深入理解iOS GPU加速框架Metal及MPS
iOS的Metal框架是一个类似OpenGL的框架,通过编写shaders(类c代码)运行在GPU上,利用GPU的高并行能力执行并行操作,比如图像处理,卷积神经网络。而MPS就是一套基于Metal框架的库,用户不需要理解Metal的细节,直接调用这些库即可使用高性能处理能力。同时针对卷积神经网络,官方已经提供了MPSCnn库,开发人员可以直接使用该库组件神经网络即可以在移动端iPhone执行神经网络模型,比如图片识别,速度是杠杠的,很多年前,作者曾经利用该库和自己自定义的一些算子实现了实时图片风格化,人物自动抠图等功能,在iPhone上FPS能达到50fps,可见这性能有多好。接下来我们来详细分析下Metal框架及MPS。
OpenGLES
由于Metal和OpenGLES类似,我们先介绍大家更加熟悉的OpenGL

这个图里开发者需要重点了解3个模块

-
顶点着色器
开发者用来自定义顶点信息(坐标和颜色),是一段代码。Vertex shader就是调整顶点信息,比如透视图变换,Camera位置调整。有多少个顶点就会调用多少次,如果顶点较少,这里执行较慢的话,性能影响不大。
-
栅格化
- 简单来说,比如你告诉GL我想画条线,然后告诉它线的端点坐标是(0,0)和(0,100),那么GL自动脑补出中间100个点的坐标,这个过程就叫栅格化(光栅化),脑补的方法叫线性差值.
- 复杂点,现在我要画个三角形,给他三个顶点的坐标,它会计算这个三角形里面的所有像素坐标。
- 再复杂点,不仅仅给顶点坐标,还告诉他(0, 0)坐标点是白色,(0,100)点是黑色,那么栅格化就自动计算出中间100个点每个点的颜色,自动做过渡的效果, 这个计算方法还是线性差值。
-
片段着色器
开发者根据栅格化出来的具体位置信息用来绘制颜色,也是一段代码。由于是并行处理,这里的逻辑尽量保持并发友好。Frage shader就是栅格化之后,根据输入的栅格化坐标/颜色信息自己再加工处理输出一个颜色,比如光照,雾化处理等等。每个片段(像素)会执行一次,这里执行较慢的话,性能影响比较大(线程不够用的情况下)。
Metal
Metal和Opengl类似,但是同时Metal进一步扩展并支持了更多GPU驱动各种命令,所以尽管iOS侧也可以使用OpenGl, 但是官方还是推荐大家使用Metal, 且Metal由于更丰富的接口和功能,利用Metal可更加方便高效的进行非传统的图形数据处理。
基本元素
MTLDevice
GPU Device,Metal 中提供了 MTLDevice 的接口,代表了 GPU。
device = MTLCreateSystemDefaultDevice()MTLCommandQueue
确定GPU设备后我们需要一个渲染队列 MTLCommandQueue,该队列是单一队列,确保了指令能够顺序执行,里面保存的是将要渲染的指令MTLCommandBuffer,这是个线程安全的队列,可以支持多个 CommandBuffer 同时编码。
device.makeCommandQueue()MTLCommandBuffer
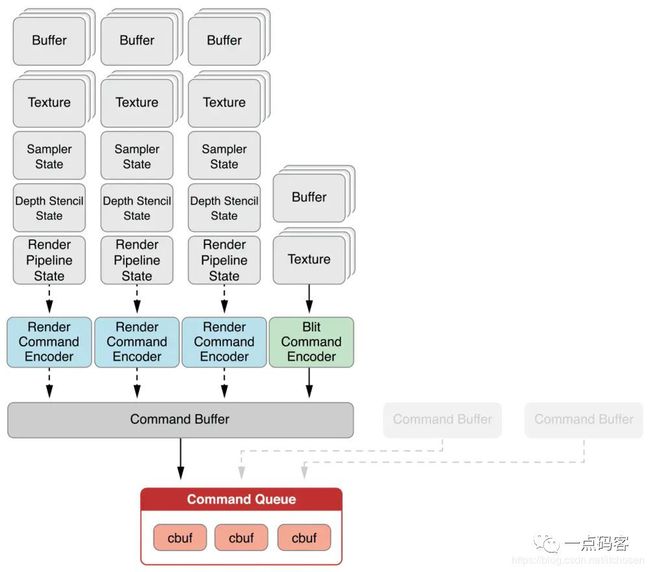
commandQueue.makeCommandBuffer()MTLCommandEncoder
目前Metal支持4种Encoder
-
MTLRenderCommandEncoder(2个shader)
-
这种是最常见的,就是图形绘制命令。会包含两个shader, 定点shader和片段shader
-
MTLComputeCommandEncoder(1个shader)
-
这种就是存储并行计算命令,这种只有computer shader
-
MTLBlitCommandEncoder(0个shader)
-
这是一种简单数据处理命令,比如图片缩放,旋转角度等简单的数据处理复制,这个其实在普通应用也有见过的, 比如Android系统通过底层dma操作实现blit加速操作,这种操作不需要shader。

这三种的创建函数

PipeLineState
PipeLineState包含了执行的一些状态信息,比如执行的函数,线程信息(maxTotalThreadsPerThreadgroup)。不同的Encoder,有不同的PipeLineState,
-
MTLRenderPipelineState
-
MTLComputePipelineState
MTLLibrary
我们知道前面的各种Encoder是可能需各种shader,shader就是代码,因而需要给他们指定代码函数, 这些Function都是通过MTLLibrary加载的。通过指定shader程序库文件创建
device.makeLibrary(filepath: path)MTLFunction
指定shader文件里的函数并创建MTLFunction
library.makeFunction(name: name)图像处理示例
Texture纹理坐标是2d坐标,顶点坐标是3维(z为0时2d),对应模型的坐标,一个顶点坐标对应一个纹理坐标。

drawIndexedPrimitives(glDrawArray)相当于加载内置的vertex/fragment shader程序。如果是更复杂的绘制(比如绘制3d,添加各种效果等等),需要通过自定义的shader来处理,主要是修改vertexFunction, fragmentFunction及给这些函数传参数
shader函数赋值


上图的vertex shader是直接获取Buffer里的数据,并没有做任何改动。vertexFunc的返回数据结构可自定义,但是fragmentFunc的返回值就是颜色信息。上面的Vertex通过指定了buffer的index来获取数据, 还是有些耦合的,可以通过更灵活的方式来定义,比如attribute标识,然后只要在Swift侧通过VertexDescriptor来定义这些attribute的属性,即可绑定这些参数的来源

Instance-norm示例
了解过深度学习应该都了解instance-norm,这个算子的核心工作就是求平均值,然后算方差。并行求平均值可以分解为多个小范围求和,然后再将这些和相加得到总值,然后再除上总量即可获得平均值。这个算法如果利用图像栅格化后每个片段着色器来执行求和是不好处理的,因为并行的执行体间没法共享变量,且由于并行的执行单元并没有严格的顺序关系,谁来负责最后的总值计算也是一个很大的问题。Metal通过compute shader可以很好地完成这个任务(OpenGL 4.3也引入了Compute Shader )。核心是线程组内的线程间内存共享和同步机制,下面我们来看实例,由于需要共享数据,只能有一组threadGroup。


所以上面的第一个线程负责1, 257, 1025等像素的处理,第二线程负责2, 258, 1026等像素的处理,最后会汇总为256个和。最后选一个线程继续汇总为总和即可,当然可以再并行,比如256->32->1这种结果。

这里的thread等属性只适合Compute Shader,不适合Render shader。
/**************************************************
* 本文来自CSDN博主"一点码客",喜欢请顶部点击关注
* 转载请标明出处:http://blog.csdn.net/itchosen
***************************************************/
如需实时查看更多更新文章,请关注公众号"一点码客",一起探索技术
