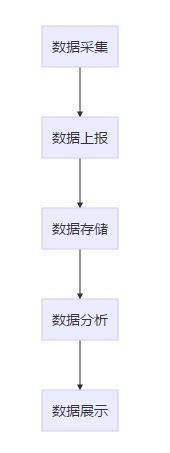
平台工作流程如下:
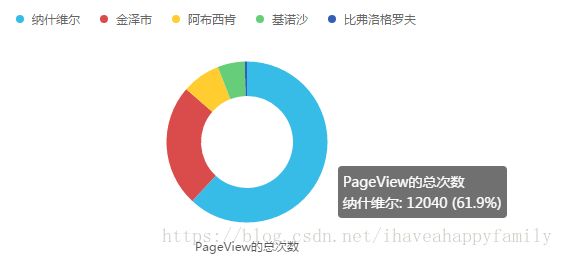
下图展示了平台的一些应用:
(1) 事件分析结果
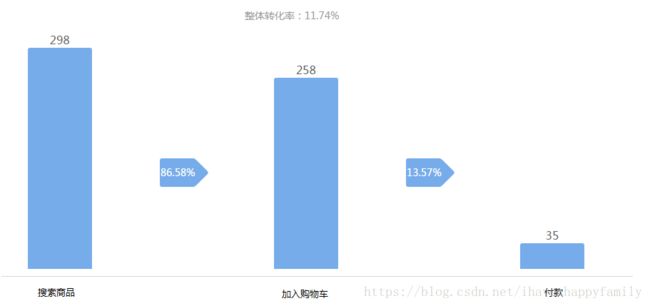
(2) 漏斗转化
(3) 用户路径分析

(4) 用户分群构建
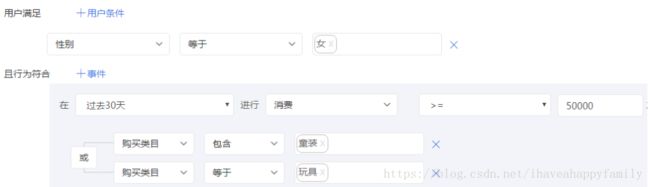
这些应用围绕着用户行为以及用户属性分析数据。
讲解
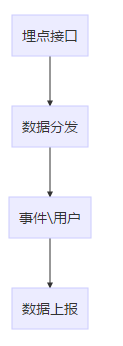
web端sdk采用手动代码埋点的方案,提供事件和用户数据模型构建、埋点接口、数据上报等,整体架构如下:
事件和用户属性
在客户端采集用户信息时,sdk提供了对应接口,用户需调用接口并设置需采集的信息。接口分为两类,一类设置用户行为信息,一类设置用户属性信息。这么设计出于几点考虑:
1. 数据模型分为事件和用户属性,接口层区分开有利于用户理解和正确使用;
2. 便于数据分发事件和用户属性信息;
分别如下:
事件行为
DATracker.track('buy', {price: '¥100'});用户属性
DATracker.people.set({name:'李思思'});用户id和设备id
HubbleData平台用户分为两类:匿名用户和真实用户。匿名用户指的是sdk内部自动依据某个算法生成的唯一id, 且只生成一次,同时它也是设备id; 真实用户指的是用户埋点设置下去的网站用户id。
在设计匿名用户初始化时,考虑到客户端浏览器我们无法拿到设备唯一信息,也就无法跟APP sdk一样方式生成该id,所以我们认为一个浏览器就是一个设备,依据算法生成且只生成一次唯一id,保存到客户端本地。
至于真实用户,sdk提供了API,调用后保存到本地:
DATracker.login('[email protected]');设计到这里,sdk也应该提供注册接口,这个接口的目的,就是把原先的用户id替换为新的用户id,包含了设置真实用户id功能。但我们并没有提供,出于几点考虑:
1. 调用注册接口,无非只是将新用户id传入,APIlogin已满足功能;
2. 减少一个API,也减轻用户理解和使用成本;
内部实现参考如下:
DATracker.prototype.login = function(user_id) {
// 内部实现注册
this.signup(user_id);
this.track('da_u_login')
}PV
网站统计一般有PV指标,反应出页面访问量。设计该功能时,sdk提供了两个方案供用户选择:
1. 默认情况下,sdk内部自动触发PV事件;
2. 用户调用API实现,且需关闭自动触发PV事件开关;
PV事件是产品方非常在意的指标,自动触发的设计原因:
1. 为了减轻用户使用负担;
2. 也是为了防止用户忘记调用API,导致没有PV事件;
设计自动触发带来了一个问题,因为是内部实现,无法给PV设置自定义属性,考虑到这点,sdk提供了loaded这个钩子函数,该函数执行周期为sdk初始化结束后,所有事件发送前。我们在这个钩子函数回调里,设置PV的自定义属性。
如下使用:
//sdk初始化结束,执行该方法
var beforeFn = function(datracker) {
//datracker 为sdk实例对象
//pageview_attributes, pageview事件的自定义事件属性
datracker.pageview_attributes = {
test: '12344'
};
};
DATracker.init('8888',{ loaded: beforeFn});当然,PV事件自动触发,也引出了单页面技术实现的网站PV问题,这点sdk内部采用监听事件来实现PV触发,sdk支持 hash 和 history两种形式技术的监听,具体实现有点复杂,不再诉说。
事件session
为了进一步分析某个用户的事件行为,sdk支持了session事件,在Hubble平台上,我们能够清晰的查看某个用户一段时间内的操作轨迹。设计该功能时,我们有几个点需要考虑:
1. 保证所有行为事件都在某个sesion段内;
2. 设计session的开始时间段和结束时间段;
自然,要保证所有行为事件都在某个session内,首先要开启一段session,但是开启一段session分为几点:
1. 用户首次进入产品,开启一段新session;
2. 用户session超时,关闭原先的session,重新开启一段新session;
3. 当由第三方进入产品时,立即关闭现在的session,重新开启一段新session;
判断是否首次进入,只需判断本地是否存在设备id即可;
session超时,在一个时间段内(默认设计30分钟),若用户未触发行为事件,则认为超时;
第三方进入产品,判断referrer的domain是否跟产品域名一致;
当用户触发事件行为时,sdk只需判断当前会话是否结束,这样就能保证所有行为事件都在某个sesion段内;
数据上报
当前sdk实现方案,我们支持ajax、script、img三种方式实现,主要有几点问题以及解决方案:
1. 去除缓存,我们采用添加时间戳参数;
2. ajax跨域问题,服务端放开限制;
3. 当低端浏览器不支持ajax跨域时,sdk自动降级采用script请求;
4. 上报数据各个字段过长,进行预处理解决;
考虑到webd端的实时性, web端sdk当前没有设计失败后重发或者下次进入后继续发未发送成功的事件机制。
sdk引入
sdk引入需分两个维度考虑:页面加载方式和升级。
页面加载方式 –
A. 异步方式:
设计sdk加载方式的初衷,有个很大的考虑,就是尽量减轻对产品的影响,异步方式就是一个较好的设计方案。但是该方式需解决几点问题:
1. 保证sdk文件未加载完,此时用户调用API是能够正确执行;
2. 保证sdk文件加载完成后,之前用户调用的API能够真正执行;
3. 基于1、2两点,sdk初始化设计方案复杂度升高;
解决思路很清晰:
首先我们需要预定义API方法,这样用户调用API就不会报错,同时将调用的API保存到临时队列中;
然后sdk加载完初始化后,循环执行队列。
B. 同步方式:
有些场景下,比如用户启动了打通APP和H5的功能,这时候为了保证兼容,必须保证sdk首次加载下拉,这时候就需要使用该方式。
结尾
本文介绍了Hubble平台的背景,讲解了js-sdk设计一些API的思路、概念、遇到的问题和解决方案。
当然Hubble的js-sdk并非仅仅限于这些功能模块,比如 jsbridge、热力图、渠道推广、自然来源、abtest等等,以及其它降低用户使用成本的辅助API。
如有兴趣,可咨询我的泡泡:[email protected] ; 或者我们的产品经理:[email protected]。