Tensorflow——使用预训练模型进行 猫狗 图像分类
前言
预训练模型顾名思义就是使用别人已经训练好的模型参数放到自己的任务里面进行特定任务的微调。这里的模型参数包括:神经网络的结构、神经网络的权值参数。
本博客将尝试使用预训练模型进行猫狗分类。
代码地址:https://github.com/jmhIcoding/dogsVScats.git
实验所用数据集及工具
数据集
本实验使用实验数据基于kaggle Dogs vs. Cats 竞赛提供的官方数据集,数据集可在百度网盘中进行下载:
链接:https://pan.baidu.com/s/13hw4LK8ihR6-6-8mpjLKDA 密码:dmp4。
数据集的目录划分如下:
dataset
|— train
|— dogs
|— cats
|— validation
|— dogs
|— cats
将数据集划分为训练集(training dataset)和验证集(validation dataset),均包含dogs和cats两个目录,且每个目录下包含与目录名类别相同的RGB图。数据集共25000张照片,其中训练集猫狗照片各10000张,验证集猫狗照片各2500张。(注:可根据计算资源情况自己调整训练集和验证集的大小,但最好按比例调整)
原始数据集如图3、4、5、6所示。

图3

图4

图5

图6
Slim工具
Slim是 TensorFlow 中一个用来构建、训练、评估复杂模型的轻量化库,TF-Slim 模块可以和 TensorFlow 中其它API混合使用。参见:
https://github.com/tensorflow/models/tree/master/research/slim。
这里简要介绍Tensorflow Slim的代码结构:
- datasets/:定义一些训练时用的数据集,预先定义了4个数据集:MNIST、CIFAR-10、Flowers、ImageNet,如果需要训练自己的数据,则可以在datasets文件夹中定义。
- nets/:定义了一些常用的网络结构如AlexNet、VGG16、Inception系列等。
- preprocessing/:定义了一些图片预处理和数据增强方法。
- train_image_classifer.py:训练模型的入口代码。
- eval_image_claasifer.py:验证模型的入口代码。
实验步骤与方法
对猫狗照片识别分类的卷积神经网络模型可以自行设计,本实验指导书给出的方法是利用Slim工具包中预定义好的网络结构并进行微调的方法实现,具体是基于nets文件夹中预定义好的Inception V3进行微调。
处理数据集,转换为TFRecord
- 下载数据集,把train文件夹的25000个图片中,随机取出2500个猫和2500个狗放到train同级目录下的validation目录。
- 编写TFRecord生成函数
生成train和validdation的TF_Record文件,代码见 convert_kaggle.py
TF_Record文件是tensorflow里面结构化组织训练数据的一种方法,这种方法的本质就是把分散在磁盘中的训练样本集中起来放在一起,使得模型读取数据更加快速。
Slim框架里面使用的数据格式默认就需要先转换为TF_Record。
对于 图片分类 而言,convert_kaggle代码是可以复用的。
只需要根据需要把代码中feature做相应的填充即可:
···
example = tf.train.Example(features=tf.train.Features(
feature={
'image/height': _int64_feature(height), #图片高度
'image/width': _int64_feature(width), #图片宽度
'image/colorspace': _bytes_feature(colorspace),
'image/channels': _int64_feature(channels),#通道个数
'image/class/label': _int64_feature(label),#label
'image/class/text': _bytes_feature(text),
'image/format': _bytes_feature(image_format),#'JPEG'
'image/filename': _bytes_feature(os.path.basename(filename)), #文件名
'image/encoded': _bytes_feature(image_buffer)#图片的内容
}
)
)
···
#coding:utf-8
__author__ = 'jmh081701'
import numpy as np
import tensorflow as tf
import sys
import os
def _int64_feature(value):
if not isinstance(value, list):
value = [value]
return tf.train.Feature(int64_list=tf.train.Int64List(value=value))
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _convert_example(filename, image_buffer, label, text, height, width):
colorspace = 'RGB'.encode()
channels = 3
image_format = 'JPEG'.encode()
if not isinstance(label,int):
label=int(label)
if not isinstance(text,bytes):
text = text.encode()
if not isinstance(filename,bytes):
filename = filename.encode()
example = tf.train.Example(features=tf.train.Features(
feature={
'image/height': _int64_feature(height), #图片高度
'image/width': _int64_feature(width), #图片宽度
'image/colorspace': _bytes_feature(colorspace),
'image/channels': _int64_feature(channels),#通道个数
'image/class/label': _int64_feature(label),#label
'image/class/text': _bytes_feature(text),
'image/format': _bytes_feature(image_format),#'JPEG'
'image/filename': _bytes_feature(os.path.basename(filename)), #文件名
'image/encoded': _bytes_feature(image_buffer)#图片的内容
}
)
)
return example
def convert_kaggle_image(datadir,usage='train'):
_decode_jpeg_data = tf.placeholder(dtype=tf.string)#place holder
_decode_jpeg = tf.image.decode_jpeg(_decode_jpeg_data, channels=3)
with tf.Session() as sess:
for root,subdirs,files in os.walk(datadir):
counter = 0
shard = 5
each_shard=int(len(files)/shard)
writers=[0,1,2,3,4]
writers[0] = tf.python_io.TFRecordWriter('.\\dogsVScats_%s_0-of-5.tfrecord'%usage)
writers[1] = tf.python_io.TFRecordWriter('.\\dogsVScats_%s_1-of-5.tfrecord'%usage)
writers[2] = tf.python_io.TFRecordWriter('.\\dogsVScats_%s_2-of-5.tfrecord'%usage)
writers[3] = tf.python_io.TFRecordWriter('.\\dogsVScats_%s_3-of-5.tfrecord'%usage)
writers[4] = tf.python_io.TFRecordWriter('.\\dogsVScats_%s_4-of-5.tfrecord'%usage)
for file in files:
writer = writers[int(counter/each_shard)]
label = 0 if file.split('.')[0] == 'cat' else 1 #0 is cat,while 1 is dog
filename=root+"\\"+file
# Read the image file, mode:read and binary
image_data_raw=tf.gfile.GFile(filename,"rb").read()
# Convert 2 tensor,转换的目的是为了提取height和width,也可以使用PIL库来转换
image= sess.run(_decode_jpeg,feed_dict={_decode_jpeg_data:image_data_raw})
height=image.shape[0]
width =image.shape[1]
example=_convert_example(filename,image_buffer=image_data_raw,label=label,text="",height=height,width=width)
writer.write(example.SerializeToString())
counter+=1
print("Finish:%s"%str(counter/len(files)))
sys.stdout.flush()
writers[0].close()
writers[1].close()
writers[2].close()
writers[3].close()
writers[4].close()
if __name__ == '__main__':
convert_kaggle_image(datadir=r"G:\bdndisk\kaggle\train\validation",usage='validation')
convert_kaggle_image(datadir=r"G:\bdndisk\kaggle\train\train",usage='train')
运行脚本,将生成10个tfrecord文件,其中有5个是训练集另外5个是验证集。

安装TF-slim识别库
安装TF-slim 图像识别库
Tensorflow 1.0以后就支持TF-Slim了,但是要使用TF-Slim进行图像分类就还得安装TF-Slim image models library.
安装方法:
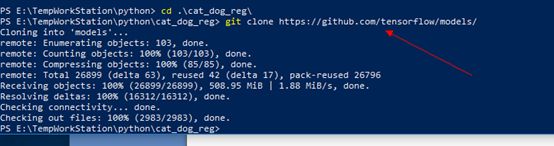
git clone https://github.com/tensorflow/models/
创建数据库声名文件
在刚刚clone的目录下的models\research\slim\datasets新建一个dogVScats.py文件,把flowers.py内容拷贝下来。修改其中的内容:
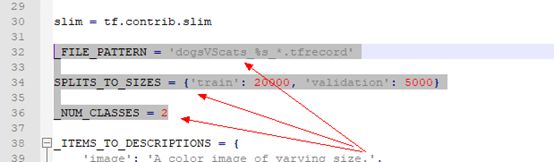
主要是_FILE_PATTERN,SPLITS_TO_SIZES以及_NUM_CLASSES 三个值。
_FILE_PATTERN 用于表示刚刚生成的TF_RECORD文件的文件名的格式,%s_* 带了通配符号。
SPLITES_TO_SIZES表示训练集和测试集的大小。
_NUM_CLASSES表示分类类别数目。
dogVScats内容:https://github.com/jmhIcoding/dogsVScats/blob/master/dogsVScats.py
在dataset_factory.py注册dogsVScats
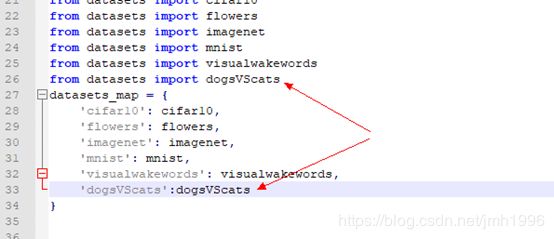
注意箭头指向的地方是需要修改的。
修改后的dataset_factory.py: https://github.com/jmhIcoding/dogsVScats/blob/master/dataset_factory.py
训练模型:
训练脚本
见 main.py
__author__ = 'jmh081701'
import os
cmd="python train_image_classifier.py --train_dir=dogsVScats/train_dir " \
"--dataset_name=dogsVScats --dataset_split_name=train " \
"--dataset_dir=dogsVScats/data --model_name=inception_v3 " \
"--checkpoint_path=dogsVScats/pretrained/inception_v3.ckpt " \
"--checkpoint_exclude_scopes=InceptionV3/Logits,InceptionV3/AuxLogits " \
"--trainable_scopes=InceptionV3/Logits,InceptionV3/AuxLogits " \
"--max_number_of_steps=25000 --batch_size=32 " \
"--learning_rate=0.001 " \
"--learning_rate_decay_type=fixed " \
"--save_interval_secs=300 --save_summaries_secs=2 " \
"--log_every_n_steps=10 " \
"--optimizer=rmsprop --weight_decay=0.00004"
if __name__ == '__main__':
os.system(cmd)
其中trainable_scopes指定只训练Logits和AuxLogits部分,checkpoint_exclue_scope则是说明Logits和AuxLogits不要保存,这是因为InceptionV3的顶层是包含1001个神经元,而我们的分类只是二分类。
训练模型过程:
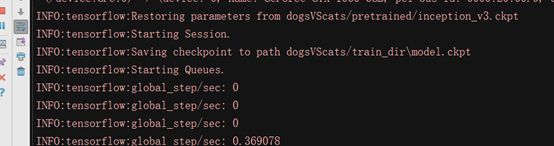
使用tensorboard查看训练过程
![]()
Losses的结果图: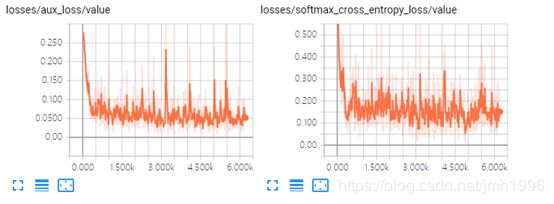
训练过程中错误解决
报错1:
tensorflow.python.framework.errors_impl.InvalidArgumentError: Cannot assign a device for operation 'InceptionV3/Predictions/Softmax': Could not satisfy explicit device specification '/device:GPU:0' because no supported kernel for GPU devices is available.
[[Node: InceptionV3/Predictions/Softmax = Softmax[T=DT_FLOAT, _device="/device:GPU:0"](InceptionV3/Predictions/Reshape)]]
解决方法:
把slim文件夹下的train_image_classfier.py最后几行改掉:
###########################
# Kicks off the training. #
###########################
session_config= tf.ConfigProto(allow_soft_placement=True)
slim.learning.train(
train_tensor,
logdir=FLAGS.train_dir,
master=FLAGS.master,
is_chief=(FLAGS.task == 0),
init_fn=_get_init_fn(),
summary_op=summary_op,
number_of_steps=FLAGS.max_number_of_steps,
log_every_n_steps=FLAGS.log_every_n_steps,
save_summaries_secs=FLAGS.save_summaries_secs,
save_interval_secs=FLAGS.save_interval_secs,
sync_optimizer=optimizer if FLAGS.sync_replicas else None,
session_config=session_config
)
报错2:
InvalidArgumentError (see above for traceback): Assign requires shapes of both tensors to match. lhs shape= [2] rhs shape= [1001]
解决方法:
检查 --checkpoint_exclude_scopes 参数名以及参数值是否正确,本人一开始把exclude写成了execlue就报错了。
验证(测试)模型
因为Kagggle给的数据里面test数据是没有标注好的,因此我们得从train中划分一部分数据出来做验证或测试用,这部分数据就是刚刚划分出来的validation。
在训练25000个step,共计1小时后,我们对模型进行验证。
验证脚本:
代码见main.py
cmdValid="python eval_image_classifier.py " \
"--checkpoint_path=dogsVScats/train_dir " \
"--eval_dir=dogsVScats/eval_dir " \
"--dataset_name=dogsVScats " \
"--dataset_split_name=validation " \
"--dataset_dir=dogsVScats/data " \
"--model_name=inception_v3"
if __name__ == '__main__':
#os.system(cmd)
os.system(cmdValid)
验证结果:

在训练25000个step后,在5000个图片中的验证结果为:
Recall_5: 100 %,说明所有的狗样本都被找到.
Accuracy:95.54%,
实验总结
本实验通过猫狗分类的实例来体会如何使用Slim框架来对预训练模型进行微调。使用Slim框架进行微调的主要步骤就是提前准备好TF-Record的训练集验证集数据,同时在datasets目录下注册新的数据集。
剩下的模型微调就只是调用train_image_classfier.py脚本,然后根据需要设置不同参数而已。
一开始本人的疑惑在于InceptionV3都是一个1001分类的模型,如何使用这个预训练好的模型对猫狗二分类进行分类呢?后面发现是在train_image_classfier脚本运行过程中指定trainable_scopes和checkpoint_exclude_scope来实现的。正如官方文档写的那样:
When fine-tuning a model, we need to be careful about restoring checkpoint weights. In particular, when we fine-tune a model on a new task with a different number of output labels, we wont be able restore the final logits (classifier) layer. For this, we’ll use the --checkpoint_exclude_scopes flag. This flag hinders certain variables from being loaded. When fine-tuning on a classification task using a different number of classes than the trained model, the new model will have a final ‘logits’ layer whose dimensions differ from the pre-trained model. For example, if fine-tuning an ImageNet-trained model on Flowers, the pre-trained logits layer will have dimensions [2048 x 1001] but our new logits layer will have dimensions [2048 x 5]. Consequently, this flag indicates to TF-Slim to avoid loading these weights from the checkpoint.
当微调模型的时候,我们要十分慎重的选择载入哪些权重。因为猫狗分类是2个输出,而InceptionV3是1001个输出,我们不能载入最后一个分类层的参数,而—checkpoint_exclude_scopes就是起得这个作用,它会显式在载入预训练模型时不去加载最后一层的值,而是使用slim的初始值。