DeepFM模型介绍及应用
文章目录
- Introduction
- DeepFm 模型
- 模型结构
- FM Component
- Deep Component
Introduction
对于一个基于 CTR 预估的推荐系统,最重要的是学习到用户点击行为背后隐含的特征组合。在不同的推荐场景中,低阶组合特征或者高阶组合特征可能都会对最终的 CTR 产生影响。
Wide & Deep Learning 通过组合使用 cross-product transformation 特征的线性模型和 DNN 模型进行 Joint train 从而实现 memorization 和 generalization 的结合。但是对于 Wide 模型来说还是需要做一些特征交叉来实现 memorization,而因子分解机 (Factorization Machines, FM) 通过对于每一维特征的隐变量内积来提取特征组合,最终的结果也非常好。虽然理论上来讲 FM 可以对高阶特征组合进行建模,但实际上因为计算复杂度的原因一般都只用到了二阶特征组合。
关于 Wide & Deep Learning 请参考博文:Wide & Deep Learning模型介绍
那么对于高阶的特征组合来说,我们很自然的想法,通过多层的神经网络即 DNN 去解决。
对于离散特征的处理,我们使用的是将特征转换成为 Onehot 的形式,但是将 Onehot 类型的特征输入到 DNN 中,会导致网络参数太多难以训练1:
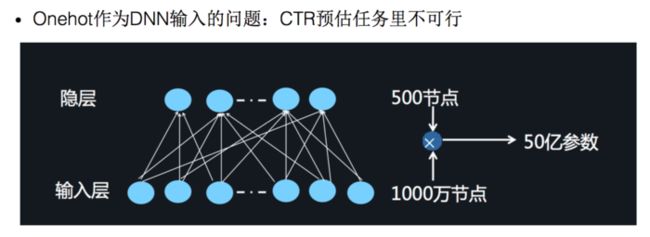
此时可以借鉴 word2vec 的思路,进行 embedding。将 Onehot 编码后的向量经过一个 embedding 层输出 Dense Vector。具体的思路就是,将一个特征 Onehot 编码后会生成多个特征,但是每个特征里面只有一个为 1 1 1,其他都为 0 0 0,这些由一个特征生成的多个互斥的特征引用 FFM 的思想的话就属于一个 Field。

如果将 embedding 层的输出再加两层的全连接层,让 Dense Vector 进行组合,那么高阶特征的组合就出来了。

但是低阶和高阶特征组合隐含地体现在隐藏层中,如果我们希望把低阶特征组合单独建模,然后融合高阶特征组合。
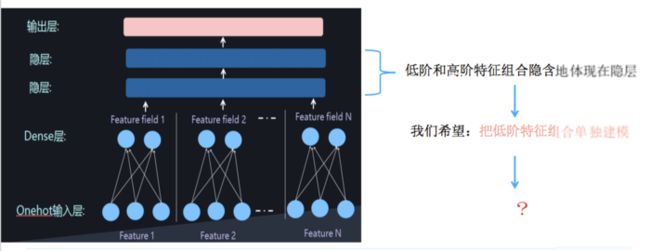
也就是我们需要学习低阶的特征组合,也需要学习高阶的特征组合。即将 DNN 与 FM 进行一个合理的融合:
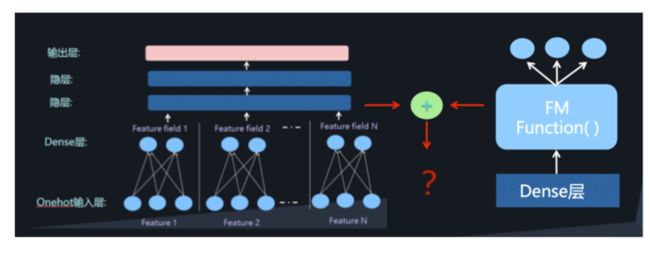
二者的融合总的来说有两种形式,一是串行结构,二是并行结构


而 DeepFM2,就是并行结构中的一种典型代表。
DeepFm 模型
模型结构

DeepFM 包含两部分:神经网络部分与因子分解机部分,分别负责低阶特征的提取和高阶特征的提取。这两部分共享同样的输入。DeepFM 的预测结果可以写为:
y ^ = s i g m o i d ( y F M + y D N N ) (1) \hat y = sigmoid({y_{FM}} + {y_{DNN}})\tag1 y^=sigmoid(yFM+yDNN)(1)
FM Component
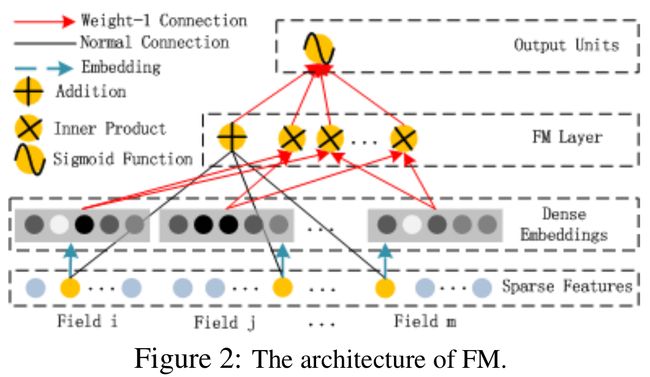
FM 部分是一个因子分解机。关于因子分解机可以参阅文章 Factorization machines3。因为引入了隐变量的原因,对于几乎不出现或者很少出现的隐变量,FM 也可以很好的学习。
FM的输出公式为:
y ( x ) = w 0 + ∑ i = 1 n ( w i x i ) + ∑ i = 1 n − 1 ∑ j = i + 1 n ( < v i , v j > x i x j ) (2) y(x)=w_0+\sum_{i=1} ^n(w_i x_i)+\sum_{i=1}^{n-1} \sum_{j=i+1}^n(
y ( x ) = w 0 + ∑ i = 1 n ( w i x i ) + ∑ i = 1 n − 1 ∑ j = i + 1 n ( < v i , v j > x i x j ) (3) y(x)=w_0+\sum_{i=1} ^n(w_i x_i)+\sum_{i=1}^{n-1} \sum_{j=i+1}^n(
Deep Component
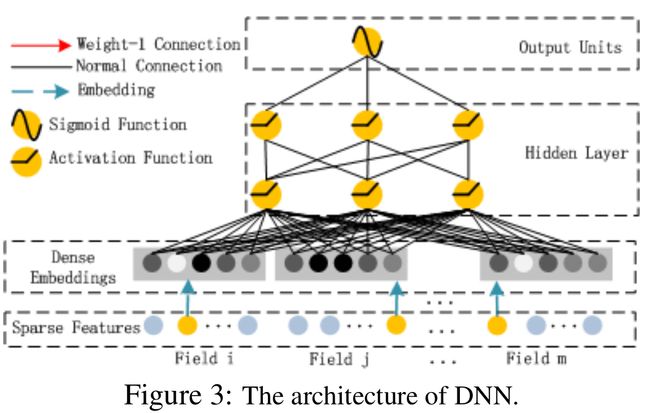
深度部分是一个前馈神经网络。与图像或者语音这类输入不同,图像语音的输入一般是连续而且密集的,然而用于 CTR 的输入一般是及其稀疏的。因此需要重新设计网络结构。具体实现中为,在第一层隐含层之前,引入一个嵌入层来完成将输入向量压缩到低维稠密向量。
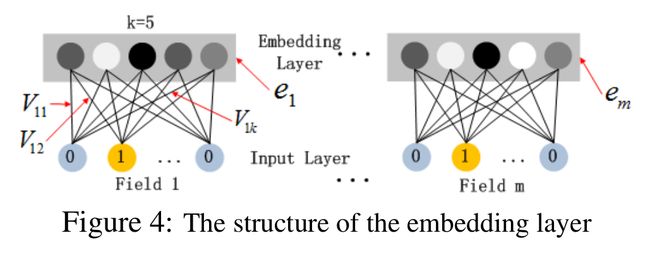
嵌入层 (embedding layer) 的结构如上图所示。
对于 Fig.4 这个网络结构有两个很有意思的 point:
-
虽然输入的 field vector 长度不一,但是它们 embedding 出来的长度是固定的;
-
FM 的 latent vector V V V 向量作为原始特征到 embedding vector 的权重矩阵,放在网络里学习。
这里的第二点如何理解呢,假设我们的 k = 5 k=5 k=5,首先,对于输入的一条记录,同一个 Field 只有一个位置是1,那么在由输入得到 dense vector 的过程中,输入层只有一个神经元起作用,得到的 dense vector 其实就是输入层到 embedding 层该神经元相连的五条线的权重,即 v i 1 v_{i1} vi1, v i 2 v_{i2} vi2, v i 3 v_{i3} vi3, v i 4 v_{i4} vi4, v i 5 v_{i5} vi5。这五个值组合起来就是我们在 FM 中所提到的 v i v_i vi。在 FM 部分和 DNN 部分,这一块是共享权重的,对同一个特征来说,得到的 V i V_i Vi 是相同的。
推荐系统遇上深度学习(三)–DeepFM模型理论和实践 ↩︎
DeepFM: a factorization-machine based neural network for CTR prediction ↩︎
Factorization machines ↩︎