美团BERT的探索和实践
他山之石,可以攻玉。美团点评NLP团队一直紧跟业界前沿技术,开展了基于美团点评业务数据的预训练研究工作,训练了更适配美团点评业务场景的MT-BERT模型,通过微调将MT-BERT落地到多个业务场景中,并取得了不错的业务效果。
背景
2018年,自然语言处理(Natural Language Processing,NLP)领域最激动人心的进展莫过于预训练语言模型,包括基于RNN的ELMo[1]和ULMFiT[2],基于Transformer[3]的OpenAI GPT[4]及Google BERT[5]等。下图1回顾了近年来预训练语言模型的发展史以及最新的进展。预训练语言模型的成功,证明了我们可以从海量的无标注文本中学到潜在的语义信息,而无需为每一项下游NLP任务单独标注大量训练数据。此外,预训练语言模型的成功也开创了NLP研究的新范式[6],即首先使用大量无监督语料进行语言模型预训练(Pre-training),再使用少量标注语料进行微调(Fine-tuning)来完成具体NLP任务(分类、序列标注、句间关系判断和机器阅读理解等)。

图1 NLP Pre-training and Fine-tuning新范式及相关扩展工作
所谓的“预训练”,其实并不是什么新概念,这种“Pre-training and Fine-tuning”的方法在图像领域早有应用。2009年,邓嘉、李飞飞等人在CVPR 2009发布了ImageNet数据集[7],其中120万张图像分为1000个类别。基于ImageNet,以图像分类为目标使用深度卷积神经网络(如常见的ResNet、VCG、Inception等)进行预训练,得到的模型称为预训练模型。针对目标检测或者语义分割等任务,基于这些预训练模型,通过一组新的全连接层与预训练模型进行拼接,利用少量标注数据进行微调,将预训练模型学习到的图像分类能力迁移到新的目标任务。预训练的方式在图像领域取得了广泛的成功,比如有学者将ImageNet上学习得到的特征表示用于PSACAL VOC上的物体检测,将检测率提高了20%[8]。
他山之石,可以攻玉。图像领域预训练的成功也启发了NLP领域研究,深度学习时代广泛使用的词向量(即词嵌入,Word Embedding)即属于NLP预训练工作。使用深度神经网络进行NLP模型训练时,首先需要将待处理文本转为词向量作为神经网络输入,词向量的效果会影响到最后模型效果。词向量的效果主要取决于训练语料的大小,很多NLP任务中有限的标注语料不足以训练出足够好的词向量,通常使用跟当前任务无关的大规模未标注语料进行词向量预训练,因此预训练的另一个好处是能增强模型的泛化能力。目前,大部分NLP深度学习任务中都会使用预训练好的词向量(如Word2Vec[9]和GloVe[10]等)进行网络初始化(而非随机初始化),从而加快网络的收敛速度。
预训练词向量通常只编码词汇间的关系,对上下文信息考虑不足,且无法处理一词多义问题。如“bank”一词,根据上下文语境不同,可能表示“银行”,也可能表示“岸边”,却对应相同的词向量,这样显然是不合理的。为了更好的考虑单词的上下文信息,Context2Vec[11]使用两个双向长短时记忆网络(Long Short Term Memory,LSTM)[12]来分别编码每个单词左到右(Left-to-Right)和右到左(Right-to-Left)的上下文信息。类似地,ELMo也是基于大量文本训练深层双向LSTM网络结构的语言模型。ELMo在词向量的学习中考虑深层网络不同层的信息,并加入到单词的最终Embedding表示中,在多个NLP任务中取得了提升。ELMo这种使用预训练语言模型的词向量作为特征输入到下游目标任务中,被称为Feature-based方法。
另一种方法是微调(Fine-tuning)。GPT、BERT和后续的预训练工作都属于这一范畴,直接在深层Transformer网络上进行语言模型训练,收敛后针对下游目标任务进行微调,不需要再为目标任务设计Task-specific网络从头训练。关于NLP领域的预训练发展史,张俊林博士写过一篇很详实的介绍[13],本文不再赘述。
Google AI团队提出的预训练语言模型BERT(Bidirectional Encoder Representations from Transformers),在11项自然语言理解任务上刷新了最好指标,可以说是近年来NLP领域取得的最重大的进展之一。BERT论文也斩获NLP领域顶会NAACL 2019的最佳论文奖,BERT的成功也启发了大量的后续工作,不断刷新了NLP领域各个任务的最佳水平。有NLP学者宣称,属于NLP的ImageNet时代已经来临[14]。
美团点评作为中国领先的生活服务电子商务平台,涵盖搜索、推荐、广告、配送等多种业务场景,几乎涉及到各种类型的自然语言处理任务。在我们的平台上,迄今为止积累了近40亿条用户公开评价(UGC),如何高效而准确地完成对海量UGC的自然语言理解和处理是美团点评技术团队面临的挑战之一。美团NLP中心一直紧跟业界前沿技术,开展了基于美团点评业务数据的预训练研究工作,训练了更适配美团点评业务场景的MT-BERT模型,通过微调将MT-BERT落地到多个业务场景中,并取得了不错的业务效果。
BERT模型介绍
BERT是基于Transformer的深度双向语言表征模型,基本结构如图2所示,本质上是利用Transformer结构构造了一个多层双向的Encoder网络。Transformer是Google在2017年提出的基于自注意力机制(Self-attention)的深层模型,在包括机器翻译在内的多项NLP任务上效果显著,超过RNN且训练速度更快。不到一年时间内,Transformer已经取代RNN成为神经网络机器翻译的State-Of-The-Art(SOTA)模型,包括谷歌、微软、百度、阿里、腾讯等公司的线上机器翻译模型都已替换为Transformer模型。关于Transformer的详细介绍可以参考Google论文《Attention is all you need》[3]。

图2 BERT及Transformer网络结构示意图
模型结构
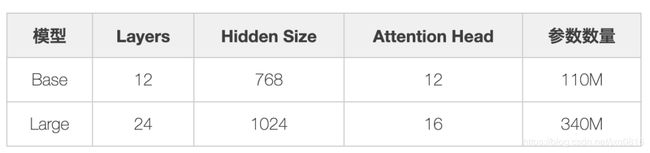
如表1所示,根据参数设置的不同,Google 论文中提出了Base和Large两种BERT模型。
输入表示
针对不同的任务,BERT模型的输入可以是单句或者句对。对于每一个输入的Token,它的表征由其对应的词表征(Token Embedding)、段表征(Segment Embedding)和位置表征(Position Embedding)相加产生,如图3所示:

图3 BERT模型的输入表示
-
对于英文模型,使用了Wordpiece模型来产生Subword从而减小词表规模;对于中文模型,直接训练基于字的模型。
-
模型输入需要附加一个起始Token,记为[CLS],对应最终的Hidden State(即Transformer的输出)可以用来表征整个句子,用于下游的分类任务。
-
模型能够处理句间关系。为区别两个句子,用一个特殊标记符[SEP]进行分隔,另外针对不同的句子,将学习到的Segment Embeddings 加到每个Token的Embedding上。
-
对于单句输入,只有一种Segment Embedding;对于句对输入,会有两种Segment Embedding。
预训练目标
BERT预训练过程包含两个不同的预训练任务,分别是Masked Language Model和Next Sentence Prediction任务。
Masked Language Model(MLM)
通过随机掩盖一些词(替换为统一标记符[MASK]),然后预测这些被遮盖的词来训练双向语言模型,并且使每个词的表征参考上下文信息。
这样做会产生两个缺点:(1)会造成预训练和微调时的不一致,因为在微调时[MASK]总是不可见的;(2)由于每个Batch中只有15%的词会被预测,因此模型的收敛速度比起单向的语言模型会慢,训练花费的时间会更长。对于第一个缺点的解决办法是,把80%需要被替换成[MASK]的词进行替换,10%的随机替换为其他词,10%保留原词。由于Transformer Encoder并不知道哪个词需要被预测,哪个词是被随机替换的,这样就强迫每个词的表达需要参照上下文信息。对于第二个缺点目前没有有效的解决办法,但是从提升收益的角度来看,付出的代价是值得的。
Next Sentence Prediction(NSP)
为了训练一个理解句子间关系的模型,引入一个下一句预测任务。这一任务的训练语料可以从语料库中抽取句子对包括两个句子A和B来进行生成,其中50%的概率B是A的下一个句子,50%的概率B是语料中的一个随机句子。NSP任务预测B是否是A的下一句。NSP的目的是获取句子间的信息,这点是语言模型无法直接捕捉的。
Google的论文结果表明,这个简单的任务对问答和自然语言推理任务十分有益,但是后续一些新的研究[15]发现,去掉NSP任务之后模型效果没有下降甚至还有提升。我们在预训练过程中也发现NSP任务的准确率经过1-2个Epoch训练后就能达到98%-99%,去掉NSP任务之后对模型效果并不会有太大的影响。
数据&算力
Google发布的英文BERT模型使用了BooksCorpus(800M词汇量)和英文Wikipedia(2500M词汇量)进行预训练,所需的计算量非常庞大。BERT论文中指出,Google AI团队使用了算力强大的Cloud TPU进行BERT的训练,BERT Base和Large模型分别使用4台Cloud TPU(16张TPU)和16台Cloud TPU(64张TPU)训练了4天(100万步迭代,40个Epoch)。但是,当前国内互联网公司主要使用Nvidia的GPU进行深度学习模型训练,因此BERT的预训练对于GPU资源提出了很高的要求。
MT-BERT实践
美团BERT(MT-BERT)的探索分为四个阶段:
(1)开启混合精度实现训练加速。
(2)在通用中文语料基础上加入大量美团点评业务语料进行模型预训练,完成领域迁移。
(3)预训练过程中尝试融入知识图谱中的实体信息。
(4)通过在业务数据上进行微调,支持不同类型的业务需求。
MT-BERT整体技术框架如图4所示:

图4 MT-BERT整体技术框架
基于美团点评AFO平台的分布式训练
正如前文所述,BERT预训练对于算力有着极大要求,我们使用的是美团内部开发的AFO[16](AI Framework On Yarn)框架进行MT-BERT预训练。AFO框架基于YARN实现数千张GPU卡的灵活调度,同时提供基于Horovod的分布式训练方案,以及作业弹性伸缩与容错等能力。Horovod是Uber开源的深度学习工具[17],它的发展吸取了Facebook《一小时训练ImageNet》论文[18]与百度Ring Allreduce[19]的优点,可为用户实现分布式训练提供帮助。根据Uber官方分别使用标准分布式TensorFlow和Horovod两种方案,分布式训练Inception V3和ResNet-101 TensorFlow模型的实验验证显示,随着GPU的数量增大,Horovod性能损失远小于TensorFlow,且训练速度可达到标准分布式TensorFlow的近两倍。相比于Tensorflow分布式框架,Horovod在数百张卡的规模上依然可以保证稳定的加速比,具备非常好的扩展性。
Horovod框架的并行计算主要用到了两种分布式计算技术:控制层的Open MPI和数据层的Nvidia NCCL。控制层面的主要作用是同步各个Rank(节点),因为每个节点的运算速度不一样,运算完每一个Step的时间也不一样。如果没有一个同步机制,就不可能对所有的节点进行梯度平均。Horovod在控制层面上设计了一个主从模式,Rank 0为Master节点,Rank1-n为Worker节点,每个Worker节点上都有一个消息队列,而在Master节点上除了一个消息队列,还有一个消息Map。每当计算框架发来通信请求时,比如要执行Allreduce,Horovod并不直接执行MPI,而是封装了这个消息并推入自己的消息队列,交给后台线程去处理。后台线程采用定时轮询的方式访问自己的消息队列,如果非空,Woker会将自己收到的所有Tensor通信请求都发给Master。因为是同步MPI,所以每个节点会阻塞等待MPI完成。Master收到Worker的消息后,会记录到自己的消息Map中。如果一个Tensor的通信请求出现了n次,也就意味着,所有的节点都已经发出了对该Tensor的通信请求,那么这个Tensor就需要且能够进行通信。Master节点会挑选出所有符合要求的Tensor进行MPI通信。不符合要求的Tensor继续留在消息Map中,等待条件满足。决定了Tensor以后,Master又会将可以进行通信的Tensor名字和顺序发还给各个节点,通知各个节点可以进行Allreduce运算。
混合精度加速
当前深度学习模型训练过程基本采用单精度(Float 32)和双精度(Double)数据类型,受限于显存大小,当网络规模很大时Batch Size就会很小。Batch Size过小一方面容易导致网络学习过程不稳定而影响模型最终效果,另一方面也降低了数据吞吐效率,影响训练速度。为了加速训练及减少显存开销,Baidu Research和Nvidia在ICLR 2018论文中[20]合作提出了一种Float32(FP32)和Float16(FP16)混合精度训练的方法,并且在图像分类和检测、语音识别和语言模型任务上进行了有效验证。Nvidia的Pascal和Volta系列显卡除了支持标准的单精度计算外,也支持了低精度的计算,比如最新的Tesla V100硬件支持了FP16的计算加速,P4和P40支持INT8的计算加速,而且低精度计算的峰值要远高于单精浮点的计算峰值。
为了进一步加快MT-BERT预训练和推理速度, 我们实验了混合精度训练方式。混合精度训练指的是FP32和FP16混合的训练方式,使用混合精度训练可以加速训练过程并且减少显存开销,同时兼顾FP32的稳定性和FP16的速度。在模型计算过程中使用FP16加速计算过程,模型训练过程中权重会存储成FP32格式(FP32 Master-weights),参数更新时采用FP32类型。利用FP32 Master-weights在FP32数据类型下进行参数更新可有效避免溢出。此外,一些网络的梯度大部分在FP16的表示范围之外,需要对梯度进行放大使其可以在FP16的表示范围内,因此进一步采用Loss Scaling策略通过对Loss进行放缩,使得在反向传播过程中梯度在FP16的表示范围内。
为了提高预训练效率,我们在MT-BERT预训练中采用了混合精度训练方式。
加速效果

图5 MT-BERT开启混合精度在Nvidia V100上训练吞吐量的对比(Tensorflow 1.12;Cuda 10.0;Horovod 0.15.2)
如图5所示,开启混合精度的训练方式在单机单卡和多机多卡环境下显著提升了训练速度。为了验证混合精度模型会不会影响最终效果,我们分别在美团点评业务和通用Benchmark数据集上进行了微调实验,结果见表2和表3。
 表2 开启混合精度训练的MT-BERT模型在美团点评业务Benchmark上效果对比
表2 开启混合精度训练的MT-BERT模型在美团点评业务Benchmark上效果对比
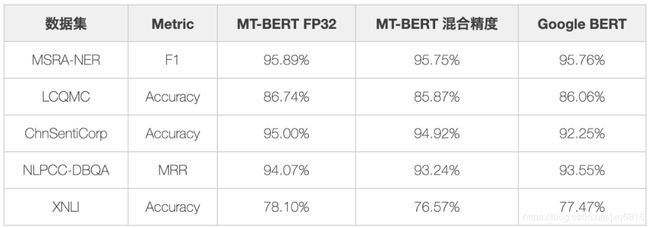 表3 开启混合精度训练的MT-BERT模型在中文通用Benchmark上效果对比
表3 开启混合精度训练的MT-BERT模型在中文通用Benchmark上效果对比
通过表2和表3结果可以发现,开启混合精度训练的MT-BERT模型并没有影响效果,反而训练速度提升了2倍多。
领域自适应
Google发布的中文BERT模型是基于中文维基百科数据训练得到,属于通用领域预训练语言模型。由于美团点评积累了大量业务语料,比如用户撰写的UGC评论和商家商品的文本描述数据,为了充分发挥领域数据的优势,我们考虑在Google中文BERT模型上加入领域数据继续训练进行领域自适应(Domain Adaptation),使得模型更加匹配我们的业务场景。实践证明,这种Domain-aware Continual Training方式,有效地改进了BERT模型在下游任务中的表现。由于Google未发布中文BERT Large模型,我们也从头预训练了中文MT-BERT Large模型。
我们选择了5个中文Benchmark任务以及3个美团点评业务Benchmark在内的8个数据集对模型效果进行验证。实验结果如表4所示,MT-BERT在通用Benchmark和美团点评业务Benchmark上都取得了更好的效果。
 表4 MT-BERT模型和Google BERT模型在8个Benchmark上的效果对比
表4 MT-BERT模型和Google BERT模型在8个Benchmark上的效果对比
知识融入
BERT在自然语言理解任务上取得了巨大的成功,但也存在着一些不足。其一是常识(Common Sense)的缺失。人类日常活动需要大量的常识背景知识支持,BERT学习到的是样本空间的特征、表征,可以看作是大型的文本匹配模型,而大量的背景常识是隐式且模糊的,很难在预训练数据中进行体现。其二是缺乏对语义的理解。模型并未理解数据中蕴含的语义知识,缺乏推理能力。在美团点评搜索场景中,需要首先对用户输入的Query进行意图识别,以确保召回结果的准确性。比如,对于“宫保鸡丁”和“宫保鸡丁酱料”两个Query,二者的BERT语义表征非常接近,但是蕴含的搜索意图却截然不同。前者是菜品意图,即用户想去饭店消费,而后者则是商品意图,即用户想要从超市购买酱料。在这种场景下,BERT模型很难像正常人一样做出正确的推理判断。
为了处理上述情况,我们尝试在MT-BERT预训练过程中融入知识图谱信息。知识图谱可以组织现实世界中的知识,描述客观概念、实体、关系。这种基于符号语义的计算模型,可以为BERT提供先验知识,使其具备一定的常识和推理能力。在我们团队之前的技术文章[21]中,介绍了NLP中心构建的大规模的餐饮娱乐知识图谱——美团大脑。我们通过Knowledge-aware Masking方法将“美团大脑”的实体知识融入到MT-BERT预训练中。
BERT在进行语义建模时,主要聚焦最原始的单字信息,却很少对实体进行建模。具体地,BERT为了训练深层双向的语言表征,采用了Masked LM(MLM)训练策略。该策略类似于传统的完形填空任务,即在输入端,随机地“遮蔽”掉部分单字,在输出端,让模型预测出这些被“遮蔽”的单字。模型在最初并不知道要预测哪些单字,因此它输出的每个单字的嵌入表示,都涵盖了上下文的语义信息,以便把被“掩盖”的单字准确的预测出来。
图6左侧展示了BERT模型的MLM任务。输入句子是“全聚德做的烤鸭久负盛名”。其中,“聚”,“的”,“久”3个字在输入时被随机遮蔽,模型预训练过程中需要对这3个遮蔽位做出预测。

图6 MT-BERT默认Masking策略和Whole Word Masking策略对比
BERT模型通过字的搭配(比如“全X德”),很容易推测出被“掩盖”字信息(“德”),但这种做法只学习到了实体内单字之间共现关系,并没有学习到实体的整体语义表示。因此,我们使用Knowledge-aware Masking的方法来预训练MT-BERT。具体的做法是,输入仍然是字,但在随机"遮蔽"时,不再选择遮蔽单字,而是选择“遮蔽”实体对应的词。这需要我们在预训练之前,对语料做分词,并将分词结果和图谱实体对齐。图6右侧展示了Knowledge-aware Masking策略,“全聚德”被随机“遮蔽”。MT-BERT需要根据“烤鸭”,“久负盛名”等信息,准确的预测出“全聚德”。通过这种方式,MT-BERT可以学到“全聚德”这个实体的语义表示,以及它跟上下文其他实体之间的关联,增强了模型语义表征能力。基于美团大脑中已有实体信息,我们在MT-BERT训练中使用了Knowledge-aware Masking策略,实验证明在细粒度情感分析任务上取得了显著提升。
 表5 MT-BERT在细粒度情感分析数据集上效果
表5 MT-BERT在细粒度情感分析数据集上效果
模型轻量化
BERT模型效果拔群,在多项自然语言理解任务上实现了最佳效果,但是由于其深层的网络结构和庞大的参数量,如果要部署上线,还面临很大挑战。以Query意图分类为例,我们基于MT-BERT模型微调了意图分类模型,协调工程团队进行了1000QPS压测实验,部署30张GPU线上卡参与运算,在线服务的TP999高达50ms之多,难以满足上线要求。
为了减少模型响应时间,满足上线要求,业内主要有三种模型轻量化方案。
-
低精度量化。在模型训练和推理中使用低精度(FP16甚至INT8、二值网络)表示取代原有精度(FP32)表示。
-
模型裁剪和剪枝。减少模型层数和参数规模。
-
模型蒸馏。通过知识蒸馏方法[22]基于原始BERT模型蒸馏出符合上线要求的小模型。
在美团点评搜索Query意图分类任务中,我们优先尝试了模型裁剪的方案。由于搜索Query长度较短(通常不超过16个汉字),整个Sequence包含的语义信息有限,裁剪掉几层Transformer结构对模型的语义表征能力不会有太大影响,同时又能大幅减少模型参数量和推理时间。经过实验验证,在微调过程中,我们将MT-BERT模型裁剪为4层Transfomer结构(MT-BERT-MINI,MBM),实验效果如图7所示。可以发现,Query分类场景下,裁剪后的MBM没有产生较大影响。由于减少了一些不必要的参数运算,在美食和酒店两个场景下,效果还有小幅的提升。
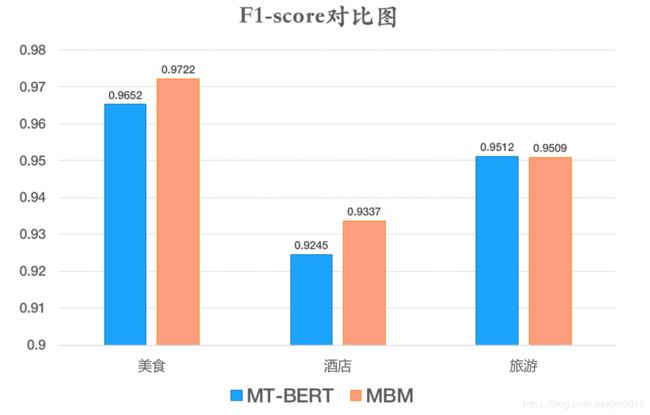
图7 裁剪前后MT-BERT模型在Query意图分类数据集上F1对比
MBM在同等压测条件下,压测服务的TP999达到了12-14ms,满足搜索上线要求。除了模型裁剪,为了支持更多线上需求,我们还在进行模型蒸馏实验,蒸馏后的6层MT-BERT模型在大多数下游任务中都没有显著的效果损失。值得一提的是,BERT模型轻量化是BERT相关研究的重要方向,最近Google公布了最新ALBERT模型(A Lite BERT)[23],在减少模型参数量的同时在自然语言理解数据集GLUE上刷新了SOTA。
在美团点评业务中的应用
图8展示了基于BERT模型微调可以支持的任务类型,包括句对分类、单句分类、问答(机器阅读理解)和序列标注任务。
-
句对分类任务和单句分类任务是句子级别的任务。预训练中的NSP任务使得BERT中的“[CLS]”位置的输出包含了整个句子对(句子)的信息,我们利用其在有标注的数据上微调模型,给出预测结果。
-
问答和序列标注任务都属于词级别的任务。预训练中的MLM任务使得每个Token位置的输出都包含了丰富的上下文语境以及Token本身的信息,我们对BERT的每个Token的输出都做一次分类,在有标注的数据上微调模型并给出预测。

图8 BERT微调支持的任务类型
基于MT-BERT的微调,我们支持了美团搜索和点评搜索的多个下游任务,包括单句分类任务、句间关系任务和序列标注任务等等。
单句分类
细粒度情感分析
美团点评作为生活服务平台,积累了大量真实用户评论。对用户评论的细粒度情感分析在深刻理解商家和用户、挖掘用户情感等方面有至关重要的价值,并且在互联网行业已有广泛应用,如个性化推荐、智能搜索、产品反馈、业务安全等领域。为了更全面更真实的描述商家各属性情况,细粒度情感分析需要判断评论文本在各个属性上的情感倾向(即正面、负面、中立)。为了优化美团点评业务场景下的细粒度情感分析效果,NLP中心标注了包含6大类20个细粒度要素的高质量数据集,标注过程中采用严格的多人标注机制保证标注质量,并在AI Challenger 2018细粒度情感分析比赛中作为比赛数据集验证了效果,吸引了学术界和工业届大量队伍参赛。
针对细粒度情感分析任务,我们设计了基于MT-BERT的多任务分类模型,模型结构如图9所示。模型架构整体分为两部分:一部分是各情感维度的参数共享层(Share Layers),另一部分为各情感维度的参数独享层(Task-specific Layers)。其中参数共享层采用了MT-BERT预训练语言模型得到文本的上下文表征。MT-BERT依赖其深层网络结构以及海量数据预训练,可以更好的表征上下文信息,尤其擅长提取深层次的语义信息。参数独享层采用多路并行的Attention+Softmax组合结构,对文本在各个属性上的情感倾向进行分类预测。通过MT-BERT优化后的细粒度情感分析模型在Macro-F1上取得了显著提升。
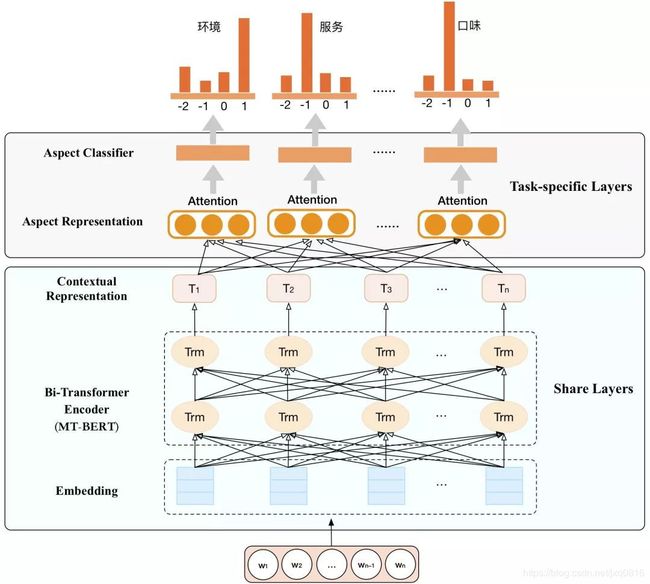
图9 基于MT-BERT的多任务细粒度情感分析模型架构
细粒度情感分析的重要应用场景之一是大众点评的精选点评模块,如图10所示。精选点评模块作为点评App用户查看高质量评论的入口,其中精选点评标签承载着结构化内容聚合的作用,支撑着用户高效查找目标UGC内容的需求。细粒度情感分析能够从不同的维度去挖掘评论的情感倾向。基于细粒度情感分析的情感标签能够较好地帮助用户筛选查看,同时外露更多的POI信息,帮助用户高效的从评论中获取消费指南。
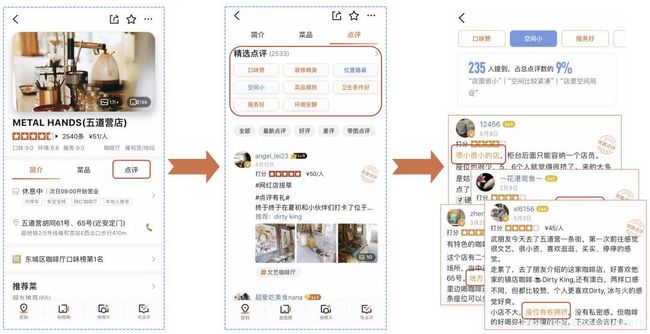
图10 大众点评精选点评模块产品形态
Query意图分类
在美团点评的搜索架构中,Deep Query Understanding(DQU)都是重要的前置模块之一。对于用户Query,需要首先对用户搜索意图进行识别,如美食、酒店、演出等等。我们跟内部的团队合作,尝试了直接使用MT-BERT作为Query意图分类模型。为了保证模型在线Inference时间,我们使用裁剪后的4层MT-BERT模型(MT-BERT-MINI,MBM模型)上线进行Query意图的在线意图识别,取得的业务效果如图11所示:

图11 MBM模型的业务效果
同时对于搜索日志中的高频Query,我们将预测结果以词典方式上传到缓存,进一步减少模型在线预测的QPS压力。MBM累计支持了美团点评搜索17个业务频道的Query意图识别模型,相比原有模型,均有显著的提升,每个频道的识别精确度都达到95%以上。MBM模型上线后,提升了搜索针对Query文本的意图识别能力,为下游的搜索的召回、排序及展示、频道流量报表、用户认知报表、Bad Case归因等系统提供了更好的支持。
推荐理由场景化分类
推荐理由是点评搜索智能中心数据挖掘团队基于大众点评UGC为每个POI生产的自然语言可解释性理由。对于搜索以及推荐列表展示出来的每一个商家,我们会用一句自然语言文本来突出商家的特色和卖点,从而让用户能够对展示结果有所感知,“知其然,更知其所以然”。近年来,可解释的搜索系统越来越受到关注,给用户展示商品或内容的同时透出解释性理由,正在成为业界通行做法,这样不仅能提升系统的透明度,还能提高用户对平台的信任和接受程度,进而提升用户体验效果。在美团点评的搜索推荐场景中,推荐理由有着广泛的应用场景,起到解释展示、亮点推荐、场景化承载和个性化体现的重要作用,目前已经有46个业务方接入了推荐理由服务。
对于不同的业务场景,对推荐理由会有不同的要求。在外卖搜索场景下,用户可能更为关注菜品和配送速度,不太关注餐馆的就餐环境和空间,这种情况下只保留符合外卖场景的推荐理由进行展示。同样地,在酒店搜索场景下,用户可能更为关注酒店特色相关的推荐理由(如交通是否方便,酒店是否近海近景区等)。
我们通过内部合作,为业务方提供符合不同场景需求的推荐理由服务。推荐理由场景化分类,即给定不同业务场景定义,为每个场景标注少量数据,我们可以基于MT-BERT进行单句分类微调,微调方式如图8(b)所示。
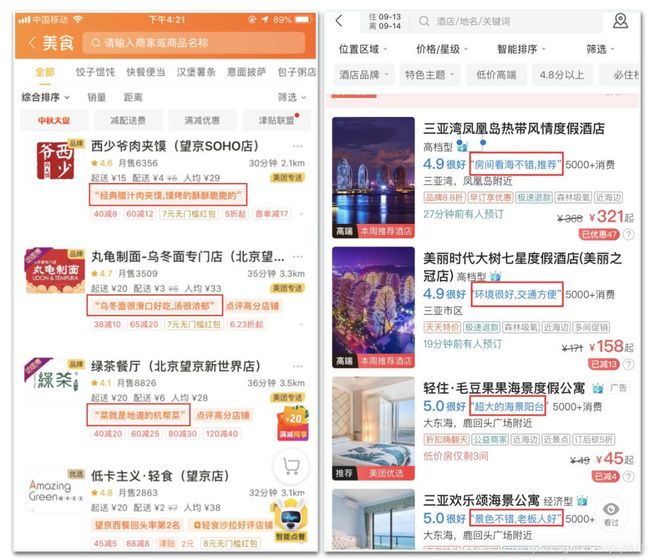
图12 外卖和酒店场景下推荐理由
句间关系
句间关系任务是对两个短语或者句子之间的关系进行分类,常见句间关系任务如自然语言推理(Natural Language Inference, NLI)、语义相似度判断(Semantic Textual Similarity,STS)等。
Query改写是在搜索引擎中对用户搜索Query进行同义改写,改善搜索召回结果的一种方法。在美团和点评搜索场景中,通常一个商户或者菜品会有不同的表达方式,例如“火锅”也称为“涮锅”。有时不同的词语表述相同的用户意图,例如“婚纱摄影”和“婚纱照”,“配眼镜”和“眼镜店”。Query改写可以在不改变用户意图的情况下,尽可能多的召回满足用户意图的搜索结果,提升用户的搜索体验。为了减少误改写,增加准确率,需要对改写后Query和原Query做语义一致性判断,只有语义一致的Query改写对才能上线生效。Query语义一致性检测属于STS任务。我们通过MT-BERT微调任务来判断改写后Query语义是否发生漂移,微调方式如图8(a)所示,把原始Query和改写Query构成句子对,即“[CLS] text_a [SEP] text_b [SEP]”的形式,送入到MT-BERT中,通过“[CLS]”判断两个Query之间关系。实验证明,基于MT-BERT微调的方案在Benchmark上准确率和召回率都超过原先的XGBoost分类模型。
序列标注
序列标注是NLP基础任务之一,给定一个序列,对序列中的每个元素做一个标记,或者说给每一个元素打一个标签,如中文命名实体识别、中文分词和词性标注等任务都属于序列标注的范畴。命名实体识别(Named Entity Recognition,NER),是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。
在美团点评业务场景下,NER主要需求包括搜索Query成分分析,UGC文本中的特定实体(标签)识别/抽取,以及客服对话中的槽位识别等。NLP中心和酒店搜索算法团队合作,基于MT-BERT微调来优化酒店搜索Query成分分析任务。酒店Query成分分析任务中,需要识别出Query中城市、地标、商圈、品牌等不同成分,用于确定后续的召回策略。
在酒店搜索Query成分分析中,我们对标签采用“BME”编码格式,即对一个实体,第一个字需要预测成实体的开始B,最后一个字需要预测成实体的结束E,中间部分则为M。以图13中酒店搜索Query成分分析为例,对于Query “北京昆泰酒店”,成分分析模型需要将“北京”识别成地点,而“昆泰酒店”识别成POI。MT-BERT预测高频酒店Query成分后通过缓存提供线上服务,结合后续召回策略,显著提升了酒店搜索的订单转化率。

图13 酒店Query的成分分析
未来展望
1. 一站式MT-BERT训练和推理平台建设
为了降低业务方算法同学使用MT-BERT门槛,我们开发了MT-BERT一站式训练和推理平台,一期支持短文本分类和句间关系分类两种任务,目前已在美团内部开放试用。
基于一站式平台,业务方算法同学上传业务训练数据和选择初始MT-BERT模型之后,可以提交微调任务,微调任务会自动分配到AFO集群空闲GPU卡上自动运行和进行效果验证,训练好的模型可以导出进行部署上线。
2. 融入知识图谱的MT-BERT预训练
正如前文所述,尽管在海量无监督语料上进行预训练语言模型取得了很大的成功,但其也存在着一定的不足。BERT模型通过在大量语料的训练可以判断一句话是否通顺,但是却不理解这句话的语义,通过将美团大脑等知识图谱中的一些结构化先验知识融入到MT-BERT中,使其更好地对生活服务场景进行语义建模,是需要进一步探索的方向。
3. MT-BERT模型的轻量化和小型化
MT-BERT模型在各个NLU任务上取得了惊人的效果,由于其复杂的网络结构和庞大的参数量,在真实工业场景下上线面临很大的挑战。如何在保持模型效果的前提下,精简模型结构和参数已经成为当前热门研究方向。我们团队在低精度量化、模型裁剪和知识蒸馏上已经做了初步尝试,但是如何针对不同的任务类型选择最合适的模型轻量化方案,还需要进一步的研究和探索。
参考文献
[1] Peters, Matthew E., et al. "Deep contextualized word representations." arXiv preprint arXiv:1802.05365 (2018).
[2] Howard, Jeremy, and Sebastian Ruder. "Universal language model fine-tuning for text classification." arXiv preprint arXiv:1801.06146 (2018).
[3] Vaswani, Ashish, et al. "Attention is all you need." Advances in neural information processing systems. 2017.
[4] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya Sutskever. 2018. Improving Language Understanding by Generative Pre-Training. Technical report, OpenAI.
[5] Devlin, Jacob, et al. "Bert: Pre-training of deep bidirectional transformers for language understanding." arXiv preprint arXiv:1810.04805 (2018).
[6] Ming Zhou. "The Bright Future of ACL/NLP." Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. (2019).
[7] Deng, Jia, et al. "Imagenet: A large-scale hierarchical image database." 2009 IEEE conference on computer vision and pattern recognition. Ieee, (2009).
[8] Girshick, Ross, et al. "Rich feature hierarchies for accurate object detection and semantic segmentation." Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
[9] Mikolov, Tomas, et al. "Distributed representations of words and phrases and their compositionality." Advances in neural information processing systems. 2013.
[10] Jeffrey Pennington, Richard Socher, and Christopher D. Manning. 2014. Glove: Global vectors for word representation. In EMNLP.
[11] Oren Melamud, Jacob Goldberger, and Ido Dagan.2016. context2vec: Learning generic context embedding with bidirectional lstm. In CoNLL.
[12] Hochreiter, Sepp, and Jürgen Schmidhuber. "Long short-term memory." Neural computation 9.8 (1997): 1735-1780.
[13] 张俊林. 从Word Embedding到BERT模型—自然语言处理中的预训练技术发展史. https://zhuanlan.zhihu.com/p/49271699
[14] Sebastion Ruder. "NLP's ImageNet moment has arrived." http://ruder.io/nlp-imagenet/. (2019)
[15] Liu, Yinhan, et al. "Roberta: A robustly optimized BERT pretraining approach." arXiv preprint arXiv:1907.11692 (2019).
[16] 郑坤. 使用TensorFlow训练WDL模型性能问题定位与调优. https://tech.meituan.com/2018/04/08/tensorflow-performance-bottleneck-analysis-on-hadoop.html
[17] Uber. "Meet Horovod: Uber’s Open Source Distributed Deep Learning Framework for TensorFlow". https://eng.uber.com/horovod/
[18] Goyal, Priya, et al. "Accurate, large minibatch sgd: Training imagenet in 1 hour." arXiv preprint arXiv:1706.02677 (2017).
[19] Baidu. https://github.com/baidu-research/baidu-allreduce
[20] Micikevicius, Paulius, et al. "Mixed precision training." arXiv preprint arXiv:1710.03740 (2017).
[21] 仲远,富峥等. 美团餐饮娱乐知识图谱——美团大脑揭秘. https://tech.meituan.com/2018/11/22/meituan-brain-nlp-01.html
[22] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
[23] Google. ALBERT: A Lite BERT for Self-supervised Learning of Language Representations. https://openreview.net/pdf?id=H1eA7AEtvS. (2019)
作者简介
杨扬,佳昊,礼斌,任磊,峻辰,玉昆,张欢,金刚,王超,王珺,富峥,仲远,都来自美团搜索与NLP部。
欢迎加入美团深度学习技术交流群,跟作者零距离交流。如想进群,请加美美同学的微信(微信号:MTDPtech03),回复:BERT,美美会自动拉你进群。
---------- END ----------