Raft源码分析(二) - Role转换
时光粒子源码
分布式一致性/分布式存储等开源技术探讨, GitHub:https://timequark.github.io/
-
Raft源码分析 - 关于
-
Raft源码分析(一) - State
-
Raft源码分析(二) - Role转换
先来看一下raft白皮书中的 role 角色转换图:
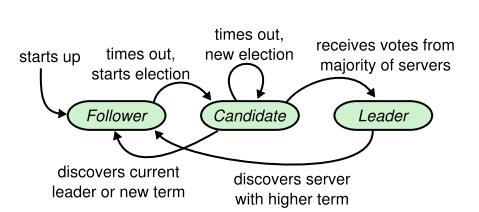
下面的是个人土制的转换图:

raft 中的 Role 角色共有三类
-
Leader
Leader的职能有:
(1)处理read/write请求
(2)存储 Log 数据
(3)向集群其它节点发送 heartbeat 心跳请求,确保集群通信正常
(4)向Follower发送Log Entry数据,完成 Replication 冗余
(5)跟踪Follower的数据复制状态
(6)Log Compation(raftos目前不完备)
(7)snapshot(raftos目前不完备)
Leader 会不停的向集群其它节点发送 heartbeat 心跳,且每个心跳请求都有一个 ID (int类型递增),如果收到过半节点的 append_entries_response,则重置 step_down_timer 定时器;如果没有收到过半节点的回应,累计次数超过 step_down_missed_heartbeats 次,step_down_timer 会被触发,Leader 退化为 Follower 。
-
Candidate
只用来做 election 选举。
首先,term + 1,voted_for 置为自身的 ID,给自己投1票,然后广播 request_vote 请求。收到过半 vote_granted 为 True 的 response 后,升级为 Leader。如果定时器触发前,没有赢得过半的投票,则直接转变成 Follower 角色。
下面小节会具体分析 request_vote 请求携带的参数。
-
Follower
接收来自 Leader 的 append_entries 请求、来自 Candidate 的 request_vote 请求。这里要注意以下几点:
(1)Follower.start 时, init_storage 方法只能第一次加载时才对 term 置 0,但每次都会重置 voted_for。
(2)on_receive_append_entries 只有在顺利通过 @validate_term、@validate_commit_index 验证时,才会重置 election_timer,否则就有退化为 Candidate 进行重新选举的可能。
(3)on_receive_request_vote 只有在没有投过票,并且来自 Candidate 的 last_log_term、last_log_index 有效时,才会回应 vote_granted 为 True。
(4)on_receive_request_vote 没有重置 election_timer 动作。因为作为 Follower 自身,并不知道此次选举是否会有新的 Leader 生成,只能通过有效的 on_receive_request_vote 才能感知 Leader 的存在。
Leader
state.py
class Leader(BaseRole):
"""Raft Leader
Upon election: send initial empty AppendEntries RPCs (heartbeat) to each server;
repeat during idle periods to prevent election timeouts
— If command received from client: append entry to local log, respond after entry applied to state machine
- If last log index ≥ next_index for a follower: send AppendEntries RPC with log entries starting at next_index
— If successful: update next_index and match_index for follower
— If AppendEntries fails because of log inconsistency: decrement next_index and retry
— If there exists an N such that N > commit_index, a majority of match_index[i] ≥ N,
and log[N].term == self term: set commit_index = N
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.heartbeat_timer = Timer(config.heartbeat_interval, self.heartbeat)
self.step_down_timer = Timer(
config.step_down_missed_heartbeats * config.heartbeat_interval,
self.state.to_follower
)
# Heartbeat 时自加1
self.request_id = 0
# 收到 append_entries_response 时,根据 request_id ,判定是否有过半 Follower 回应
self.response_map = {}
def start(self):
self.init_log()
# LIUHAO: Trigger leader call 'append_entries' automatically
self.heartbeat()
self.heartbeat_timer.start()
self.step_down_timer.start()
def stop(self):
self.heartbeat_timer.stop()
self.step_down_timer.stop()
# init_log 是在 start() 方法而不是 __init__ 方法中调用,
# Candidate 升级为 Leader 时,只有 next_index、match_index 会重新初始化,其它数据保持不变
def init_log(self):
# LIUHAO
# - Initiate next_index of each follower to leader's last_log_index+1. Leader will try to broadcast 'append_entries' command to each follower with lastest log data.
# If follower reply not 'success', next_index will descrease automatically.
# If follower reply 'success', leader will update 'match_index' to 'last_log_index' of follower.
# - 'self.state.cluster' doesn't include this node refer to register.py:register
self.log.next_index = {
follower: self.log.last_log_index + 1 for follower in self.state.cluster
}
# LIUHAO
# - Initiate match_index to 0. match_index will catch up to the 'next_index' of each server after leader broadcasting 'append_entries' commands and receives 'success' response
self.log.match_index = {
follower: 0 for follower in self.state.cluster
}
async def append_entries(self, destination=None):
"""AppendEntries RPC — replicate log entries / heartbeat
Args:
destination — destination id
Request params:
term — leader’s term
leader_id — so follower can redirect clients
prev_log_index — index of log entry immediately preceding new ones
prev_log_term — term of prev_log_index entry
commit_index — leader’s commit_index
entries[] — log entries to store (empty for heartbeat)
"""
# Send AppendEntries RPC to destination if specified or broadcast to everyone
# 支持 send 单点或 broadcast 广播消息
destination_list = [destination] if destination else self.state.cluster
for destination in destination_list:
data = {
'type': 'append_entries',
'term': self.storage.term,
'leader_id': self.id, # LIUHAO: It's just a leader_id. When a Follower receives 'append_entries' message, the Follower will update its Leader property.
'commit_index': self.log.commit_index,
'request_id': self.request_id
}
next_index = self.log.next_index[destination]
prev_index = next_index - 1
if self.log.last_log_index >= next_index:
# Follower 节点数据未同步时,这里仅仅只同步 1 个 entry
data['entries'] = [self.log[next_index]]
else:
# heartbeat 心跳,不携带数据
data['entries'] = []
# Follower 需要检查上一个 Log Entry 的 index、term 是否与 Leader 匹配,确保 Follower 数据的一致性
data.update({
'prev_log_index': prev_index,
'prev_log_term': self.log[prev_index]['term'] if self.log and prev_index else 0
})
asyncio.ensure_future(self.state.send(data, destination), loop=self.loop)
@validate_commit_index
@validate_term
def on_receive_append_entries_response(self, data):
sender_id = self.state.get_sender_id(data['sender'])
# Count all unqiue responses per particular heartbeat interval
# and step down via if leader doesn't get majority of responses for
# heartbeats
if data['request_id'] in self.response_map:
self.response_map[data['request_id']].add(sender_id)
if self.state.is_majority(len(self.response_map[data['request_id']]) + 1):
# 回应过半,重置 step_down_timer,删除 response_map 中 request_id 的请求记录
self.step_down_timer.reset()
del self.response_map[data['request_id']]
if not data['success']:
# LIUHAO: next_index is descreasing. Maybe in order to tolerant the follower to recover log data and catch up Leader
# next_index[follower] 自减 1,供下一次 append_entries 使用
self.log.next_index[sender_id] = max(self.log.next_index[sender_id] - 1, 1)
else:
# LIUHAO: Trace next_index, match_index for follower inside Leader.
# append_entries 成功时,
# next_index[follower_id] 更新为Follower的last_log_index+1,
# match_index[follower_id]更新为Follower的last_log_index
self.log.next_index[sender_id] = data['last_log_index'] + 1
self.log.match_index[sender_id] = data['last_log_index']
# 更新commit_index
self.update_commit_index()
# Send AppendEntries RPC to continue updating fast-forward log (data['success'] == False)
# or in case there are new entries to sync (data['success'] == data['updated'] == True)
if self.log.last_log_index >= self.log.next_index[sender_id]:
# LIUHAO: Continue to send data to the follower
# 继续向 Follower 同步数据
asyncio.ensure_future(self.append_entries(destination=sender_id), loop=self.loop)
def update_commit_index(self):
commited_on_majority = 0
# 在当前[commit_index+1, last_log_index+1)范围内遍历,Leader中的 index 已得到 match_index 半数以
# 上 Follower 回应,并且,log[index]['term'] 与最新 storage.term 相同时,更新 commit_index
for index in range(self.log.commit_index + 1, self.log.last_log_index + 1):
commited_count = len([
1 for follower in self.log.match_index
if self.log.match_index[follower] >= index
])
# If index is matched on at least half + self for current term — commit
# That may cause commit fails upon restart with stale logs
is_current_term = self.log[index]['term'] == self.storage.term
if self.state.is_majority(commited_count + 1) and is_current_term:
commited_on_majority = index
else:
break
if commited_on_majority > self.log.commit_index:
self.log.commit_index = commited_on_majority
# Write 接口
async def execute_command(self, command):
"""Write to log & send AppendEntries RPC"""
self.apply_future = asyncio.Future(loop=self.loop)
entry = self.log.write(self.storage.term, command)
asyncio.ensure_future(self.append_entries(), loop=self.loop)
Candidate
state.py
class Candidate(BaseRole):
"""Raft Candidate
— On conversion to candidate, start election:
— Increment self term
— Vote for self
— Reset election timer
— Send RequestVote RPCs to all other servers
— If votes received from majority of servers: become leader
— If AppendEntries RPC received from new leader: convert to follower
— If election timeout elapses: start new election
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# election 超时后,自动转变成 Follower
self.election_timer = Timer(self.election_interval, self.state.to_follower)
self.vote_count = 0
def start(self):
"""Increment current term, vote for herself & send vote requests"""
# 开始 election 时,term 自加 1,且给自己投一票
self.storage.update({
'term': self.storage.term + 1,
'voted_for': self.id
})
self.vote_count = 1
# 发送拉票消息
self.request_vote()
# 启动 election timer
self.election_timer.start()
def stop(self):
self.election_timer.stop()
def request_vote(self):
"""RequestVote RPC — gather votes
Arguments:
term — candidate’s term
candidate_id — candidate requesting vote
last_log_index — index of candidate’s last log entry
last_log_term — term of candidate’s last log entry
"""
data = {
'type': 'request_vote',
'term': self.storage.term,
'candidate_id': self.id,
'last_log_index': self.log.last_log_index,
'last_log_term': self.log.last_log_term
}
#
# 向集群中其它所有节点广播 request_vote 消息,不论其它节点的 Role 是 Leader、Folloer、还是 Candidate,
# 每个节点各自到什么时间,做什么事,
# 因此 BaseRole 中抽象了以下几个方法的空实现,来应对可能接收到的各中消息的可能:
# - on_receive_request_vote(self, data)
# - on_receive_request_vote_response(self, data)
# - on_receive_append_entries(self, data)
# - on_receive_append_entries_response(self, data)
#
self.state.broadcast(data)
@validate_term
def on_receive_request_vote_response(self, data):
"""Receives response for vote request.
If the vote was granted then check if we got majority and may become Leader
"""
if data.get('vote_granted'):
self.vote_count += 1
# 得到过半投票后,Candidate 切换成 Leader
if self.state.is_majority(self.vote_count):
self.state.to_leader()
@validate_term
def on_receive_append_entries(self, data):
"""If we discover a Leader with the same term — step down"""
# LIUHAO
# Confusion here. When 'storage.term' < data['term'], @validate_term will keep 'storage.term' update and change self to Follower.
# Then the code here will change self to Follower again. What I thought is that 'split vote' case may happen.
# This doesn't make any problem ??? . Whatever....
#
# 这里有个二次切换 Follower 的问题,情景如下:
# 集群中有两个以上的 Candidate 在选举,例如叫 A、B,且 A.term > B.term;
# 当A选举成功,A 成为 Leader,紧接着向 B 发送 append_entries 消息,Candidate B 在
# on_receive_append_entries 中 @validate_term 将 B.term := A.term,且切换成 Follower,
# 这里判断 B.term == A.term,会再次切换成 Follower
#
# 上面描述的情景是有一定概率出现的,由于 Follower 的 election_interval 的随机性,再加上网络状态良好的话,
# 所以,出现上面情景的概率不会高。
if self.storage.term == data['term']:
self.state.to_follower()
@staticmethod
def election_interval():
return random.uniform(*config.election_interval)
Candidate
state.py
class Candidate(BaseRole):
"""Raft Candidate
— On conversion to candidate, start election:
— Increment self term
— Vote for self
— Reset election timer
— Send RequestVote RPCs to all other servers
— If votes received from majority of servers: become leader
— If AppendEntries RPC received from new leader: convert to follower
— If election timeout elapses: start new election
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# election 超时后,自动转变成 Follower
self.election_timer = Timer(self.election_interval, self.state.to_follower)
self.vote_count = 0
def start(self):
"""Increment current term, vote for herself & send vote requests"""
# 开始 election 时,term 自加 1,且给自己投一票
self.storage.update({
'term': self.storage.term + 1,
'voted_for': self.id
})
self.vote_count = 1
# 发送拉票消息
self.request_vote()
# 启动 election timer
self.election_timer.start()
def stop(self):
self.election_timer.stop()
def request_vote(self):
"""RequestVote RPC — gather votes
Arguments:
term — candidate’s term
candidate_id — candidate requesting vote
last_log_index — index of candidate’s last log entry
last_log_term — term of candidate’s last log entry
"""
data = {
'type': 'request_vote',
'term': self.storage.term,
'candidate_id': self.id,
'last_log_index': self.log.last_log_index,
'last_log_term': self.log.last_log_term
}
#
# 向集群中其它所有节点广播 request_vote 消息,不论其它节点的 Role 是 Leader、Folloer、还是 Candidate,
# 每个节点各自到什么时间,做什么事,
# 因此 BaseRole 中抽象了以下几个方法的空实现,来应对可能接收到的各中消息的可能:
# - on_receive_request_vote(self, data)
# - on_receive_request_vote_response(self, data)
# - on_receive_append_entries(self, data)
# - on_receive_append_entries_response(self, data)
#
self.state.broadcast(data)
@validate_term
def on_receive_request_vote_response(self, data):
"""Receives response for vote request.
If the vote was granted then check if we got majority and may become Leader
"""
if data.get('vote_granted'):
self.vote_count += 1
# 得到过半投票后,Candidate 切换成 Leader
if self.state.is_majority(self.vote_count):
self.state.to_leader()
@validate_term
def on_receive_append_entries(self, data):
"""If we discover a Leader with the same term — step down"""
# LIUHAO
# Confusion here. When 'storage.term' < data['term'], @validate_term will keep 'storage.term' update and change self to Follower.
# Then the code here will change self to Follower again. What I thought is that 'split vote' case may happen.
# This doesn't make any problem ??? . Whatever....
#
# 这里有个二次切换 Follower 的问题,情景如下:
# 集群中有两个以上的 Candidate 在选举,例如叫 A、B,且 A.term > B.term;
# 当A选举成功,A 成为 Leader,紧接着向 B 发送 append_entries 消息,Candidate B 在
# on_receive_append_entries 中 @validate_term 将 B.term := A.term,且切换成 Follower,
# 这里判断 B.term == A.term,会再次切换成 Follower
#
# 上面描述的情景是有一定概率出现的,由于 Follower 的 election_interval 的随机性,再加上网络状态良好的话,
# 所以,出现上面情景的概率不会高。
if self.storage.term == data['term']:
self.state.to_follower()
@staticmethod
def election_interval():
return random.uniform(*config.election_interval)
Follower
state.py
class Follower(BaseRole):
"""Raft Follower
— Respond to RPCs from candidates and leaders
— If election timeout elapses without receiving AppendEntries RPC from current leader
or granting vote to candidate: convert to candidate
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 注意这里的 election_interval 是随机生成的,随机范围参照 config.py
self.election_timer = Timer(self.election_interval, self.start_election)
def start(self):
# 初始化 storage (term、voted_for)
self.init_storage()
self.election_timer.start()
def stop(self):
self.election_timer.stop()
def init_storage(self):
"""Set current term to zero upon initialization & voted_for to None"""
# 仅仅首次初始化为0,storage 文件生成后,这里逻辑全程不会再进入
if not self.storage.exists('term'):
self.storage.update({
'term': 0,
})
# 清空 voted_for
self.storage.update({
'voted_for': None
})
@staticmethod
def election_interval():
return random.uniform(*config.election_interval)
@validate_commit_index
@validate_term
def on_receive_append_entries(self, data):
# LIUHAO: Update 'leader_id' to 'leader' property of Class State!
# We can have a look at description in Class State. Like the following part:
#
# # if state is leader
# # if state is follower
# # if leader is not chosen yet
# leader = None
self.state.set_leader(data['leader_id'])
# Reply False if log doesn’t contain an entry at prev_log_index whose term matches prev_log_term
try:
prev_log_index = data['prev_log_index']
# 检查Leader侧提供的Follower的prev_log_index、Leader的term,与本地相比,是否有效
# 如果无效,则直接返回 False
# 注意:
# raft白皮书有提到,无效时,可以携带Follower的 last_log_index,给到 Leader 侧,这样做可以使
# Leader 侧快速定位 Follower 的 next_index,进而减少Leader侧无效的 append_entries 通信次数
if prev_log_index > self.log.last_log_index or (
prev_log_index and self.log[prev_log_index]['term'] != data['prev_log_term']
):
response = {
'type': 'append_entries_response',
'term': self.storage.term,
'success': False,
'request_id': data['request_id']
}
# 异步回应Leader
asyncio.ensure_future(self.state.send(response, data['sender']), loop=self.loop)
return
except IndexError:
pass
# If an existing entry conflicts with a new one (same index but different terms),
# delete the existing entry and all that follow it
# 将Leader发过来的entries数据,存至Log中 new_index 开始的位置
new_index = data['prev_log_index'] + 1
try:
# 有冲突时,直接擦除至尾部,向Leader看齐
if self.log[new_index]['term'] != data['term'] or (
self.log.last_log_index != prev_log_index
):
self.log.erase_from(new_index)
except IndexError:
pass
# LIUHAO: TODO
# 'log.write' will append entries to its tail. Should we reply Leader False message???
# It's always one entry for now
for entry in data['entries']:
self.log.write(entry['term'], entry['command'])
# Update commit index if necessary
# 注意这里的条件,Follower的commit_index 小于 Leader的commit_index时,才更新
# 问题:
# Follower的commit_index 大于 Leader的commit_index时,如何处理?
# 思考:
# 大于的情形有可能是 Follower 曾经是 Leader,commit_index 比较新 ,因为某些原因降级成 Follower。
# 但是,这种情形也不合理,因为 Leader 的 commit_index 只有收到过半Follower的 append_entries_response 后才会更新,
# 如此,Follower 的 commit_index 一定是小于 Leader 的 commit_index,直至 Leader 同步完最后一个 last_log_index
# 的 entry,Follower 的 commit_index 等于 Leader 的 commit_index(因为 Leader 的 update_commit_index 遍历范围
# [commit_index+1, last_log_index+1) 时 index 最大值为 last_log_index )。
if self.log.commit_index < data['commit_index']:
self.log.commit_index = min(data['commit_index'], self.log.last_log_index)
# Respond True since entry matching prev_log_index and prev_log_term was found
response = {
'type': 'append_entries_response',
'term': self.storage.term,
'success': True,
'last_log_index': self.log.last_log_index, # LIUHAO: Here, 'log.last_log_index' will be updated for that more than 1 entry be appended to the Log list
'request_id': data['request_id']
}
asyncio.ensure_future(self.state.send(response, data['sender']), loop=self.loop)
# 重置选举定时器
self.election_timer.reset()
@validate_term
def on_receive_request_vote(self, data):
# LIUAHO: Insure that Follower has not voted for any Candidate
if self.storage.voted_for is None and not data['type'].endswith('_response'):
# Candidates' log has to be up-to-date
# If the logs have last entries with different terms,
# then the log with the later term is more up-to-date. If the logs end with the same term,
# then whichever log is longer is more up-to-date.
if data['last_log_term'] != self.log.last_log_term:
up_to_date = data['last_log_term'] > self.log.last_log_term
else:
up_to_date = data['last_log_index'] >= self.log.last_log_index
if up_to_date:
self.storage.update({
'voted_for': data['candidate_id']
})
response = {
'type': 'request_vote_response',
'term': self.storage.term,
'vote_granted': up_to_date
}
asyncio.ensure_future(self.state.send(response, data['sender']), loop=self.loop)
def start_election(self):
self.state.to_candidate()
def leader_required(func):
@functools.wraps(func)
async def wrapped(cls, *args, **kwargs):
# 确保或等待当前集群中存在 Leader
await cls.wait_for_election_success()
# 如果 Leader 不是自己,抛出异常
if not isinstance(cls.leader, Leader):
raise NotALeaderException(
'Leader is {}!'.format(cls.leader or 'not chosen yet')
)
return await func(cls, *args, **kwargs)
return wrapped