Python数据挖掘-回归分析
本文用Python实现数据回归,包括线性回归(一元线性+多元线性回归)、Logistics回归。主要通过实验验证,部分例题来自网络。
注:更多资源及软件请W信关注“学娱汇聚门”
一、一元线性回归


举例及代码实现:
汽车卖家做电视广告数量与卖出的汽车数量:
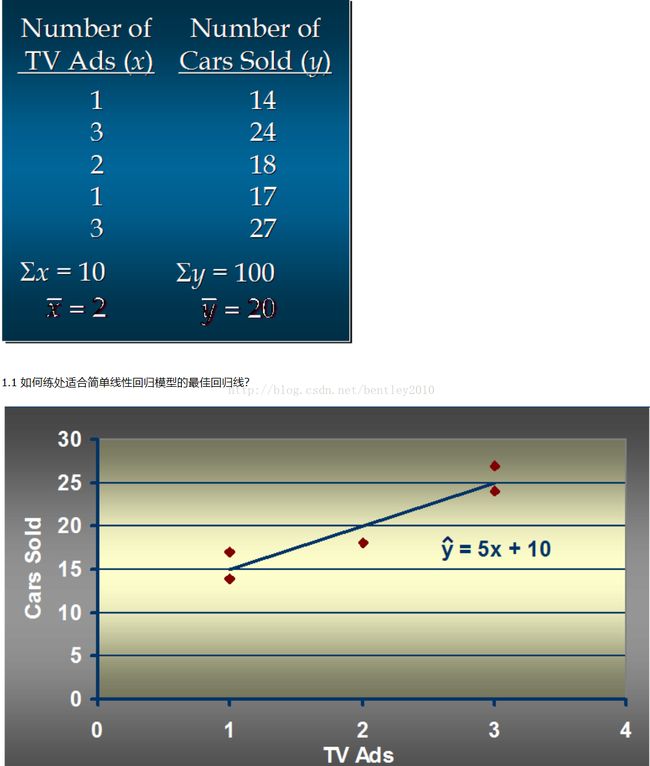



代码:



实例:
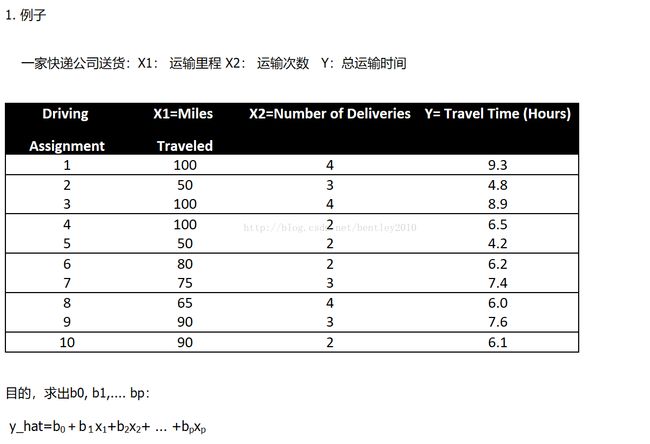
Python代码:
from numpy import genfromtxt
import numpy as np
from sklearn import datasets, linear_model
dataPath = r"D:\MaiziEdu\DeepLearningBasics_MachineLearning\Datasets\Delivery.csv"
deliveryData = genfromtxt(dataPath, delimiter=',')
print "data"
print deliveryData
X = deliveryData[:, :-1]
Y = deliveryData[:, -1]
print "X:"
print X
print "Y: "
print Y
regr = linear_model.LinearRegression()
regr.fit(X, Y)
print "coefficients"
print regr.coef_
print "intercept: "
print regr.intercept_
xPred = [102, 6]
yPred = regr.predict(xPred)
print "predicted y: "
print yPred
三、Logistic回归:
3.1 Logistic回归原理
线性回归模型通常是处理因变量是连续变量的问题,如果因变量是定性变量,线性回归模型就不再适用了,需采用逻辑回归模型解决。
逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。
二分类问题的概率与自变量之间的关系图形往往是一个S型曲线,如图所示,采用的Sigmoid函数实现。



import matplotlib.pyplot as plt
import numpy as np
def Sigmoid(x):
return 1.0 / (1.0 + np.exp(-x))
x= np.arange(-10, 10, 0.1)
h = Sigmoid(x) #Sigmoid函数
plt.plot(x, h)
plt.axvline(0.0, color='k') #坐标轴上加一条竖直的线(0位置)
plt.axhspan(0.0, 1.0, facecolor='1.0', alpha=1.0, ls='dotted')
plt.axhline(y=0.5, ls='dotted', color='k')
plt.yticks([0.0, 0.5, 1.0]) #y轴标度
plt.ylim(-0.1, 1.1) #y轴范围
plt.show()
由于篇幅有限,逻辑回归构造损失函数J函数,求解最小J函数及回归参数θ的方法就不在叙述,原理和前面小节一样,请读者下去深入研究。
3.2LogisticRegression回归算法
LogisticRegression回归模型在Sklearn.linear_model子类下,调用sklearn逻辑回归算法步骤比较简单,即:
(1) 导入模型。调用逻辑回归LogisticRegression()函数。
(2) fit()训练。调用fit(x,y)的方法来训练模型,其中x为数据的属性,y为所属类型。
(3) predict()预测。利用训练得到的模型对数据集进行预测,返回预测结果。
代码如下:
- from sklearn.linear_model import LogisticRegression #导入逻辑回归模型
- clf = LogisticRegression()
- print clf
- clf.fit(train_feature,label)
- predict['label'] = clf.predict(predict_feature)
输出结果如下:
- LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,
- intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,
- penalty='l2', random_state=None, solver='liblinear', tol=0.0001,
- verbose=0, warm_start=False)
其中,参数penalty表示惩罚项(L1、L2值可选。L1向量中各元素绝对值的和,作用是产生少量的特征,而其他特征都是0,常用于特征选择;L2向量中各个元素平方之和再开根号,作用是选择较多的特征,使他们都趋近于0。);C值的目标函数约束条件:s.t.||w||1 3.3. 分析鸢尾花数据集 下面将结合Scikit-learn官网的逻辑回归模型分析鸢尾花示例,给大家进行详细讲解及拓展。由于该数据集分类标签划分为3类(0类、1类、2类),很好的适用于逻辑回归模型。 在Sklearn机器学习包中,集成了各种各样的数据集,包括前面的糖尿病数据集,这里引入的是鸢尾花卉(Iris)数据集,它是很常用的一个数据集。鸢尾花有三个亚属,分别是山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。 该数据集一共包含4个特征变量,1个类别变量。共有150个样本,iris是鸢尾植物,这里存储了其萼片和花瓣的长宽,共4个属性,鸢尾植物分三类。如表17.2所示: iris里有两个属性iris.data,iris.target。data是一个矩阵,每一列代表了萼片或花瓣的长宽,一共4列,每一列代表某个被测量的鸢尾植物,一共采样了150条记录。 输出如下所示: target是一个数组,存储了data中每条记录属于哪一类鸢尾植物,所以数组的长度是150,数组元素的值因为共有3类鸢尾植物,所以不同值只有3个。种类为山鸢尾、杂色鸢尾、维吉尼亚鸢尾。 从输出结果可以看到,类标共分为三类,前面50个类标位0,中间50个类标位1,后面为2。下面给详细介绍使用决策树进行对这个数据集进行测试的代码。 下列代码主要是载入鸢尾花数据集,包括数据data和标签target,然后获取其中两列数据或两个特征,核心代码为:X = [x[0] for x in DD],获取的值赋值给X变量,最后调用scatter()函数绘制散点图。 绘制散点图如图所示: 从图中可以看出,数据集线性可分的,可以划分为3类,分别对应三种类型的鸢尾花,下面采用逻辑回归对其进行分类预测。前面使用X=[x[0] for x in DD]获取第一列数据,Y=[x[1] for x in DD]获取第二列数据,这里采用另一种方法,iris.data[:, :2]获取其中两列数据(两个特征),完整代码如下: 下面作者对导入数据集后的代码进行详细讲解。 Z = lr.predict(np.c_[xx.ravel(), yy.ravel()]) 总结下:上述操作是把第一列花萼长度数据按h取等分作为行,并复制多行得到xx网格矩阵;再把第二列花萼宽度数据按h取等分,作为列,并复制多列得到yy网格矩阵;最后将xx和yy矩阵都变成两个一维数组,调用np.c_[]函数组合成一个二维数组进行预测。 Z = Z.reshape(xx.shape) plt.pcolormesh(xx, yy, Z, cmap=plt.cm.Paired) plt.scatter(X[:50,0], X[:50,1], color='red',marker='o', label='setosa') plt.scatter(X[:50,0], X[:50,1], color='red',marker='o', label='setosa') 回归算法作为统计学中最重要的工具之一,它通过建立一个回归方程用来预测目标值,并求解这个回归方程的回归系数。本篇文章详细讲解了逻辑回归模型的原理知识,结合Sklearn机器学习库的LogisticRegression算法分析了鸢尾花分类情况。更多知识点希望读者下来后进行拓展,也推荐大家从Sklearn开源知识官网学习最新的实例。 注:本文Logistic回归用了sklearn包,算法已经封装好了,如果想了解具体的实现方法,可以参考《机器学习实战》一书,或参考此博文是关于使用statesmodels的Logit函数: 1. 鸢尾花数据集
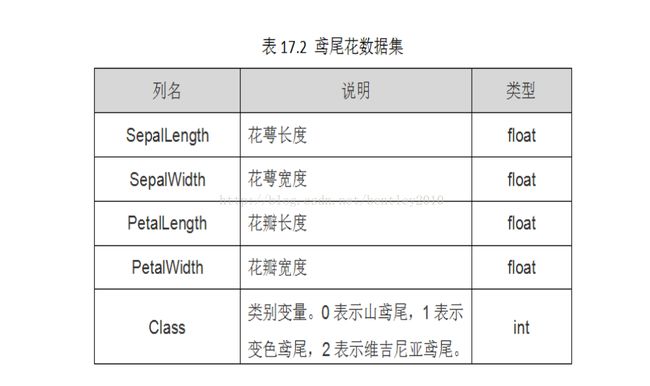
from sklearn.datasets import load_iris #导入数据集iris
iris = load_iris() #载入数据集
print iris.data
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
....
[ 6.7 3. 5.2 2.3]
[ 6.3 2.5 5. 1.9]
[ 6.5 3. 5.2 2. ]
[ 6.2 3.4 5.4 2.3]
[ 5.9 3. 5.1 1.8]]print iris.target #输出真实标签
print len(iris.target) #150个样本 每个样本4个特征
print iris.data.shape
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
150
(150L, 4L) print iris.target #输出真实标签
print len(iris.target) #150个样本 每个样本4个特征
print iris.data.shape
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
150
(150L, 4L)2. 散点图绘制
import matplotlib.pyplot as plt
import numpy as np
from sklearn.datasets import load_iris #导入数据集iris
#载入数据集
iris = load_iris()
print iris.data #输出数据集
print iris.target #输出真实标签
#获取花卉两列数据集
DD = iris.data
X = [x[0] for x in DD]
print X
Y = [x[1] for x in DD]
print Y
#plt.scatter(X, Y, c=iris.target, marker='x')
plt.scatter(X[:50], Y[:50], color='red', marker='o', label='setosa') #前50个样本
plt.scatter(X[50:100], Y[50:100], color='blue', marker='x', label='versicolor') #中间50个
plt.scatter(X[100:], Y[100:],color='green', marker='+', label='Virginica') #后50个样本
plt.legend(loc=2) #左上角
plt.show()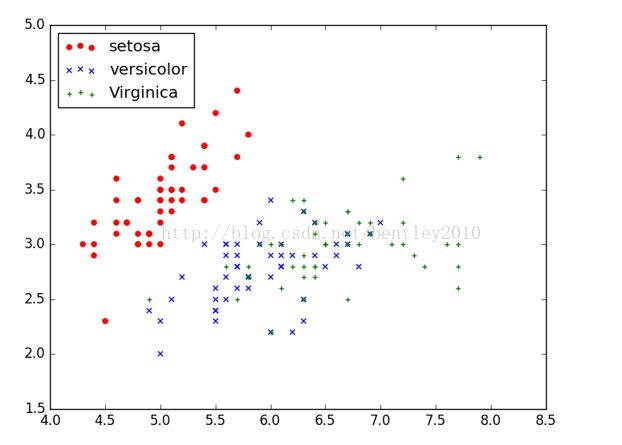
3. 逻辑回归分析
lr = LogisticRegression(C=1e5)
lr.fit(X,Y)
初始化逻辑回归模型并进行训练,C=1e5表示目标函数。
x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
获取的鸢尾花两列数据,对应为花萼长度和花萼宽度,每个点的坐标就是(x,y)。 先取X二维数组的第一列(长度)的最小值、最大值和步长h(设置为0.02)生成数组,再取X二维数组的第二列(宽度)的最小值、最大值和步长h生成数组, 最后用meshgrid函数生成两个网格矩阵xx和yy,如下所示:
调用ravel()函数将xx和yy的两个矩阵转变成一维数组,由于两个矩阵大小相等,因此两个一维数组大小也相等。np.c_[xx.ravel(), yy.ravel()]是获取矩阵,即:
调用predict()函数进行预测,预测结果赋值给Z。即:
调用reshape()函数修改形状,将其Z转换为两个特征(长度和宽度),则39501个数据转换为171*231的矩阵。Z = Z.reshape(xx.shape)输出如下:
调用pcolormesh()函数将xx、yy两个网格矩阵和对应的预测结果Z绘制在图片上,可以发现输出为三个颜色区块,分布表示分类的三类区域。cmap=plt.cm.Paired表示绘图样式选择Paired主题。输出的区域如下图所示:
调用scatter()绘制散点图,第一个参数为第一列数据(长度),第二个参数为第二列数据(宽度),第三、四个参数为设置点的颜色为红色,款式为圆圈,最后标记为setosa。
输出如下图所示,经过逻辑回归后划分为三个区域,左上角部分为红色的圆点,对应setosa鸢尾花;右上角部分为绿色方块,对应virginica鸢尾花;中间下部分为蓝色星形,对应versicolor鸢尾花。散点图为各数据点真实的花类型,划分的三个区域为数据点预测的花类型,预测的分类结果与训练数据的真实结果结果基本一致,部分鸢尾花出现交叉plt.scatter(X[:50,0], X[:50,1], color='red',marker='o', label='setosa')
调用scatter()绘制散点图,第一个参数为第一列数据(长度),第二个参数为第二列数据(宽度),第三、四个参数为设置点的颜色为红色,款式为圆圈,最后标记为setosa。
输出如下图所示,经过逻辑回归后划分为三个区域,左上角部分为红色的圆点,对应setosa鸢尾花;右上角部分为绿色方块,对应virginica鸢尾花;中间下部分为蓝色星形,对应versicolor鸢尾花。散点图为各数据点真实的花类型,划分的三个区域为数据点预测的花类型,预测的分类结果与训练数据的真实结果结果基本一致,部分鸢尾花出现交叉
调用scatter()绘制散点图,第一个参数为第一列数据(长度),第二个参数为第二列数据(宽度),第三、四个参数为设置点的颜色为红色,款式为圆圈,最后标记为setosa。
输出如下图所示,经过逻辑回归后划分为三个区域,左上角部分为红色的圆点,对应setosa鸢尾花;右上角部分为绿色方块,对应virginica鸢尾花;中间下部分为蓝色星形,对应versicolor鸢尾花。散点图为各数据点真实的花类型,划分的三个区域为数据点预测的花类型,预测的分类结果与训练数据的真实结果结果基本一致,部分鸢尾花出现交叉.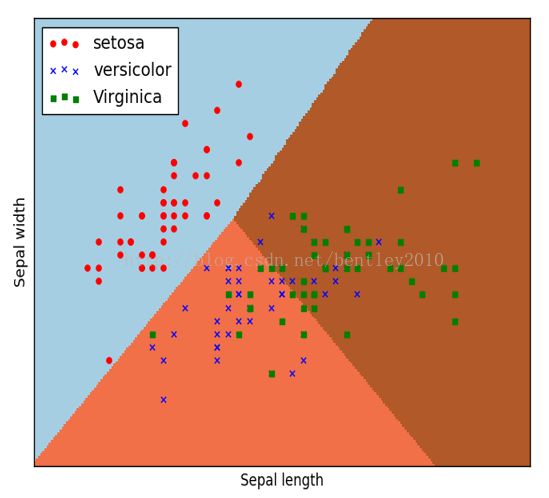
Python实现逻辑回归(Logistic Regression in Python) :