利用python进行数据分析学习笔记1(pandas入门)
pandas引入
import pandas as pdSeries和DataFrame用的比较多
from pandas import Series,DataFramepandas的数据结构介绍
Series
类似一维数组的对象,由一组数据和索引组成。
传入一个列表作为Series的参数创建Seires。
obj = pd.Series([4,7,-5,3]) #创建Series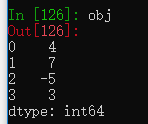
通过Series的values和index属性获取数据和索引。
obj.values
obj.index![]()
![]()
创建Series时可以创建索引。
obj2 = pd.Series([1,2,3,4],index=['a','b','c','d'])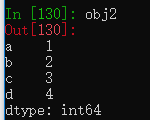
通过索引获取Series中的值。

通过索引修改Series中的值
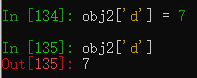
除了使用索引,还可以使用布尔型数据作为参数选择数据
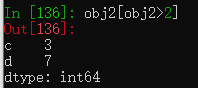
也可以像numpy中的array一样进行数学运算。


通过字典来创建Series,键作为索引。
sdata = {'a':1,'b':2,'c':3,'d':4}
obj3 = pd.Series(sdata)
传入字典作参数外,还能传入排好序的索引,改变Series的顺序
states = ['d','c','b','a']
obj4 = pd.Series(sdata,index=states)
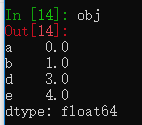
如果传入的索引中含有字典中没有的键,会显示NaN。
pd的isnull和notnull函数可以检测Series中有无缺失值。
pd.isnull(obj4)
pd.notnull(obj4)
Series实例也有这种方法。
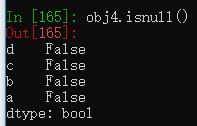
Series运算时根据索引标签自动对齐数据。
sdata2 = {'a':5,'b':6,'c':7,'d':8}
obj5 = pd.Series(sdata2) #新建一个索引名和obj4相同的数组
obj4 + obj5 #将两个数组相加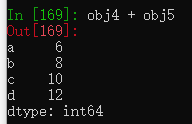
Series对象和索引都有name属性
obj4.name = 'population' #将Series对象的name属性设置为population
obj4.index.name = 'state' #将Series对象的索引的name属性设置为state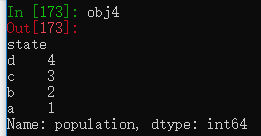
Series的索引通过赋值可以原地修改
obj4.index = ['q','w','e','r']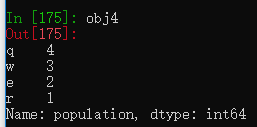
DataFrame
表格型数据结构,含有一组有序的列。
建DataFrame最常用的方法是传入等长列表或数组组成的字典。
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]}
frame = pd.DataFrame(data)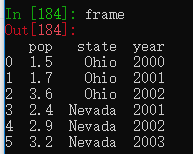
如果DataFrame特别大,通过head方法可以选取前五行。
frame.head()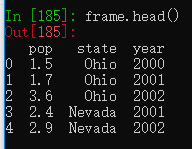
创建DataFrame,在数据参数后面加上columns参数,可以根据指定列进行排序。
pd.DataFrame(data,columns=['year','state','pop'])
如果传入了不存在的列,会返回缺失值。
pd.DataFrame(data,columns=['year','state','pop','test'])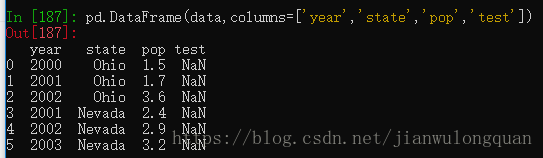
和上面的Series一样,传入index参数可以对行索引进行修改。
通过列名可以获取DataFrame的指定列。
frame['state']
frame.state

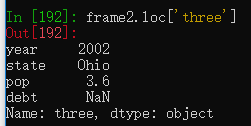
使用DataFrame的loc方法,传入行索引,可以获取指定的行数据。
frame2 = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'],
index=['one', 'two', 'three', 'four',
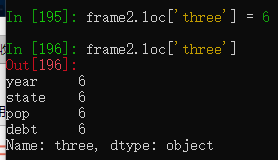
'five', 'six'])frame2.loc['three']
通过索引选中DataFrame中的指定列,然后赋值,可以修改指定列整列的值
frame2['debt'] = 10
也可以使用loc方法选中指定行修改值。
如果右边是个数组或列表等序列,长度要和左边相等,如果是Series,会根据索引自动匹配填充,缺失的会用NaN填充。
val = pd.Series([-1.2, -1.5, -1.7], index=['two', 'four', 'five'])
frame2['debt'] = val #对debt列进行修改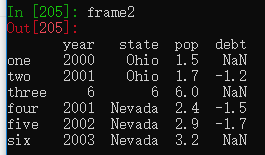
如果左边选择的列不存在,会自动创建一个新列
del用于删除列
del frame2['debt']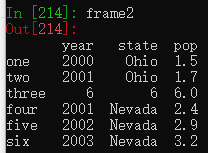
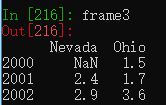
通过嵌套字典创建DataFrame
pop = {'Nevada': {2001: 2.4, 2002: 2.9},
'Ohio': {2000: 1.5, 2001: 1.7, 2002: 3.6}}
frame3 = pd.DataFrame(pop)外层的键作为列索引,内层的键作为行索引。
DataFrame也有类似NumPy的转置方法
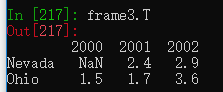
可以输入给DataFrame构造器的数据

可以设置DataFrame的index和columns的name属性。
frame3.index.name = 'year'frame3.columns.name = 'state'DataFrame的values属性会返回所有数据

索引对象
创建一个Series并将其索引设置为指定值。
obj = pd.Series(range(3),index=['a','b','c'])
index = obj.index #将Series的索引对象赋值给一个变量
index对象是不可变的,不能对其进行修改,如index[1] = 't'会报错
pandas的index可以包含重复的标签

index的方法和属性

基本功能
重新索引
obj = pd.Series([4.5, 7.2, -5.3, 3.6], index=['d', 'b', 'a', 'c']) #创建一个Series
obj2 = obj.reindex(['a', 'b', 'c', 'd', 'e']) #使用Series的reindex方法创建一个新Series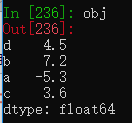
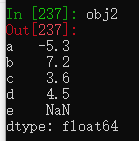
reindex方法传入method='ffill'参数可以实现前向值填充
obj3 = pd.Series(['blue', 'purple', 'yellow'], index=[0, 2, 4])
obj3.reindex(range(6), method='ffill')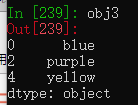

从3行扩充到6行,多出来的行进行前向填充。
默认情况下reindex修改的是行索引,明确传入columns参数时会对列索引进行修改。
frame = pd.DataFrame(np.arange(9).reshape((3, 3)),
index=['a', 'c', 'd'],
columns=['Ohio', 'Texas', 'California']) #创建一个三行三列的DataFrame
states = ['Texas', 'Utah', 'California']
frame.reindex(columns=states) #修改列索引,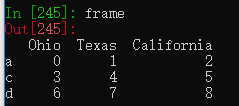

reindex函数的参数

丢弃指定轴上的项
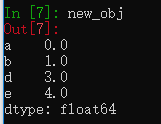
obj = pd.Series(np.arange(5.), index=['a', 'b', 'c', 'd', 'e'])
new_obj = obj.drop('c')
obj.drop(['d','c'])创建一个新Series,通过drop方法可以删除指定索引的数据,drop方法进行的是原地修改。


DataFrame使用drop会默认删除指定行,如果要删除列需要传入参数axis='columns'或axis=1
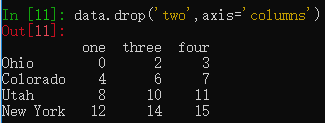
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['one', 'two', 'three', 'four'])
data.drop(['Colorado','Ohio']) #删除指定索引的行
data.drop('two',axis='columns') #删除指定索引的列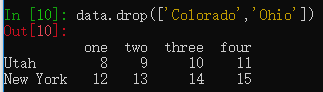
类似drop这种会修改Series或DataFrame大小或形状的函数,通过传入参数inplace=True可以实现就地修改,要谨慎使用,它会销毁被删除的数据。
obj.drop('c',inplace=True)
索引、选取和过滤
obj = pd.Series(np.arange(4.), index=['a', 'b', 'c', 'd'])
obj['b'] #通过标签索引选择数据
obj[1] #通过顺序标签索引选择数据
obj[2:4] #通过顺序标签切片选择数据
obj[obj < 2] #通过布尔型数组选择数据

也可以用标签切片来选择数据,不同的是标签切片左右区间都是闭合的。
obj['a':'c'] #数据a、b、c都会被选中
还能通过切片设置Series指定位置的值
obj['a':'c'] = 10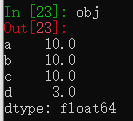
用一个或多个标签可以获取DataFrame中一个或多个列的数据。
data = pd.DataFrame(np.arange(16).reshape((4, 4)),
index=['Ohio', 'Colorado', 'Utah', 'New York'],
columns=['one', 'two', 'three', 'four'])
data['two'] #获取一个列
data[['three','one']] #获取两个列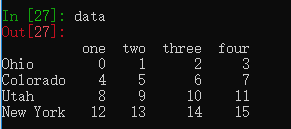


通过顺序数字切片或布尔型数组选取数据
data[:2] #选取前两行数据
data[data['three'] > 5] #选取列three大于5的数据
还有一种通过布尔型DataFrame进行索引。
将DataFrame中小于5的数值改为0。

用loc和iloc进行选取
loc轴标签,iloc整数索引。
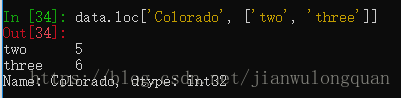
通过loc方法选择指定行标签的行,再通过列标签选择指定列
data.loc['Colorado', ['two', 'three']] #选择Colorado行的two和three列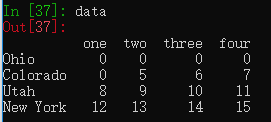
用iloc方法通过顺序数字标签选择指定行列。
data.iloc[2,[3,0,1]] #选择行2的3、0、1列数据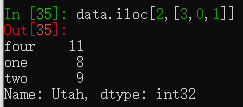
loc和iloc方法也可以进行切片操作。
选择第一行到Utah行,列two的数据。
data.loc[:'Utah','two']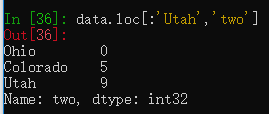
data.iloc[:,:3][data.three > 5]选择所有行前三列的数据,筛选出列three大于5的数据
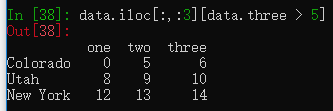
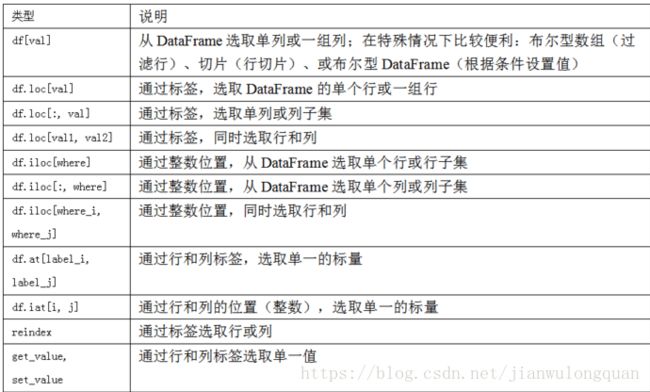
整数索引
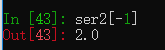
如果Series中的索引是整数,那么选取数据时使用的是标签索引
ser = pd.Series(np.arange(3.))创建了一个Series,索引是默认的,此时如果想取最后一个数据,使用ser[-1]会报错,因为使用的是标签索引,不存在-1的标签。

若创建Series时使用非整数索引,则选择数据时使用的是顺序数据索引。
ser2 = pd.Series(np.arange(3.), index=['a', 'b', 'c'])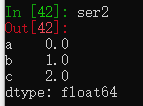
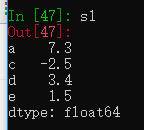
算术运算和数据对齐
创建两个含有重叠行列索引的Series
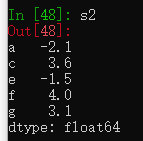
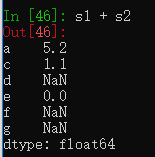
s1 = pd.Series([7.3, -2.5, 3.4, 1.5], index=['a', 'c', 'd', 'e'])
s2 = pd.Series([-2.1, 3.6, -1.5, 4, 3.1],index=['a', 'c', 'e', 'f', 'g'])两个相加,只有行列索引相同的部分会相加,其他显示为NaN。
DataFrame类似。
在算术方法中填充值
df1 = pd.DataFrame(np.arange(12.).reshape((3, 4)),
columns=list('abcd'))
df2 = pd.DataFrame(np.arange(20.).reshape((4, 5)),
columns=list('abcde'))
df2.loc[1,'b'] = np.nan创建两个DataFrame,并将df2的行1,列b的值设为NaN。
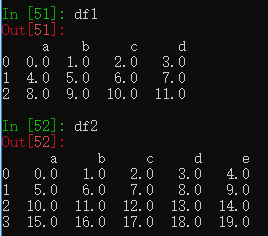

两个DataFrame相加,行列索引不一致的位置会显示为NaN。
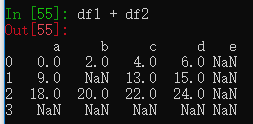
df1可以通过add方法和df2相加,传入fill_value=0参数,行列索引不一致的位置也会显示。
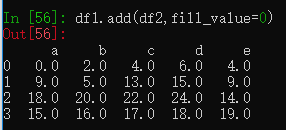

r开头的表示翻转函数,如df1.div(df2)表示用df1中的值除df2的值,df1.rdiv(df2)则表示用df2中的值除df1的值。
fill_value参数是指定填充值,上面的算术方法都可以使用。
DataFrame和Series之间的运算
arr = np.arange(12.).reshape((3, 4))
arr1 = arr[0]
arr - arr1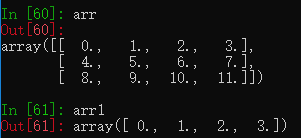
创建一个三行四列的二维数组和一个一行四列的一维数组并相减
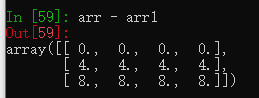
得到的结果是二维数组的每行减相同的一维数组,这称为广播。
DataFrame和Series相减的结果和上面的差不多。
创建一个DataFrame和Series
frame = pd.DataFrame(np.arange(12.).reshape((4, 3)),
columns=list('bde'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])
series = frame.iloc[0]
将二者相减,默认是DataFrame的每行减去一个相同的Series。

如果Series中存在和DataFrame中不一致的列名,不一致的列会全部显示为NaN。
series2 = pd.Series(range(3), index=['b', 'e', 'f'])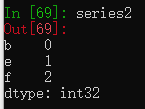

若希望在列上进行广播,则使用算数方法并加入axis参数。
series3 = frame['d']
frame.sub(series3,axis='index')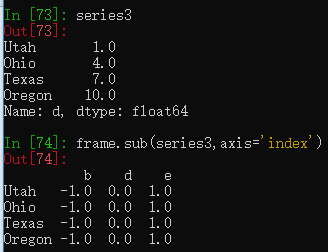
这里DataFrame的每列都减去一个相同的Series。
函数应用和映射
NumPy的通用函数(元素级)可以用于操作pandas对象
frame = pd.DataFrame(np.random.randn(4, 3), columns=list('bde'),
index=['Utah', 'Ohio', 'Texas', 'Oregon'])
np.abs(frame)创建一个DataFrame,通过abs函数可以对DataFrame中的每个数据进行绝对值处理。

另一种方法是建立一个函数,通过DataFrame的apply方法应用到DataFrame中。
f = lambda x:x.max() - x.min() #求极差
frame.apply(f)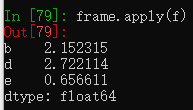
默认是对每列执行,若传入axis='columns'参数则对每行执行。
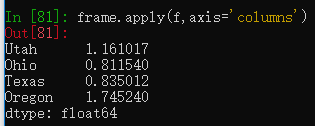
传入的函数除了返回一个值,也可以返回多个值组成的Series。
def f(x):
return pd.Series([x.min(),x.max()],index=['min','max'])
frame.apply(f)
元素级的函数也可以用,作用于DataFrame中的每个元素,不过调用的是applymap函数。
format = lambda x: '%.2f' %x
frame.applymap(format)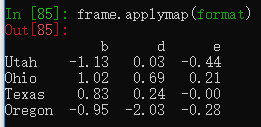
Series中应用于元素级函数的是map方法
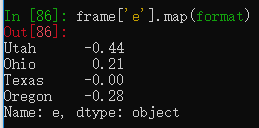
排序和排名
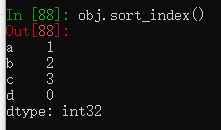
Series有一个sort_index函数是用来排序的。
obj = pd.Series(range(4), index=['d', 'a', 'b', 'c'])
obj.sort_index()
DataFrame中也有这个方法,默认对行索引排序,传入axis参数可以对列排序。
frame = pd.DataFrame(np.arange(8).reshape((2, 4)),
index=['three', 'one'],
columns=['d', 'a', 'b', 'c'])
frame.sort_index() #默认对行索引进行排序
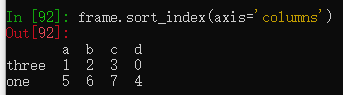
frame.sort_index(axis='columns') #传入axis参数后对列索引进行排序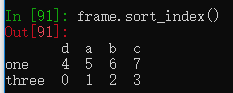
默认是升序排序,传入ascending=False参数可以实现降序排序。
frame.sort_index(axis='columns',ascending=False)
按数据对Series进行排序,使用sort_values方法
obj = pd.Series([4,7,-3,2])
obj.sort_values()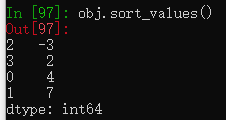
默认升序排序
对DataFrame的数据进行排序,需要传入by参数,说明按哪一列的数据进行排序。

按行one的数据进行降序排序。
排序时,缺失值默认放到末尾。
obj = pd.Series([4, np.nan, 7, np.nan, -3, 2])
obj.sort_values()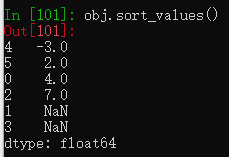
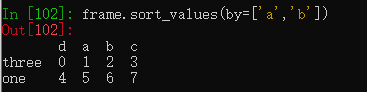
DataFrame若要根据多个索引进行排序,传入列表即可。
Series和DataFrame的rank方法,为各组分配一个平均排名。
obj = pd.Series([7, -5, 7, 4, 2, 0, 4])
obj.rank()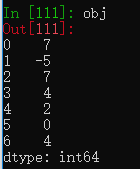

返回的结果是数据在Series中的升序排名。
创建一个Series,其中有两个元素7,按升序排序这两个元素排在6、7位,平均值是6.5。
传入参数method='first',如果有相同值,则按值出现的顺序排序。
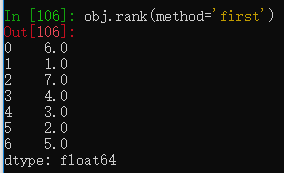
若传入method='max'参数,则有相同数据时会选择最大的顺序。
有两个7,排序为6、7,结果两个都会显示为7。

传入参数ascending=False可以降序排序。
如果是DataFrame,默认情况下是对列进行排序,传入参数axis='columns'则对行进行排序。
method方法可以设置的值:
average,默认的取相同数据的平均值排名
min,取最小排名
max,取最大排名
first,相同元素按出现顺序排序
dense,类似min,但排名总是在组间增加1,而不是族中相同的元素数。


带有重复标签的轴索引
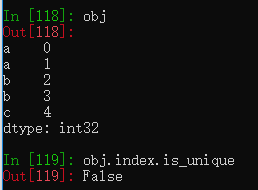
obj = pd.Series(range(5), index=['a', 'a', 'b', 'b', 'c'])
obj.index.is_unique创建带重复索引的Series,通过is_unique属性可以判断index是否唯一。
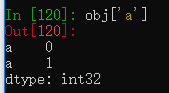
使用重复索引获取数据,返回多个结果。
DataFrame中也有类似情况,创建一个含重复行索引
df = pd.DataFrame(np.random.randn(4, 3), index=['a', 'a', 'b', 'b'])
df.loc['b']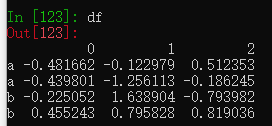

汇总和计算描述统计
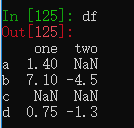
df = pd.DataFrame([[1.4, np.nan], [7.1, -4.5],
[np.nan, np.nan], [0.75, -1.3]],
index=['a', 'b', 'c', 'd'],
columns=['one', 'two'])
df.sum()创建一个DataFrame,使用sum()函数统计每列的总和,返回一个Series

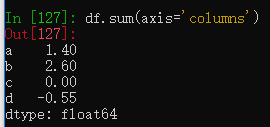
传入axis='columns'则会对行进行求和。
NA值会被自动排除,通过skipna选项可以进行设置。

常用参数
axis,轴选择
skipna,排除缺失值,默认是True
level,如果轴是层次化索引的,根据level分组。
有些方法返回的是间接统计,如idxmax()方法寻找列中最大值的行。

列one中b行的数值最大,列two中d行的数值最大。
另一种方法是累积性的,如cumsum()是累积求和函数
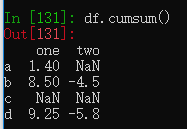
对列one、two进行累积求和。
describe()函数一次性产生多个汇总统计

非数值型数据也能使用describe()
obj = pd.Series(['a', 'a', 'b', 'c'] * 4)
obj.describe()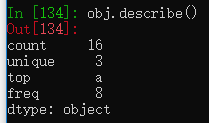
描述统计常用方法
count,计算非NA值的数量。
describe,对列进行汇总统计。
min、max,计算最小最大值。
argmin、argmax,计算能获取到最小值和最大值的索引位置(整数)
idxmin、idxmax,计算能获取到最小值和最大值的索引标签。
quantile,计算样本的分位数(0到1)
sum,求和
mean,平均数
median,计算中位数
mad,根据平均值计算平均绝对离差
var,计算样本方差
std,计算样本标准差
skew,计算样本值的偏度(三阶矩)
kurt,计算样本值的风度(四阶矩)
cumsum,累计和
cummin、cummax,样本值的累计最大值和累计最小值
cumprod,累计积
diff,计算一阶差分
pct_change,计算百分数变化
相关系数和协方差
df = pd.DataFrame({'A':np.random.randint(1, 100, 10),
'B':np.random.randint(1, 100, 10),
'C':np.random.randint(1, 100, 10)})
df.corr()创建一个DataFrame,每列的数据都是从1~100中随机取10个组成的,然后对每两列间进行相关系数计算。

若要对指定列进行相关性计算。
![]()
cov方法是计算协方差
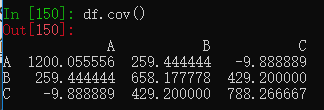
corrwith计算指定列的相关性。

三列每列对A进行相关性计算。
唯一值、值计数及成员资格
创建一个包含重复值的Series,通过unique函数可以除去重复值,返回唯一值的数组。
obj = pd.Series(['c', 'a', 'd', 'a', 'a', 'b', 'b', 'c', 'c'])
uniques = obj.unique()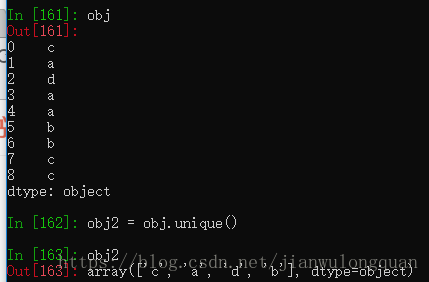
再使用sort()方法可以对结果进行排序。

value_counts用于统计各值出现的频率,结果是降序排序的,可以关闭排序功能。


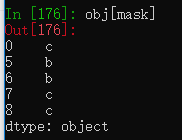
Series和DataFrame的isin方法可以判断Series和DataFrame中是否存在指定元素,返回一个布尔型数组。

将布尔型数组作为索引参数可以筛选数据。
还有一个Index.get_indexer方法,提供一个索引数组。
to_match = pd.Series(['c', 'a', 'b', 'b', 'c', 'a'])
unique_vals = pd.Series(['c', 'b', 'a'])
pd.Index(unique_vals).get_indexer(to_match)![]()
第一个元素c在索引数组的位置0上,第二个元素a在索引数组的位置2上。

data = pd.DataFrame({'Qu1': [1, 3, 4, 3, 4],
'Qu2': [2, 3, 1, 2, 3],
'Qu3': [1, 5, 2, 4, 4]})
result = data.apply(pd.value_counts).fillna(0)创建一个DataFrame,通过apply(pd.value_counts),将数据中的唯一值作为行标签,数据区域显示的是行标签对应的数值在列中出现的次数。
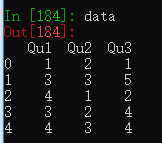
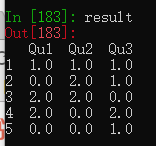
如result的第一行行标签是1,在Qu1列中数值1出现了1次,第二行的行标签是2,在Qu1列中数值2出现了0次,所以显示为0。
此学习笔记主要内容出自https://www.jianshu.com/p/161364dd0acf