概述
刚开始使用OceanBase时会先看SQL的功能和性能是否满足业务需求,如果还想知道测试期间OceanBase在做什么,可以先从rootservice功能了解开始。
rootservice服务是OceanBase集群内部租户(sys)里的一个服务,依托于表__all_core_table。rootservice服务主要是做一些集群级别的管理和任务调度等。虽然有点中心的特点,由于表__all_core_table是至少三副本的,并且选举模块会保证这个表的高可用,所以rootservice也是有高可用的。此外rootservice的工作通常都很少,因此也不会成为集群性能的瓶颈。
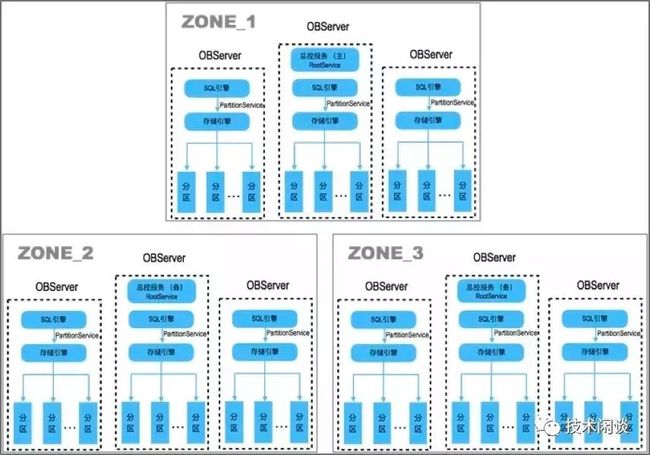
rootservice服务
功能总览
目前rootservice功能包括:
集群自举(初始化)。在搭建OceanBase集群里有一步很管家就是 bootstrap操作。指定三个节点选举出一个leader后就初始化相关内部表,然后rootservice服务就开始提供服务,OceanBase集群也就搭建成功了。
集群架构管理。如集群布局Zone的创建、类型管理。
OBServer节点生命周期管理。如节点心跳检测、节点上线和下线、新增和删除等。
集群级别参数变更。指将参数(parameter)的变更发往各个节点上SQL引擎执行。
集群资源管理。如定义资源单元(unit)的规格,分配资源单元Unit、创建资源池、创建租户。以及相应的变更操作(修改或删除)。
集群分区负载均衡。计算各个资源单元的负载和节点负载,发起分区迁移任务和分区leader切换任务。
指导分区leader选举。分区的选举由选举模块负责,rootservice只是根据一些规则(如primary_zone或locality)影响分区的leader选举。
合并转储冻结管理。OceanBase的增量单独存放在内存memtable里,这部份内存使用率超过阈值后需要冻结、转储到磁盘或者跟基线数据做合并落盘。
数据库对象变更任务管理(DDL)。主要是所有租户的建表、视图、存储过程等DDL语句的任务管理。
其他。随着版本的递进,一些适合rootservice集中做的事情会陆续加入。
其中有些功能在之前的文章里已经介绍过,下面就介绍其他几个重要功能。
集群自举(初始化)
OceanBase是个分布式集群,没有共享磁盘。集群各个节点靠启动时指定相同的rootservice参数来形成集群。
下面是启动示例:
cd /home/admin/node1/oceanbase && /home/admin/node1/oceanbase/bin/observer -i bond0 -P 2882 -p 2881 -z zone1 -d /home/admin/node1/oceanbase/store/obdemo -r '11.***.84.78:2882:2881;11.***.84.79:2882:2881;11.***.84.83:2882:2881' -c 20190423 -n obdemo -o "system_memory=10G,memory_limit=51200M,datafile_size=100G,config_additional_dir=/data/data/1/obdemo/etc3;/data/log/log1/obdemo/etc2"
其中 -r参数就是指定了rootservice_list地址。第一次搭建的时候,需要用命令初始化该服务。
mysql -h11.***.84.78 -uroot -P2881 -p
alter system bootstrap ZONE 'zone1' SERVER '11.***.84.78:2882', ZONE 'zone2' SERVER '11.***.84.79:2882', ZONE 'zone3' SERVER '11.***.84.83:2882';
OBServer节点生命周期管理
bootstrap操作只需要做一次,一个集群只有一个rootservice服务。其他节点在启动时指定rootservice_list后,在集群sys租户内用一个命令将新节点注册到集群中。
mysql -h11.***.84.78 -uroot@sys -P2881 -prootpwd -c -A oceanbase
alter system add server '11.***.84.78:3882' zone 'zone1';
alter system add server '11.***.84.79:3882' zone 'zone2';
alter system add server '11.***.84.83:3882' zone 'zone3';
节点加进集群后,自动上线为active状态。

节点生命周期如上图,相应操作SQL语法如下:
alter_system_server_stmt:
ALTER SYSTEM server_action SERVER ip_port_list [zone];
server_action:
ADD
| DELETE
| CANCEL DELETE
| START
| STOP
| FORCE STOP
ip_port_list:
ip_port [, ip_port ...]
如果要下线服务器,稳妥的做法是先stop server,然后delete server。delete server需要逐个的删除节点上的分区副本,会触发分区迁移逻辑。这个会需要一段时间,这期间还可以发起cancel操作。
Zone生命周期管理
上面新增的节点都要归属于某个Zone。集群Zone的数量决定了数据(分区)副本的最大数量。通常三副本就至少有三个Zone。新增Zone属于OceanBase集群的扩容操作,是支持的。
Zone的生命周期如下
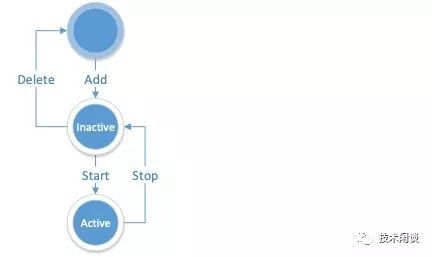
SQL语法如下:
alter_system_zone_stmt:
ADD ZONE zone_name
[zone_option_list]
| {ALTER | CHANGE | MODIFY} ZONE zone_name
[SET] zone_option_list
| {DELETE | START | STOP | FORCE STOP} ZONE zone_name
zone_option_list:
zone_option [, zone_option ...]
zone_option:
region
| idc
| ZONE_TYPE {READONLY | READWRITE}
idc:
STR_VALUE
Zone的管理多用在集群扩容、机房数据库在线搬迁等场景中。
分区副本管理
OceanBase里的数据默认有三份,具体到每个分区(表的子集)会有三个副本,存在三个Zone里。默认情况下业务不需要关心副本的位置,但是运维也可以手动修改副本的位置、类型等。
副本管理语法如下:
alter_system_replica_stmt:
ALTER SYSTEM replica_action;
replica_action:
SWITCH REPLICA
{LEADER | FOLLOWER}
{replica server | server [tenant_name] | zone [tenant_name]}
| DROP REPLICA
replica server [create_timestamp] [zone] [FORCE]
| {MOVE | COPY} REPLICA
replica source destination
| REPORT REPLICA
{zone | server}
| RECYCLE REPLICA
{zone | server}
| {ALTER | CHANGE | MODIFY} REPLICA
replica server [set] REPLICA_TYPE = replica_type
source:
SOURCE [=] 'ip:port'
destination:
DESTINATION [=] 'ip:port'
partition_idx | partition_count | table_id | task_id:
INT_VALUE
create_timestamp:
CREATE_TIMESTAMP [=] INT_VALUE
tenant_name_list:
tenant_name [, tenant_name ...]
replica_type:
{FULL | F}
| {READONLY | R}
| {LOGONLY | L}
常用场景:
手动或自动打散分区副本分布。使用move replica命令。这也是分区迁移的命令。OB负载均衡就是靠分区自动迁移实现。
删除/复制/回收副本。
修改副本类型。从全功能副本改为日志副本、或者只读副本。多用于数据库跨机房在线搬迁。
leader选举(切换)。可以使用switch replica强制将某个副本角色变更为leader。
指导分区选举策略
通常默认情况下分区在选举时Leader角色落在那个副本上是自动的,业务不用关心。这样有可能出现的局面就是很多分区的leader分布非常散,有点杂乱无章的感觉。虽然这体现了分布式的特点,只是无规则的分布式对业务来说可能会性能不好。要业务性能好,必须考虑业务表的业务联系。
OceanBase可以提供一些策略供用户干预业务表的选举(leader分布特点)。如租户有个primary zone设置,是租户内所有分区的leader分布位置选择时的次序。同时还有locality字段设置一组位置(有不同的优先级,并体现就近原则等)供leader选举时参考。
MySQL [oceanbase]> select tenant_name,primary_zone,locality,info from __all_tenant;
+-------------+-------------------+---------------------------------------------+---------------+
| tenant_name | primary_zone | locality | info |
+-------------+-------------------+---------------------------------------------+---------------+
| sys | zone1;zone2,zone3 | FULL{1}@zone1, FULL{1}@zone2, FULL{1}@zone3 | system tenant |
| t_obdemo | RANDOM | FULL{1}@zone1, FULL{1}@zone2, FULL{1}@zone3 | |
+-------------+-------------------+---------------------------------------------+---------------+
2 rows in set (0.00 sec)
同时OceanBase还提供表分组(tablegroup)用于将有业务强联系的不同分区在空间分配时约束在一个节点的资源单元(Unit)内部。

MySQL [sysbenchtest]> show create table sbtest1\G
*************************** 1. row ***************************
Table: sbtest1
Create Table: CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) NOT NULL DEFAULT '',
`pad` char(60) NOT NULL DEFAULT '',
PRIMARY KEY (`id`, `k`)
) AUTO_INCREMENT = 12000001 DEFAULT CHARSET = utf8mb4 ROW_FORMAT = DYNAMIC COMPRESSION = 'zstd_1.0' REPLICA_NUM = 3 BLOCK_SIZE = 16384 USE_BLOOM_FILTER = FALSE TABLET_SIZE = 134217728 PCTFREE = 10
partition by hash(k) partitions 5
1 row in set (0.15 sec)
MySQL [sysbenchtest]> create tablegroup tg_sbtest partition by hash partitions 5;
Query OK, 0 rows affected (0.01 sec)
MySQL [sysbenchtest]> alter tablegroup tg_sbtest add sbtest1,sbtest2,sbtest3,sbtest4,sbtest5,sbtest6,sbtest7,sbtest8;
Query OK, 0 rows affected (0.04 sec)
MySQL [sysbenchtest]> show tablegroups;
+-----------------+------------+---------------+
| Tablegroup_name | Table_name | Database_name |
+-----------------+------------+---------------+
| oceanbase | NULL | NULL |
| tg_sbtest | sbtest1 | sysbenchtest |
| tg_sbtest | sbtest2 | sysbenchtest |
| tg_sbtest | sbtest3 | sysbenchtest |
| tg_sbtest | sbtest4 | sysbenchtest |
| tg_sbtest | sbtest5 | sysbenchtest |
| tg_sbtest | sbtest6 | sysbenchtest |
| tg_sbtest | sbtest7 | sysbenchtest |
| tg_sbtest | sbtest8 | sysbenchtest |
+-----------------+------------+---------------+
9 rows in set (0.05 sec)
分区组的结构跟分区表的分区策略(如hash)和分区数(如5个)必须保持一致。当将8个测试表加入到一个表分组后,在一个2-2-2的OceanBase集群里这些分区的分布如下(只有leader副本可以提供写入,所以看写入的节点就可以看到leader的位置。当然还可以查看内部视图确定)。
备注:上图有趣的是表只分了5个分区,8个表的同号分区会被加入到一个分区组,一共有5个分区组,但是有6个节点,所以有个机器上没有该表的分区。所以,分区表的分区数目一定要大于集群的节点总数(要充分考虑将来扩容后的节点)。同时还建议这个分区数是质数最佳。
再通过内部视图验证一下分区的位置分布
select t3.tenant_name,t4.database_name, t5.tablegroup_name, t1.table_name,t2.partition_id, t2.svr_ip, t2.svr_port
from __all_table t1 join gv$partition t2 on (t1.tenant_id=t2.tenant_id and t1.table_id=t2.table_id)
join __all_tenant t3 on (t1.tenant_id=t3.tenant_id)
join __all_database t4 on (t1.tenant_id=t4.tenant_id and t1.database_id=t4.database_id)
left join __all_tablegroup t5 on (t1.tablegroup_id=t5.tablegroup_id)
where t3.tenant_id=1001 and t2.role=1
order by t4.database_name, t5.tablegroup_name, t1.table_name,t2.partition_id, t2.svr_ip, t2.svr_port;
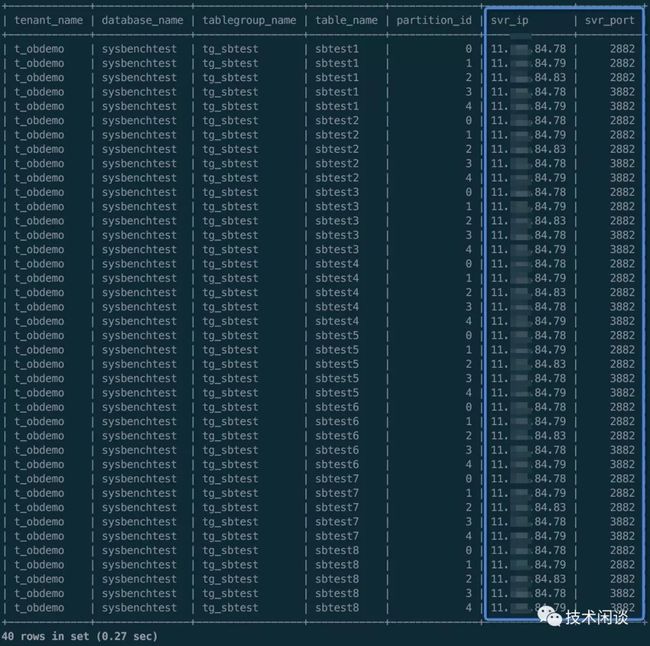
冻结/转储/合并逻辑
OceanBase跟传统数据库最大的区别之一就是写数据的时候将数据块从文件读入内存之后,并不是立即在内存中该数据块上修改,而是单独开辟一块内存记录增量。修改多少内容,增量就只包含变化的内容。所以OceanBase的写产生的脏块速度会非常慢,加上OceanBase内存比较大,就没有持续刷脏这个操作。当然这么设计的原因是绝大部分业务每天(24h)数据修改的量占业务数据总量比重是很小的。
随着业务写的进行,OceanBase增量内存会越来越多(如下图中的内存Total部分)。当这个增量内存总和达到一个阈值后,OceanBase就会发起一个冻结事件(freeze)。

冻结时,会针对每个分区的记录生成一个新的空的内存块接纳后续的写入,原增量内存块停止写入。如果上面有未提交事务,则将相应的分区数据迁移到新的增量内存块中(2.1逻辑,冻结不杀事务)。此后这部份冻结的增量块会直接转储(dump)到本地磁盘上,然后增量内存就释放了。
触发冻结时的一个阈值由参数freeze_trigger_percentage控制。这个值可以修改,由运维根据实际情况观察修改。
alter system set freeze_trigger_percentage=30;
转储时对主机的IO和CPU影响很小,可以转储多次,最大次数由参数minor_freeze_times决定。默认值是10.可以修改。建议改大。
alter system set minor_freeze_times=100;
上面冻结是自动触发的。如果手动发起冻结,则会先冻结,然后直接发起合并操作(不再转储)。合并指的是内存中的增量数据跟对应的基线数据在内存里合并,然后以SSTable的格式写入到磁盘数据文件中。注意合并的时候只有原SSTable有变化的部分才会写回磁盘。所以OceanBase的数据模型虽然是LSM架构,但是没有写放大困扰。并且由于是每天固定时间段的集中式大IO写入到磁盘(SSD),对SSD的寿命影响很小。
手动发起冻结合并的SQL:
alter system major freeze;
rootservice活动观察
上面描述了rootservice多种功能,OceanBase提供了一个视图__all_rootservice_event_History来观察它的活动。这个对用户意义非常大。
select * from __all_rootservice_event_History
order by gmt_create desc limit 50;
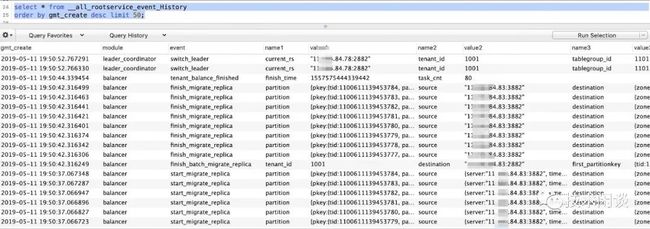
最后,我们也可以再次看看rootservice有哪几类活动
select module,event,count(*) from __all_rootservice_event_History group by module,event order by module;
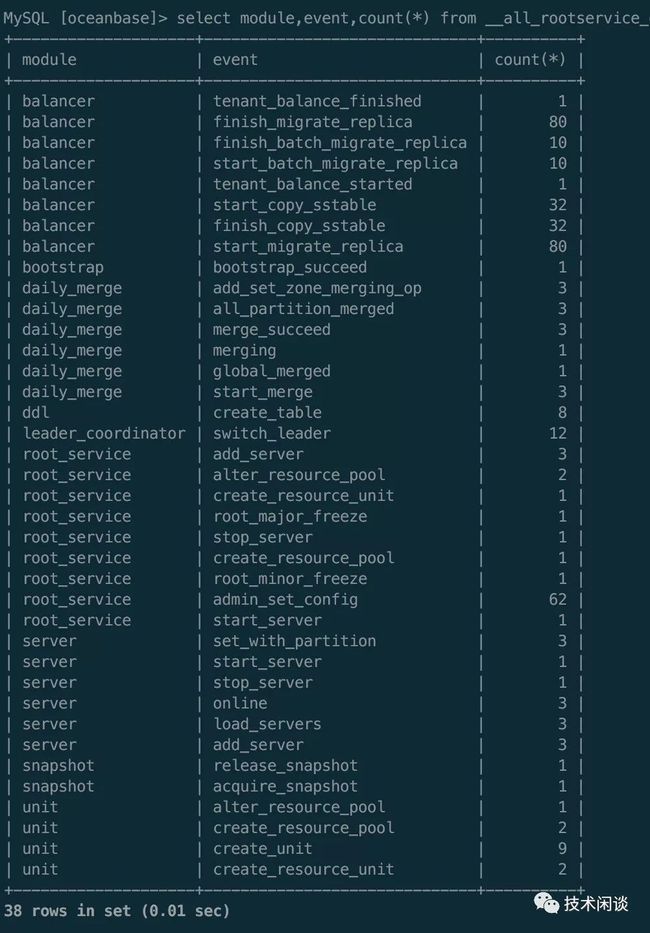
rootservice服务的可用性
上篇文章《自动化运维产品的命门——元数据库》里特地指出一个分布式产品的元数据库对这个产品的可用性至关重要。OceanBase的元数据都在内部租户sys里,并通过rootservice去修改这些元数据。rootservice就是OceanBase集群的一个关键服务。所以它的可用性也很重要。这里就再次重复一下上文中的观点。
OBServer 启动参数
对OceanBase集群加节点之前,节点上必须运行OBServer进程,并且该进程要指定rootservice_list参数为已有集群。
其中一种方法是通过 -r指定具体的rootservice成员列表。该节点的这个参数值会立即持久化到本地参数文件中。当节点加入到集群之后,集群的rootservice成员如果发生变化,都会立即通知各个活着的节点并在相应的参数文件里生效。不过这个方法有个弊端就是如果一个节点宕机很久再恢复的时候,集群的rootservice成员已经经历大换血,该节点使用老的rootservice_list信息是找不到老的集群的,就会无法启动。
所以OceanBase设计上还支持通过参数obconfig_url去获取集群rootservice_list地址。这个参数的值是一个API,支持GET和POST两个方法。这个API由OceanBase自动化运维平台OCP提供,具体读写的数据保存在OCP的元数据库里。即使rootservice成员变化,也可以通过这个API获取最新的地址。OCP的元数据库又是一个独立的OceanBase集群(有高可用和不丢数据两项保证),所以这个设计的可靠性非常高。
这个参数也可以通过随后修改。如下:
alter system set obconfig_url='http://10.***.167.20:8082/services?Action=ObRootServiceInfo&User_ID=alibaba&UID=admin&ObRegion=oms_2x' server = '11.***.84.78:2882';
OCP API 模拟
不过由于OCP的搭建需要额外三台主机,一般网友没有这么多机器用来部署OB和OCP。所以在最初的安装部署中我没有推荐用OCP安装OceanBase集群。
这里提供一个技巧可以弥补这个问题。使用Python的HTTPServer模块模拟一个web服务,并将一个文件的内容模拟API的结果。
注:下面的***是出于安全考虑估计屏蔽显示的。
1. 写一个 rs.json文件模拟api的结果
$cat /home/admin/test/rs.json
{"Code":200,"Cost":3,"Data":{"ObRegionId":2100006,"RsList":[{"sql_port":2881,"address":"11.***.84.83:2882","role":"LEADER"},{"sql_port":2881,"address":"11.***.84.78:2882","role":"FOLLOWER"},{"sql_port":2881,"address":"11.***.84.84:2882","role":"FOLLOWER"}],"ReadonlyRsList":[],"ObRegion":"oms_2x"},"Message":"successful","Success":true,"Trace":"9.9.9.9:10.***.167.20:1556446480671"}
2. 本地用python起一个httpserver
[[email protected] /home/admin/test]
$python -m SimpleHTTPServer 8080
Serving HTTP on 0.0.0.0 port 8080 ...
3. 验证api
[[email protected] /home/admin/oceanbase]
$curl -L 'http://127.0.0.1:8080/rs.json'
{"Code":200,"Cost":3,"Data":{"ObRegionId":2100006,"RsList":[{"sql_port":2881,"address":"11.***.84.83:2882","role":"LEADER"},{"sql_port":2881,"address":"11.***.84.78:2882","role":"FOLLOWER"},{"sql_port":2881,"address":"11.***.84.84:2882","role":"FOLLOWER"}],"ReadonlyRsList":[],"ObRegion":"oms_2x"},"Message":"successful","Success":true,"Trace":"9.9.9.9:10.***.167.20:1556446480671"}
4. 以新的参数启动observer
[[email protected] /home/admin/oceanbase]
$bin/observer -o "obconfig_url='http://11.***.84.78:8080/rs.json'"
bin/observer -o obconfig_url='http://11.***.84.78:8080/rs.json'
optstr: obconfig_url='http://11.***.84.78:8080/rs.json'
[2019-05-09 17:27:18.094254] ERROR [LIB] pidfile_test (utility.cpp:1152) [71476][0][Y0-0000000000000000] [lt=0] fid file doesn't exist(pidfile="run/observer.pid") BACKTRACE:0x7bfc359 0x7b400ab 0x6f4419 0x7c00a96 0x413266 0x7f7a35604445 0x43c025
不过模拟的API终究是假的,那不支持POST方法,所以rootservice服务在成员变更后是没办法通过POST方法去调用API更新的。这个时候可以直接修改文件 rs.json里rootservice_list信息。那么故障节点启动时就不需要做任何修改了。
再次重申,这个方法只适合机器很少时搭建OB学习验证环境使用。在生产环境,还是要用OCP来搭建OceanBase集群。
总结
虽然OceanBase已经闭源了,但并不是封闭的黑盒。OceanBase的总控服务rootservice承担一些集群级别的任务,通过内部视图可以查看每个任务的信息。
推荐阅读
其他
个人理解,难免有误。我会在月底集中对当月文章里的错误进行修正。敬请关注。
更多分享请查阅公众号
