1、垃圾回收器的分类
(1)串行
单线程:垃圾回收发生的时候,其它线程都暂停
适用于堆内存较小的时候,适合个人电脑
(2)吞吐量优先
多线程
适合于堆内存较大,需要多核CPU
让单位时间内STW的时间最短
(3)响应时间优先
多线程
适合于堆内存较大,需要多核CPU
注重的是垃圾回收时STW的时间最短
2、串行垃圾回收器

Serial:工作在新生代,采用的是复制算法
SerialOld:工作在老年代,采用的是标记整理算法
垃圾回收的时候此线程不阻塞,其他线程都处于阻塞状态
3、吞吐量优先

UseParalleGC:Paralle是并行的意思,UseParalleGC工作在新生代,采用复制算法
UseParalleoldGC:工作在老年代,采用标记整理算法
只要打开一个,另外一个就默认开启
-XX:+UseAdaptiveSizePolicy:自动调整伊甸园区和幸存区的比例
-XX:+GCTimeRatio=ratio:1/(1+radio)垃圾处理的目标(radio默认为99)
-XX:MaxGCPauseMillis=ms:最大暂停(默认200ms)
-XX:ParallelGCThreads=n:垃圾处理线程的数量
4、响应时间优先
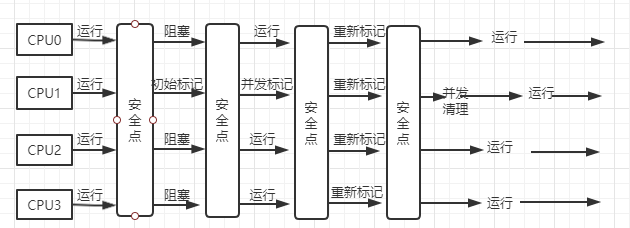
-XX:UseConcMarkSweepGC:工作在新生代
-XX:+UseParNewGC:工作在老年代
初始标记:标记根对象,较快
并发标记:不用STW,和用户线程并发执行
并发清理:和其他用户线程并发执行
5、G1(Garbage First,jdk9默认)
(1)适用场景
同时注重吞吐量和低延迟,默认的暂停目标是200ms
超大堆内存,会将堆划分为多个region
整体上是标记+整理算法,两个区域之间是复制算法
(2)垃圾回收阶段
Young Collection:对新生代的垃圾收集

每一个区域都可以单独作为伊甸园区、幸存区和老年代
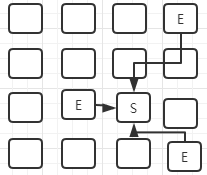
新生代垃圾回收:复制算法,会STW,将幸存的对象拷贝到幸存区:
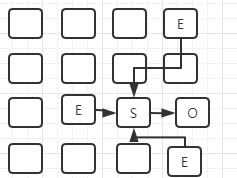
晋升到老年代:
Young Collection+Concurrent Mark:新生代的垃圾收集+并发标记(老年代垃圾超过阈值)
会进行初始标记(标记根对象)和并发标记(从根对象出发,标记其它的一些对象,老年代超过阈值触发)
Mixed Collection:混合收集(对新生代、老年代进行垃圾收集,规模较大)
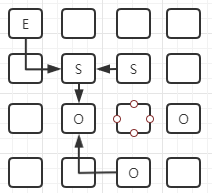
老年代采用的也是复制算法,G1根据最大暂停时间有选择地进行垃圾回收。达不到设置的最大暂停时间,会从老年代挑出回收价值最高的区域
6、Full GC

其中CMS和G1老年代内存不足,分两种情况,对于G1当老年代的内存超过阈值的时候就会触发并发标记和混合收集,如果回收的速度高于用户线程产生垃圾的速度的话,这个时候还处于并发垃圾收集的阶段,还不是Full GC。当垃圾回收的速度赶不上垃圾收集的速度,就会退化为串行的收集,触发Full GC
CMS是并发收集失败的时候才会触发Full GC
7、jdk8字符串去重
(1)优点和缺点
优点:节省大量代码
缺点:略微多占用了cpu时间,新生代回收时间略微增加
(2)原理
将所有新分配的字符串放入一个队列,当新生代回收的时候,G1并发检查是否有字符串重复,如果他们的值一样,就让他们引用同一个char数组(string本质是char数组)
注意:与string.intern不同,string.intern()关注的是字符串对象,而字符串去重关注的是char数组,在jvm内部使用了不同的字符串表
8、jik8并发标记卸载
所有对象经过并发标记后,就能知道哪些类不再被使用,当一个类加载器的所有类不再使用,则卸载它所加载的所有类
9、jdk8回收巨型对象
(1)定义
一个对象大于region的一半时,称之为巨型对象
(2)特征
G1不会对巨型对象进行拷贝
回收时被优先考虑
G1会跟踪老年代所有的incoming引用,这样老年代incoming引用为0的巨型对象就可以在新生代垃圾回收的时候处理掉