Feedback Network for Image Super-Resolution
Feedback Network for Image Super-Resolution 是CVPR2019的论文
论文地址:https://arxiv.org/pdf/1903.09814.pdf
pytorch代码地址:https://github.com/Paper99/SRFBN_CVPR19
这篇论文做出的贡献
- 在图像超分辨率上提出了一个网络super-resolution feedback
- network (SRFBN) 提出了FB(feedback block)反馈模块
- 在提出的SRFBN网络上运用了Curriculum learning strategy(课程学习策略)
1 网络整体结构
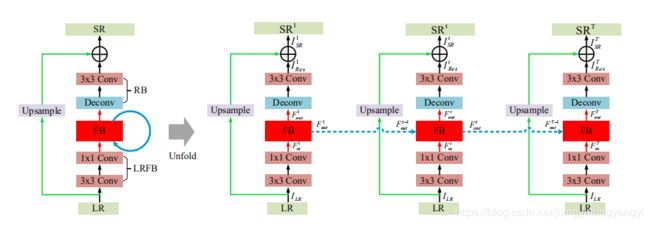
输入输出
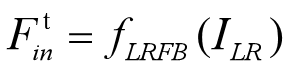
ILR表示输入的LR图像(低分辨率图像),通过对ILR图进行特征提取操作得到Ftin图像。fLRFB表示对图像进行特征提取操作,运用两个卷操作Conv(3, 4m) and Conv(1, m),m表示的是滤波器的特征数。并且F1in 做为 F0out。
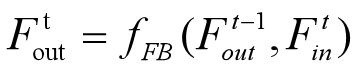
FB在第t次迭代接收来自t-1次迭代输出的 Ft-1out和本次迭代输入的Ftin,进行fFB操作产生 Ftout。fFB表示feedback block操作,后面详细讲解该成模块。
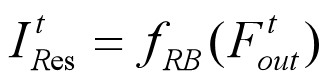
该部分是重建模块,运用Deconv(k, m)去放大LR的特征图 Ftout,然后再用 Conv(3, cout) 产生ItRes图像,fRB表示重建操作。
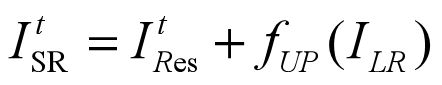
最后输出的高分辨图片ItSR,由ItRes和fUP(ILR)相加而来。fUP表示应该上采样核,并且核的大小是随机的。这篇论文采用的是bilinear upsample kernel(双线性插值)。需要知道的一点是,该论文使用最后的一次迭代结果ITSR 做为最后的到的超分辨率图像,除非需要特别的分析每一次迭代结果除外。
2 Feedback block
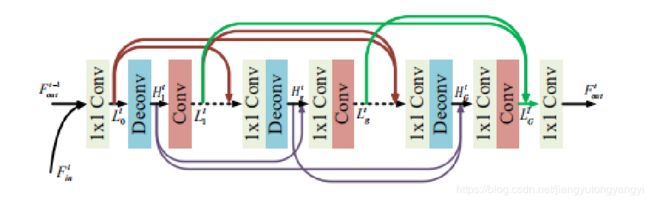
这是着论文比较核心的一部分,通过反馈模块可以很大程度上提高得到的超分辨的图像质量。FB模块在第t次迭代的时候接收t-1次迭代输出的 Ft-1out去纠正低层的表达 Ftin。FB包括了G个映射组,并且投影组之间有密集的跳跃连接。
可能最开始很难理解这个反馈是什么,有什么作用。反馈是利用一组条件来调节另外一组条件,这样做是为了增加或抑制系统的变化。当过程趋向于增加系统的变化时,这种机制被称为正反馈。负反馈是指过程试图对抗变化并保持平衡。在生物上来打一个比方,比如外界温度变高,皮肤的感受到温度变高就传到大脑的神经中枢,让身体出汗,抑制温度的增加。这里它就是用高层的表示去纠正低层的错误。高层指的输入Ft-1out,低层指的是从LR中提取到的特征图Ftin。
这篇文章讲feedback,讲得很明白。https://www.reference.com/science/feedback-mechanism-29d813cb24ba73d9
输入输出
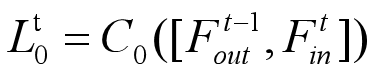
Ftin 和 Ft-1out进行串联,我理解的是进行channel连接,他们的大小是一样的,然后对在特征数上进行连接,就是和上一篇论文讲的密集网络中的连接操作是一样的。然后再用 Conv(1, m)的卷积进行压缩。其实就是减少channel或者说是减少特征图是数量。C0代表了刚刚说的串联和压缩操作。
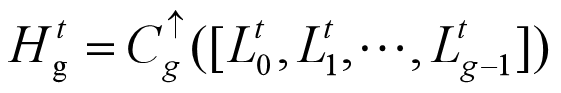
Htg是t次迭代的HR的特征图映射。 它由Lt0到Ltg-1串联后进行上采样得到。C↑g表示用Deconv(k, m)卷积进行上采样操作。

Ltg由Ht1到Htg串联后进行上采样得到。C↓g表示用Deconv(k, m)卷积进行上采样操作。从FB结构图可以看出除了第一层以外在上采样和下采样前面都加了Conv(1, m)的卷积操作,这样做是为了减少参数,提高运算效率。
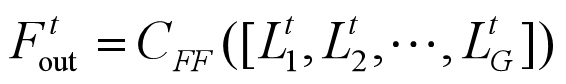
最后输出Ftout由Lt1到 LtG串联后进行CFF操作。CFF表示Conv(1, m)的卷积操作。
3 Curriculum learning strategy
课程学习策略是由易到难的学习,在网络中课程学习策略是,训练目标又易到难,后面论文针对课程学习策略进行了实验,看了实验应该会更加明白一些。
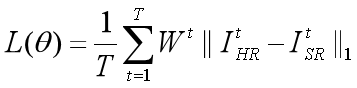
论文中的运用的是L1损失函数。值得注意的是它将每一次迭代的损失都是连接起来了的。把每次迭代的损失求和再求平均。
目标HR图像(I1HR, I2 HR, …, ITHR)做为ground-truth(正确的label)放在网络对应的位置。对于单个的退化模型来说(I1HR, I2 HR, …, ITHR)都是相同的,对于复杂的退化模型来说(I1HR, I2 HR, …, ITHR)由易到难的排列,做为t次迭代的ground-truth。
4 Experiment
实验的一些细节:
- Training data:DIV2K[1] and Flickr2K
- Evaluation:PSNR and SSIM
- Activation function:PReLU
- batchsize: 16
- Optimizer:Adam
- Learning rate:0.0001
4.1 Degradation models
论文设计了3个退化模型,BI,BD,DN。BI是论文中的标准退化模型,为了验证课程学习策略的有效性,设计了BD,DN。下面分别来讲一下这3种模型。
BI: 对HR图像采用双三次下采样,做为LR图像。
BN: 将高斯模糊和下采样运用到HR图像上,使用标准差为1.6的 7x7 的高斯核。
DN: 使用双三次下采样,然后加入噪声,噪声大小为30
4.2 Study of T and G
T代表了迭代的次数,G代表的是FB模块中映射组的数量。并且设置之前的卷积的特征数m为32。论文先固定G=6,来看T对结果的影响,然后固定T=4,来看G的影响。

从图中可以看出来T的增加可以提高重建质量。G的增加由于其强大的表达能力可以提高准确度。并且当T和G都很小的时候,他们对比其他方法也表现得更加好。
4.3 Feedback vs.feedforward
论文的这部分将前馈和反馈进行对比,前馈就是我们通常的网络,从输入层到隐藏层然后到输出层向前一步一步进行,这就是feedforward。Feedback在前面已经解释过了。下面是其对在PSNR(峰值信噪比)上的对比。
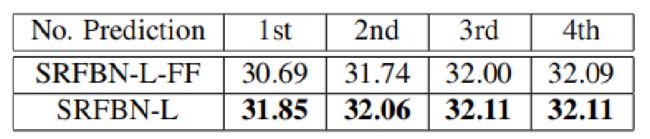
SRFBN-L表示(T=4, G=6)。SRFBN-L-FF表示该feedforward。这里是断开所有迭代层的loss除了最后一次迭代, 因此,网络不可能将输出的概念重新路由到低级表示,然后退化为feedforward。这里我理解的是feedback从高层输入的信息就不能够去纠正低层的信息了。但是feedback不仅仅只有这一个该因素。还有两个因素:权重共享和每一次迭代LR图片做为低层输入。论文在写道如果关掉权重共享或者是断开迭代中的LR输入,PSNR都会降低。

这是Feedback 和feedforward可视化的效果。他们的网络抑制了原始图像的平滑区域和预测了更多的高频分量。图上可以看到边缘和轮廓在早期迭代时被勾勒出来。并且所含高频信息更多。
4.4. Study of curriculum learning
实验在BD和DN模型上,看有CL(curriculum learning)和没有CL的区别。
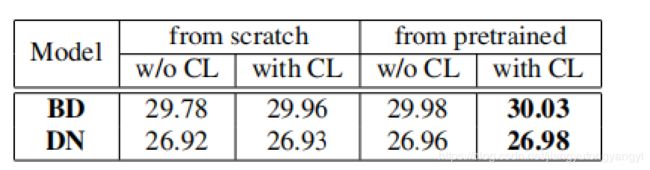 首先明确T=4。在BD模型上在前两次迭代的真值是blurred HR images(模糊了的HR图片),后两次以HR原始图片做为label。在前面提到过BD模型,它的LR图片是经过高斯模糊和下采样的生成的。那么如果早期的真值是高斯模糊的图片,就意味着网络只需要学习到如何去反下采样就可以了。同理对于DN模型也是前两次迭代用具有噪声的HR做为label。后面两次迭代用没有噪声的HR做为label。
首先明确T=4。在BD模型上在前两次迭代的真值是blurred HR images(模糊了的HR图片),后两次以HR原始图片做为label。在前面提到过BD模型,它的LR图片是经过高斯模糊和下采样的生成的。那么如果早期的真值是高斯模糊的图片,就意味着网络只需要学习到如何去反下采样就可以了。同理对于DN模型也是前两次迭代用具有噪声的HR做为label。后面两次迭代用没有噪声的HR做为label。
4.5 Network parameters
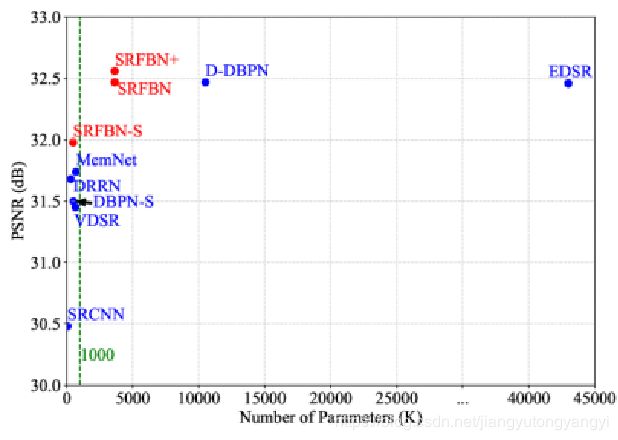
这里有该论文中的三个模型
- SRFBN: A larger base number of filters (m=64)
- SRFBN+: A self-ensemble method
- SRFBN-S:T=4, G=3,m=32
其中SRFBN和SRFBN-S应该都很清楚,就是SRFBN+可能不太清楚,什么是自组装方式。是CVPR2016年一篇论文提出来的方法,提出了七个提高得到高分辨的图像的方法,其中包括增加训练数据、back project(得到一个图像的直方图,然后通过直方图去在某张图片中检测到相似的特征区域)…等等一共7中提高最后高分辨率结果的方法。该论文地址:https://arxiv.org/pdf/1511.02228.pdf
4.6 Results with BI degradation model
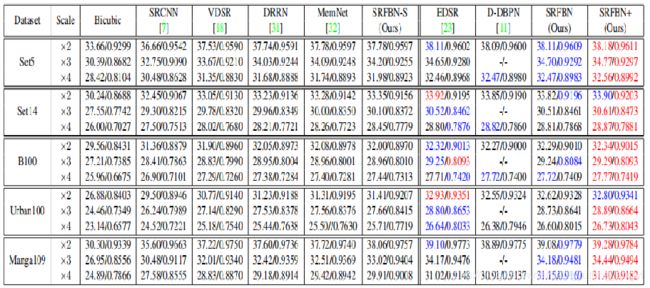
红色代表最好效果,绿色代表第二好的效果。其中table中的值为PSNR/SSIM。可以看到最好的效果基本上是SRFBN+。说明这篇论文中的网络的效果还是很不错的。
5 Supplementary Material
这篇论文还有一些补充材料。
- Study of Feedback Block
- Running Time Comparison
- More QualitativeResults
5.1 Study of Feedback Block
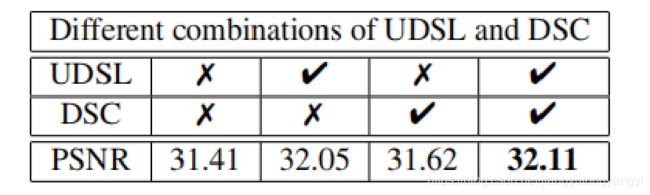
UDSL表示FB块中的up- and down-sampling layers,用3x3的,步幅为1,padding为1的卷积代替。DSC表示dense skip connecitons。上表结果显示去掉UDSL和DSC都会导致PSNR降低。
5.2 Running Time Comparison
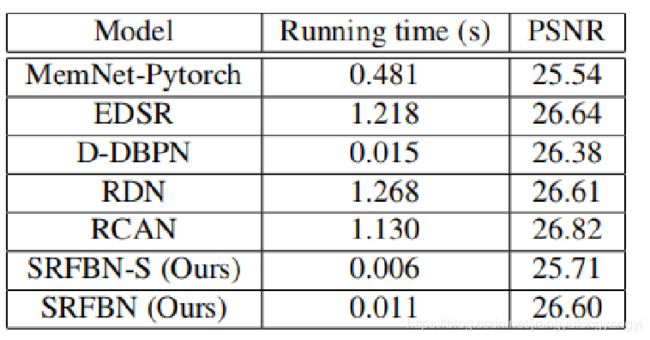
可以看到论文中的方法的时间消耗很小,都是PSNR的值比较高。
5.3 More Qualitative Results

好,以上就是我对这篇论文的理解。可以多多点赞哟,笔芯。