早期(编译器)优化
概述
我们都知道编译器把java文件转变成class文件的东西,其实还有一种过程也叫编译,即JIT编译器,把字节码转变为机器码的过程,还有可能是指使用静态编译器AOT编译器,直接把java文件编译成本地机器代码的过程:
- 前端编译器:Sun的javac、Eclipse JDT中的增量式编译器(ECJ)
- JIT编译器:HotSpotVM的C1、C2编译器
- AOT编译器:GUN Compiler for Java(GCI)、Excelsior JET
而本节讨论的事第一个,前端编译器,这个前端编译器,不是用来编译html代码的编译器,而是,java整个编译过程的前端。
Javac 编译器
Javac的源码与调试
Javac的源码在com.sun.tools.javac中,
而Javac编译器编译的过程大致可分为三个过程:
- 解析与填充符号表过程
- 插入式注解处理器的注解处理过程
- 分析与字节码生成过程

以下是Javac源码的整个编译过程:
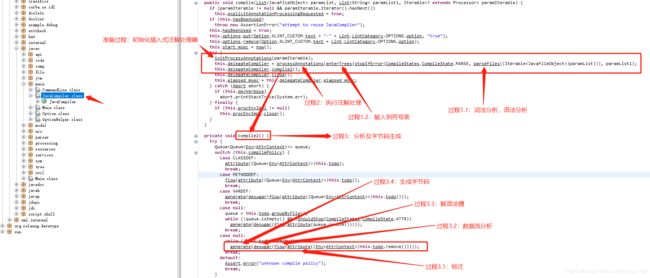
解析与填充符号表(parseFiles方法)
词法分析、语法分析是将源代码的字符流转变为标记集合,单个字符是程序编写过程的最小元素,而标记则是编译过程的最小元素,关键字,变量名,字面量,运算符都可以称为标记,比如:
词法分析
int a = b+2
这句代码包含了6个标记,分别是,int,a,=,b,+,2,虽然关键字是三个字符构成,但是这是一个不可拆分的一个(Tocken)。
也就是说词法分析,能提取出需要的词法。
语法分析
语法分析就是根据Tocken序列构造抽象语法树的一个过程,抽象语法树是干嘛用的呢?
抽象语法树一旦生成,编译器就基本不会再对源码文件进行操作了,后续的操作都建立在抽象语法树之上。也就是说后续的一些验证啊,分析啊,解语法糖,生成字节码之类的操作都建立在抽象语法树之上。`
填充符号表(enterTrees方法)
符号表是由一组符号地址和符号信息构成的表格,符号表中所登记的信息在编译的不同阶段都要用到。在语义分析中,符号表所登记的内容将用于语义检查(如检查一个名字的使用和原先的说明是否一致)和产生中间代码。在目标代码生成阶段,当对符号名进行地址分配时,符号表是地址分配的依据。
注解处理器
在JDK1.6中实现了JSR-269规范,提供了一组插入式注解处理器的标准API在编译期间对注解进行处理,我们可以把他看作是一个编译器的插件,在这些插件里面,可以读取修改添加抽象语法树中的任意元素,如果这些插件在处理期间对语法树进行了修改,编译器会回到解析及填充符号表的过程重新处理,直到所有插入式注解处理器都没有再对语法树进行修改为止,每一次循环称为一个Round。
语义分析与字节码生成
语法树生成之后,但是无法保证源程序是符合逻辑的,而语义分析的主要任务是对结构上正确的源程序进行上下文有关性质的审查,如进行类型审查:
int a = 1;
boolean b = false;
char c = 2;
后续可能出现的赋值运算:
int d = a + c;
int d = b + c;
char d = a + c;
后续的赋值运算都可以构成结构正确的语法树,但是只有第1种的写法在语义上是没有问题的,能够通过编译。
语义分析分为标注检查和控制流分析两个步骤,分别为attribute()和flow()方法,标注检查的内容包括诸如变量使用前是否已被声明、变量与赋值之间的数据类型是否能够匹配等,在这个步骤中还有一个重要的操作叫常量折叠,如下代码:
int a = 1+ 2;
那么经过常量折叠之后,会被折叠为字面量3,也就是在语法树上面标注的就是3,所以代码里面定义a=1+2比起a=3,并不会增加程序运行期哪怕仅仅一个CPU指令的运算量。
然后接下来就是数据及控制流,这一步是对程序上下文逻辑更进一步的验证:
- 检查程序局部变量在使用前是否有赋值
- 方法的每条路径是否都有返回值
- 是否所有的受查异常都被正确处理等问题
解语法糖(desugar()),最主要的是泛型、变成参数、自动装箱拆箱,虚拟机在运行的时候是不支持这些语法,它们在编译阶段还原回简单的基础语法结构,这个过程叫解语法糖。
字节码生成是Javac编译过程的最后一个阶段,字节码生成阶段不仅仅把前面各个步骤所生成的信息(语法树、符号表)转化成字节码写到磁盘中,编译器还进行了少量的代码添加工作和转换工作。比如实例的构造器()方法和类构造器()方法就是在这个阶段添加到语法树之中的,这个过程是一个收敛的过程,编译器会把语句块({}块)、变量初始化、以及调用父类的实例构造器等操作收敛到()方法和()方法之中,并且保证一定是按先执行父类的实例构造器,然后初始化变量,最后执行语句块的顺序进行。出了生成构造器室外,还有其他的一些代码替换工作用于优化程序的实现逻辑,如把字符串的加操作替换为StringBuffer或StringBuilder的append()操作。
语法糖
泛型与类型擦除
请看下面代码:
import java.util.HashMap;
import java.util.Map;
public class Fanxing {
public static void main(String[] args) {
Map map = new HashMap();
map.put("hello","你好");
map.put("how are you","吃了没");
System.out.println(map.get("hello"));
System.out.println(map.get("how are you"));
}
}
以及编译后过的代码:
import java.util.HashMap;
public class Fanxing {
public Fanxing() {
}
public static void main(String[] var0) {
HashMap var1 = new HashMap();
var1.put("hello", "你好");
var1.put("how are you", "吃了没");
System.out.println((String)var1.get("hello"));
System.out.println((String)var1.get("how are you"));
}
}
可以看到泛型消失了,也就是说无论泛型是什么,在编译之后都会变为最基础的类型。
当泛型遇见重载:
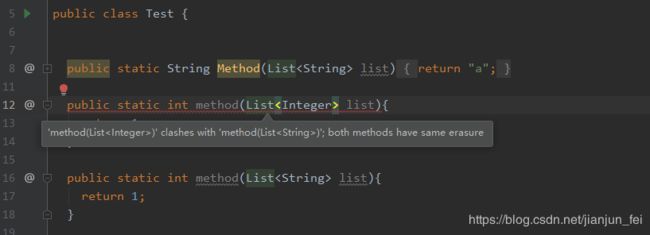
这也可以验证了,泛型会导致参数一样,然后无法重载。
自动装箱、拆箱与遍历循环
如下代码:
import java.util.Arrays;
import java.util.List;
public class Boxing {
public static void main(String[] args) {
List list = Arrays.asList(1,2,3,4);
int sum = 0;
for (int i : list){
sum+=i;
}
System.out.println(sum);
}
}
以及编译之后的代码:
import java.util.Arrays;
import java.util.Iterator;
import java.util.List;
public class Boxing {
public Boxing() {
}
public static void main(String[] var0) {
List var1 = Arrays.asList(1, 2, 3, 4);
int var2 = 0;
int var4;
for(Iterator var3 = var1.iterator(); var3.hasNext(); var2 += var4) {
var4 = (Integer)var3.next();
}
System.out.println(var2);
}
}
自动装箱拆箱是指int类型转化为Integer类型,拆箱反之,对应着Integer.valeOf()和Integer.intValue()方法,而遍历循环则把代码还原成了迭代器的实现,这也是为何遍历循环需要被遍历的类实现Interable接口的原因,这里我编译出来的没有将Arrays.asLIst方法的变成参数编译出来,实际1,2,3,4是传到了一个数组里面,在边长参数出现之前,程序员就是使用数组来完成类似功能的。
条件编译
如下代码:
public class Statment {
public static void main(String[] args) {
if(true){
System.out.println(1);
}else{
System.out.println(2);
}
}
}
以及编译后的代码:
public class Statment {
public Statment() {
}
public static void main(String[] var0) {
System.out.println(1);
}
}
很明显,字节码中并不会包含System.out.println(2)语句。
实战:插入式注解处理器
编写一个用来检查编码风格检验工具:NameCheckProcessor,
package process;
import java.util.Set;
import javax.annotation.processing.AbstractProcessor;
import javax.annotation.processing.ProcessingEnvironment;
import javax.annotation.processing.RoundEnvironment;
import javax.annotation.processing.SupportedAnnotationTypes;
import javax.annotation.processing.SupportedSourceVersion;
import javax.lang.model.SourceVersion;
import javax.lang.model.element.Element;
import javax.lang.model.element.TypeElement;
//可以用"*"表示支持所有Annotations,可以使用通配符,如果需要不同包下的话可以使用{}进行分割
@SupportedAnnotationTypes("*")
//这里填写支持的java版本
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class NameCheckProcessor extends AbstractProcessor {
private NameChecker nameChecker;
/**
* 初始化名称检查插件,processingEnv为注解处理器提供的上下文环境
*/
@Override
public void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
nameChecker = new NameChecker(processingEnv);
}
/**
* 对输入的语法树的各个节点进行进行名称检查
*/
@Override
public boolean process(Set annotations, RoundEnvironment roundEnv) {
if (!roundEnv.processingOver()) {
for (Element element : roundEnv.getRootElements())
//这里可以执行想要的操作
{
System.out.println("=================="+element.getSimpleName());
nameChecker.checkNames(element);
}
}
return false;
}
}
package process;
import java.util.EnumSet;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import javax.annotation.processing.Messager;
import javax.annotation.processing.ProcessingEnvironment;
import javax.lang.model.element.Element;
import javax.lang.model.element.ElementKind;
import javax.lang.model.element.ExecutableElement;
import javax.lang.model.element.Modifier;
import javax.lang.model.element.Name;
import javax.lang.model.element.TypeElement;
import javax.lang.model.element.VariableElement;
import javax.lang.model.util.ElementScanner6;
import javax.lang.model.util.ElementScanner8;
import javax.tools.Diagnostic.Kind;
//为了演示效果,命名正常的类也会以警告级别显示出来
public class NameChecker {
//Messager用于向编译器发送信息
private final Messager messager;
NameCheckScanner nameCheckScanner = new NameCheckScanner();
NameChecker(ProcessingEnvironment processsingEnv) {
this.messager = processsingEnv.getMessager();
}
public void checkNames(Element element) {
nameCheckScanner.scan(element);
}
/**
* 名称检查器实现类
* 将会以Visitor模式访问抽象语法树中的元素
* 命名规则判断中将不对语法树进行修改,因此全部返回值都为null
*/
private class NameCheckScanner extends ElementScanner8 {
/**
* 此方法用于检查类名
* 带可变参数Void,该参数包含9种类型
*/
@Override
public Void visitType(TypeElement e, Void p) {
scan(e.getTypeParameters(), p);
checkClassName(e);
super.visitType(e, p);
return null;
}
//首字母大写
public void checkClassName(TypeElement e) {
String name = e.getSimpleName().toString();
if("".equals(name)||name==null) {
messager.printMessage(Kind.WARNING, "类名" + name + "出现异常", e);
}
String regEx ="[A-Z][A-Za-z0-9]{0,}";
Pattern pattern = Pattern.compile(regEx);
Matcher matcher = pattern.matcher(name);
if(matcher.matches()) {
messager.printMessage(Kind.WARNING, "类名" + name + "符合驼式命名法,首字母大写", e);
}else {
messager.printMessage(Kind.WARNING, "类名" + name + "不符合符合驼式命名法", e);
}
}
/**
* 检查方法命名是否合法
*/
@Override
public Void visitExecutable(ExecutableElement e, Void p) {
if (e.getKind() == ElementKind.METHOD) {
Name name = e.getSimpleName();
checkMethodName(e);
}
super.visitExecutable(e, p);
return null;
}
//首字母大写
public void checkMethodName(ExecutableElement e) {
String name = e.getSimpleName().toString();
if("".equals(name)||name==null) {
messager.printMessage(Kind.WARNING, "方法名" + name + "出现异常", e);
}
String regEx ="[a-z][A-Za-z0-9]{0,}";
Pattern pattern = Pattern.compile(regEx);
Matcher matcher = pattern.matcher(name);
if(matcher.matches()) {
messager.printMessage(Kind.WARNING, "方法名" + name + "符合驼式命名法,首字母小写", e);
}else {
messager.printMessage(Kind.WARNING, "方法名" + name + "不符合符合驼式命名法,首字母小写", e);
}
}
/**
* 检查变量命名是否合法
*/
@Override
public Void visitVariable(VariableElement e, Void p) {
// 如果这个Variable是枚举或常量,则按大写命名检查,否则按照驼式命名法规则检查
if (e.getKind() == ElementKind.ENUM_CONSTANT || e.getConstantValue() != null || heuristicallyConstant(e))
checkEnumFinal(e);
else
checkField(e);
return null;
}
public void checkField(VariableElement e) {
String name = e.getSimpleName().toString();
if("".equals(name)||name==null) {
messager.printMessage(Kind.WARNING, "字段名" + name + "出现异常", e);
}
String regEx ="[a-z][A-Za-z0-9]{0,}";
Pattern pattern = Pattern.compile(regEx);
Matcher matcher = pattern.matcher(name);
if(matcher.matches()) {
messager.printMessage(Kind.WARNING, "字段名" + name + "符合驼式命名法,首字母小写", e);
}else {
messager.printMessage(Kind.WARNING, "字段名" + name + "不符合符合驼式命名法,首字母小写", e);
}
}
public void checkEnumFinal(VariableElement e) {
String name = e.getSimpleName().toString();
if("".equals(name)||name==null) {
messager.printMessage(Kind.WARNING, "常量" + name + "出现异常", e);
}
String regEx ="[A-Z][A-Z_]{0,}";
Pattern pattern = Pattern.compile(regEx);
Matcher matcher = pattern.matcher(name);
if(matcher.matches()) {
messager.printMessage(Kind.WARNING, "常量" + name + "符合要求全部大写字母或下划线构成,并且第一个字符不能是下划\r\n" +
"线", e);
}else {
messager.printMessage(Kind.WARNING, "常量" + name + "不符合要求全部大写字母或下划线构成,并且第一个字符不能是下划\r\n" +
"线", e);
}
}
/**
* 判断一个变量是否是常量
*/
private boolean heuristicallyConstant(VariableElement e) {
//获得封闭该变量的类,看是否为借口
if (e.getEnclosingElement().getKind() == ElementKind.INTERFACE)
return true;
else if (e.getKind() == ElementKind.FIELD && e.getModifiers().containsAll(EnumSet.of(Modifier.PUBLIC, Modifier.STATIC, Modifier.FINAL)))
return true;
else {
return false;
}
}
}
}
运行与测试:
将如下代码进行编译,使用我们的NameCheckProcessor进行检查校验:
javac -processor process.NameCheckProcessor Test1.java
public class Test1 {
public static int a = 1;
public int getNum(){
return 1;
}
public void DoSomething(){
System.out.println("1");
}
public static void main(String[] args) {
}
}
可以看到,
D:\IDEAWorkspace\CSDNIncrease\src\main\java>javac -processor process.NameCheckProcessor Test1.java
==================Test1
Test1.java:4: 警告: 类名Test1符合驼式命名法,首字母大写
public class Test1 {
^
Test1.java:6: 警告: 字段名a符合驼式命名法,首字母小写
public static int a = 1;
^
Test1.java:8: 警告: 方法名getNum符合驼式命名法,首字母小写
public int getNum(){
^
Test1.java:12: 警告: 方法名DoSomething不符合符合驼式命名法,首字母小写
public void DoSomething(){
^
Test1.java:16: 警告: 方法名main符合驼式命名法,首字母小写
public static void main(String[] args) {
^
Test1.java:16: 警告: 字段名args符合驼式命名法,首字母小写
public static void main(String[] args) {
^
6 个警告
可以看到有一个方法是不符合驼峰命名法的,首字母小写,
NameChecker的代码看起来有点长,它通过继承ElementScanner8的NameCheckScanner类,以Visitor模式来完成对语法树的遍历,分别执行visitTyppe(),visitVarible(),visitExecutable()方法来访问类、字段和方法,这3个visit方法对各自的命名规则做相应的检查,checkCamclCase()与checkAllCaps()方法则用于实现驼峰式命名法和全大写命名规范的检查。
总结
本章中,我们从编译器远吗层面上了解了Java源代码编译为字节码的过程,分析了Java语言中泛型、主动装箱拆箱、条件编译等多种语法糖的前因后果,并实战联系了如何使用插入式注解处理器来完成一个检查程序命名规范的编译器插件。本章中的优化,主要是用于提升程序的编码效率,在后面的章节会介绍“后端编译器”完成了从字节码生成到本地机器码的过程,即JIT即时编译器。