Google研究 | 联合学习:无需集中存储训练数据的协同机器学习

文 | Google 研究员 Brendan McMahan 和 Daniel Ramage
标准的机器学习方法需要将训练数据集中到一台机器上或一个数据中心内。为了处理此数据,改善我们的服务,Google 构建了一套最安全、最强大的云基础架构。现在,对于通过用户与移动设备交互进行训练的学习模式,我们另外引入了一种方法:联合学习。
通过联合学习,移动电话可以协同学习共享的预测模型,同时将所有训练数据保留在设备上,从而无需将数据存储在云中,即可进行机器学习。同时,通过将模型训练引入到设备上,超越了以往使用本地模型预测移动设备(例如 Mobile Vision API 和设备端智能回复)的模式。
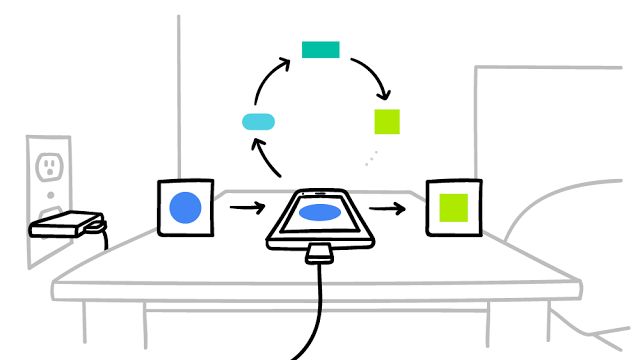
其工作原理如下:您的设备下载当前模型,通过学习手机中的数据改进模型,然后以小幅更新的形式汇总所做的变更。通过加密通信仅将此模型的更新发送至云,在云中,立即与其他用户更新进行平均,以改进共享模型。所有训练数据仍保留在您的设备上,云中未存储任何个别用户的更新。

▲ 您的手机根据您的使用情况,在本地建立个性化模型 (A)。然后,许多用户的更新聚合 (B) 在一起,形成对共享模型的一致更新 (C),之后不断重复此流程。
联合学习可建立更智能的模型,缩短延迟时间,减小功耗,同时确保隐私性。这种方法另一个直接的益处是:除了为共享模型提供更新之外,还可以即时使用手机中经过改进的模型,根据您使用手机的方式,提供个性化的体验。
我们目前正在 Android 版 Gboard(即 Google 键盘)中测试联合学习。当 Gboard 显示建议的查询内容时,您的手机在本地存储与当前上下文以及您是否点击此建议有关的信息。联合学习处理设备上的历史记录,为 Gboard 的查询建议模型的后续迭代提出改进建议。
要实现联合学习,我们必须克服算法和技术上的诸多挑战。在典型的机器学习系统中,对大型数据集执行类似随机梯度下降 (SGD) 这样的优化算法时,会将数据集均匀地分散在云中的不同服务器上。这种高度迭代的算法要求与训练数据之间保持低延迟时间、高吞吐量的连接。而在联合学习环境中,数据很不均匀地分散在数以百万计的设备之间。此外,相比之下,这些设备的连接的延迟时间要长很多,而吞吐量却低很多,并且只能间歇性用于训练。
这些带宽和延迟时间上的限制促使我们设计出联合平均算法,此算法训练深度网络所用的通信资源不到最初 SGD 联合版本的 1/10-1/100。关键在于利用现代移动设备中强大的处理器来计算比简单梯度方法质量更高的更新。由于只需较少的优质更新迭代就可生成适当的模型,训练使用的通信资源大大减少。由于上传速度通常远低于下载速度,我们还研究出了一种新方法,通过使用随机旋转和量化的方式压缩更新,使上传通信开销最多可降至之前的 1/100。这些方法主要用于深度网络训练,我们还为擅长解决点击率预测等问题的多维稀疏凸集模型设计了多种算法。
将此技术部署到数以百万计运行 Gboard 的手机,需要一整套成熟的技术。设备端训练采用了迷你版 TensorFlow。审慎地计划,确保仅在设备处于空闲、通电状态并使用免费的无线连接时进行训练,以便不影响手机的性能。
▲ 仅在不会影响您的体验的情况下,才让您的手机参与联合学习。
然后,系统需要以安全、高效、可扩展和容错的方式传输和聚合模型更新。只有将研究与此基础架构相结合,才能从联合学习中受益。
联合学习的运行无需将用户数据存储在云中,但我们并未止步于此。我们开发了一种使用加密技术的安全聚合协议,以便协调服务器仅当 100 或 1000 个用户参与时解密平均更新,在平均更新之前不检查任何手机的更新。它是同类协议中第一个可用于解决深度网络级别问题和现实连接限制的协议。我们设计了联合平均算法,使协调服务器仅仅需要进行平均更新,因此可使用安全聚合协议;但此协议为通用协议,也可用于解决其他问题。我们正努力将此协议应用于生产环境,希望能在不久的将来将它部署用于联合学习应用。
在探索潜在应用领域方面,我们的工作目前尚在走马观花阶段。联合学习无法解决所有机器学习问题(例如,通过训练认识仔细标注的图例,学习识别不同的犬类),而对于其他许多模型而言,必要的训练数据已存储在云中(例如,Gmail 垃圾邮件过滤器训练)。因此,Google 将继续推进基于云的尖端机器学习技术,同时,我们不断研究联合学习技术,以便解决更多的问题。例如,除了 Gboard 的查询建议外,我们还希望改进语言模型,根据您在手机上实际键入的内容改进键盘(可以定制独有的键盘样式),以及根据用户查看、分享或删除的照片类型,对照片进行排名。
应用联合学习需要机器学习从业者采用新的工具和新的思维方式:模型开发、训练和评价,不直接访问或标记原始数据,而通信开销是它们的一个制约因素。我们相信,联合学习将让用户受益,值得我们去攻克技术上的难题,而我们发布此博文的目的是希望联合学习能在机器学习社区得到广泛的讨论。
致谢:
此文源自 Google 研究部门的多位同仁(包括 Blaise Agüera y Arcas、Galen Andrew、Dave Bacon、Keith Bonawitz、Chris Brumme、Arlie Davis、Jac de Haan、Hubert Eichner、Wolfgang Grieskamp、Wei Huang、Vladimir Ivanov、Chloé Kiddon、Jakub Konečný、Nicholas Kong、Ben Kreuter、Alison Lentz、Stefano Mazzocchi、Sarvar Patel、Martin Pelikan、Aaron Segal、Karn Seth、Ananda Theertha Suresh、Iulia Turc 和 Felix Yu 等)以及 Gboard 团队合作伙伴的共同贡献。
了解更多细节,查看文内所有链接,请点击文末“阅读原文”。
推荐阅读:
Google研究 | 使用一致的哈希算法分配临界负载
人工智能是一种技术手段,不是魔法
TensorFlow使用者有奖征集
TensorFlow 1.0 发布,更快、更灵活、更方便!
点击「阅读原文」,查看文内链接