【SDCC 2016·杭州站】9月22日大数据实战专场精彩呈现
【SDCC 现场报道】2016年9月22日-23日,由CSDN重磅打造的大数据核心技术与实战峰会、互联网应用架构实战峰会在杭州隆重举行。这两场峰会大牛讲师来自唯品会、小米、蘑菇街、饿了么、有赞、游族、echo、In、万达、百度、苏宁、蚂蚁金服、京东、网易云、 1药网、 腾讯、美团等知名互联网公司,共同探讨海量数据下的应用监控系统建设、异常检测的算法和实现、大数据基础架构实践、敏捷型数据平台的构建及应用、音频分析的机器学习算法应用等内容,以及高可用/高并发/高性能系统架构、电商架构、分布式架构等话题与技术。
在第一天的大数据核心技术与实战峰会上,由来自唯品会、小米、蘑菇街、饿了么、有赞、游族、echo、In、万达的资深专家分享了各自在大数据领域丰富的实战经验。

上午9:00,大数据核心技术与实战峰会正式开始。首先,由本次会议的独家合作伙伴UCloud的杭州分公司架构部负责人林超发表致辞,他介绍了大数据市场火热的发展前景,并预祝本次大会圆满成功。

随后,本场峰会主持人七牛云技术总监陈超对本次会议主题及内容专家做了介绍,在他的引导下,与会者一同简单回顾了SDCC往届大会及峰会的精彩历程,SDCC成都站之行的火爆让现场观众对本次大会的顺利展开更是充满期待。

唯品会平台架构部高级架构师 姚捷:大型互联网公司海量数据下的应用监控系统建设
唯品会平台架构部高级架构师姚捷在本次架构峰会上带来的是《大型互联网公司海量数据下的应用监控系统建设》主题分享,他结合唯品会面对支撑海量数据和新业务的挑战的实践,探索大型互联网公司海量数据下的应用监控系统建设之道。主要从大型互联网公司应用监控系统的几大组成部分、应用监控系统的架构实践、如何应对海量的数据、如何实现治理、如何实现自监控这五个角度展开,分享了唯品会在经历了Logview之痛后,转而寻求新方向,独立研发应用监控系统的过程中,积累的丰富经验以及当中踩过的一些坑。

首先,姚捷阐述了在选择自建平台的过程中所考虑的因素:
- 系统复杂
- 海量数据
- 自建服务化体系监控
- 高度可治理
- 快速接入/升级便捷
- 灵活的告警策略/高效告警
- 与公司体系无缝对接

此外,他还分析了完整的全链路监控系统
- 数据埋点/采集
- 指标计算
- 指标存储/查询/展现
- 调用链存储/查询/展现
- 告警/问题定位
- 自监控
- 治理
小米商业产品部技术总监 宋强:小米广告大数据与算法实践
小米商业产品部技术总监宋强分享了《小米广告大数据与算法实践》的主题演讲,主要从小米大数据和小米广告平台、小米广告大数据应用实践,以及经验总结这三个方面进行分享,分别介绍大数据在小米广告平台的各种实践,包括收入提升、广告主优化、用户体验优化等。

首先,他在第一个部分讲解了小米广告平台的架构:

在演讲最后,宋强结合前面的实践和踩坑分享,做了一些经验总结:
特征工程
业务相关的用户行为特征一般来说最有效
- 用户在商店的安装列表 vs 用户的年龄性别
保持数据的“原汁原味”,二次加工反而容易丢失信息
- 用户浏览记录 vs 用户画像兴趣标签
组合特征才能发挥最大威力
算法模型
线性模型+组合特征效果很好
- 离线实验了FM等非线性模型,效果不明显
线性模型+深度模型是未来的方向
- 正在线下实验,已经看到一些效果
蘑菇街实时计算平台经理 黄大鹏:蘑菇街实时数据平台实践
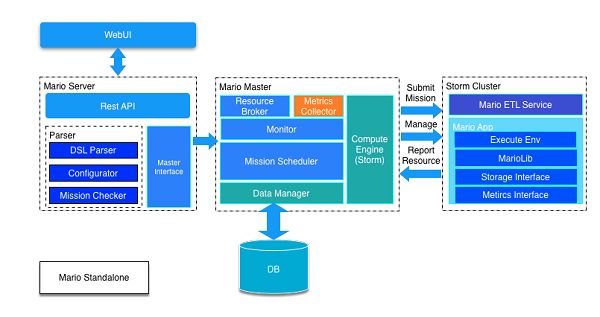
蘑菇街实时计算平台经理黄大鹏在本次演讲中呈现的分享主题是《蘑菇街实时数据平台实践》。着眼于蘑菇街的实时数据平台,结合实时数仓的建设经验,分析其建设中涉及的关键技术选型思路与,主要分享内容涉及蘑菇街实时计算平台Mario,数据链路的治理和不同的应用场景的介绍。

鉴于Storm任务开发维护难度相对较大、统计逻辑可读性差、大量统计任务,以及基础统计方法非常相似等因素,Mario流式计算平台应运而生。黄大鹏在演讲过程中对其系统架构进行了分析:
在介绍最后一部分内容时,他阐述了实时数仓管理的要点:
- ETL的管理
- 数据接口层
- 数据质量监控
- 日志打点
其中,实时数据ETL包括:
- 大日志拆解成小日志,各取所需,合并同类项
- 非结构化转为结构化
- 日志质量监控
- 生存周期管理
同时总结了日志打点的经验:
- 顶层设计,统一认知;
- 合作共建,及时见效;
- 接口人制度。
饿了么数据架构技术经理 倪增光:饿了么大数据基础架构实践
饿了么数据架构技术经理倪增光在本次演讲中带来《饿了么大数据基础架构实践》的主题分享,结合“饿了么”数据团队的发展历程,侧重分享其数据架构在离线、实时和工具方面的建设经验。

首先,他详细讲解了“饿了么”的离线架构和实时架构:


随后,他还围绕平台工具展开了一系列分享:
查询平台
- 多引擎
- 数据操作
- 底层策略
ETL调度
- 任务
- 底层工具support
- 前端操作
- 后端调度优化
实时平台RDP
- 集群容量
- 任务管理
- 任务日志
- 常用组件封装
至此,本次峰会上半场在热烈的氛围中暂告一段落,接连超过三个小时的分享并未影响与会者的参与热情,相反,大牛们的精彩分享反而再一次点燃了大家的情绪,现场互动气氛一度高涨。

短暂的休息之后,我们迎来了本场大数据核心技术与实战峰会的下半场。下午13:30,大数据核心技术与实战峰会在七牛云技术总监陈超的主持下继续进行。来自有赞、游族、echo、In、万达等资深专家分享在大数据领域的众多实践经验。
午后的困顿也在讲师们的幽默调动下一扫而空,上半场的互动热情延得以延续,一问一答间,尽是技术灵感的碰撞,亮点纷呈,干货不断。
有赞大数据团队负责人 洪斌:有赞大数据实践: 敏捷型数据平台的构建及应用
有赞大数据团队负责人洪斌带来《敏捷型数据平台的构建及应用》的主题演讲,从数据仓库模型与工具、数据仓库与数据分析、数据平台的敏捷模式、数据平台与信息检索等方面入手,为观众呈现了一个接地气的,在数据运营和研发效率上都能发挥作用的大数据平台。

首先,洪斌介绍了有赞数据平台的设计思路和方法,探讨了与此相关的一系列问题,包括我们为什么要设计数据仓库?数据仓库如何适应业务的变化?在数据的易用性方面有哪些措施?随后,他介绍了构建在数据仓库上的BI系统及其应用,以及大数据平台在搜索引擎方面的实践。
在讲解数仓模型设计总体架构的过程中,他还特别介绍了采用的数据分析工具,并提供了数据分析各种工具的对比列表,同时指出其中最常用的当属即席查询:

数据分析工具
- 即席查询工具
- 多维分析工具
- 搜索分析工具
- 报表系统
即席查询
- 使用者: 数据分析人员
- SQL模式
- 特点
- 专业
- 迅速
- 挑战
- 懂数据
- 懂业务

游族网络运维开发经理 姚仁捷:Machine Learning in Anomaly Detection
游族网络运维开发经理 姚仁捷分享了《Machine Learning in Anomaly Detection》的主题分享。正式开始演讲之前,他以诙谐的口吻和在座观众分享了自己的日常,成功调动了大家的情绪,活跃了现场气氛。随后,由一组图片引入“异常”——“正常”的逻辑关系分析,引用《Practical Machine Learning》一书中的观点,指出定位异常的前提是定义何为正常,同时分享了两个等式:
- Normals = Patterns
- Normals = Models
发现问题、解决问题是运维永恒不变的两个主题。而如何发现问题,是其中的难点和重点。运维收集的数据可能数以百万计,如何从其中快速、准确地发现问题(即异常检测)正是本次演讲的主要内容。

演讲有三个部分,首先从更加抽象、一般性的角度介绍异常本身以及异常检测的定义。
然后,从“静态阈值法”开始,介绍多种异常检测的算法和实现,希望能通过更数学的方式,让大家对目前流行的几种异常检测方法的优缺点有所了解。
在这一部分提供了重建的误差分析图,以及误差的正态分布表:


最后一部分会着重介绍使用机器学习的方法,介绍一些对异常检测有很大提升的算法,通过真实数据和例子,演示机器学习对于异常检测的帮助。由深入浅的分享过程,正对应了他在演讲中多次笑言的那一句“超简单”。
echo数据组算法工程师 陈健:echo探索个性化推荐和版权识曲之路
echo数据组算法工程师陈健带来《echo探索个性化推荐和版权识曲之路》主题分享,从echo个性化推荐和echo音乐分析两方面展开,分析如何处理隐式音乐App等隐式数据来进行矩阵分解、如何在Spark上并行logistic matrix factorization来处理超大的稀疏矩阵、音乐分析综述,以及如何通过频谱抽取音频本地特征并根据深度学习等算法学习全局音频的特征。

首先,他具体阐释了通过App用户的播放、喜欢、分享、下载、评论等行为隐式数据,使用logistic matrix factorization模型,获取用户的特征向量和音乐的特征向量的方法,并对隐式反馈数据做了介绍:
隐式反馈数据
特征
- 无负反馈
- 反馈数据存在多种维度
- 数据存在噪音
- 数据大小不能代表用户的喜好程度
观测值
- fongshi
此外,为了检测用户上传的歌曲是否属于未收录版权的歌曲,通过分析音乐的音频,进行频谱变换以及特征学习,生成对应的音频指纹。然后根据音频指纹判断用户上传歌曲是否侵权。音频指纹流程如下:

In架构师 张毅:支持亿级用户,In数据服务的架构演进
In架构师张毅本次峰会的演讲主题是《支持亿级用户,In数据服务的架构演进》,分享了in数据服务(即大数据)从初创到支持亿级用户, 从单点服务到高可用集群服务, 从简单CRUD到融合实时大数据挖掘推荐的演变过程, 以及这一过程中的经验和教训等实践细节。
以架构演进为蓝本,首先从in的业务组成出发,再到in的数据服务,最后到in的数据服务架构演进硬件网络拓扑结构,一步步讲解亿级用户下,In大数据的架构。

演讲过程中,他从In第一代数据服务讲起,分析历代数据服务的有点和局限性,其中第三代为In现在所采用的数据服务:
业务挑战:
- 数据量和访问量激增
- 基于大数据的推荐
数据服务设计原则
- 业务满足优先
- 大幅重构
- 满足长远需求
数据服务组成:
- 存储: MySQL, BanyanDB, 数据仓库
- 计算: Spark
- 流转: Flume, ELK, RunDeck
数据服务架构:

优点:
- 支持中等规模大数据处理
- 自动化水平大幅提升
缺点:
- 大规模大数据处理能力不足
- 访问接口复杂, 对业务方要求较高
同时他还指出,目前正处于第三代向第四代迁移的过程中,而In第四代数据服务的设计目标是:
- 支持大规模大数据处理
- 建立统一数据访问层
演讲最后,张毅对本次分享内容做了一个总结:
- 按需设计, 保持模块间低耦合状态;
- 服务逐步叠加, 减少杀鸡用牛刀的设计;
- 业务变化速度总是超出预期的, 数据服务架构需要保持扩展能力并不断重构。
万达金融网络技术中心大数据技术专家 李呈祥:Apache Flink在万达金融的实践
万达金融网络技术中心大数据技术专家李呈祥带了主题为《Apache Flink在万达金融的实践》的技术分享,他主要从万达金融基于Apache Flink相关的项目、为什么选择Flink搭建流计算平台、在使用Flink的过程中遇到的问题和一些使用经验三个方面进行分析,结合Apache Flink在金融领域的应用实践,指出Apache Flink的功能特性及其与其他流计算框架的不同之处。

演讲开始之初,他首先介绍了万达金融基于流计算平台的项目:
- 数字权益交易平台

- 实时风控平台基本架构
- 实时风控计算平台设计指标
同时,他阐释了选择流式计算平台的原因包括:
- 正确性,交易平台要求各阶段的输出结果绝对正确;
- 功能完备性,各种复杂的行情统计功能,需要基于Event Time Window、Evictor等功能特性;
- 低延迟,要求100ms级别的延迟,实时返回风控结果;
- 易用性,基于CEP库等实现规则模型;
- 高吞吐量,满足大批量的数据索引需求;
- 易用性,ES Connector等可方便连接ES。
此外,李呈祥还从功能特性、延迟和吞吐量等性能指标出发,分析对比Flink、Spark和Storm,进一步揭示万达选择Flink搭建流式计算平台的原因:

在最后一组问答中,本场大数据峰会也接近尾声,与会者在此通过SDCC的平台进行交流切磋,在get丰富干货的同时,更是表达了对明天架构峰会的更高期望。