TextCNN-基于卷积神经网络的文本分类
1 简述
在没有监督数据的时候,采用无监督算法的方式可以计算两句话的相似度,即通过一些因子,比如语序、词性、共现词比例等等进行打分,最后通过加权计算的方式得到最终的相似分值,最终结果主要依赖因子即特征的提取和加权公式的设计,相关项目可以参考Kaggle Quora比赛华人第一名的解决方案,里面有一些优秀的可借鉴特征。
但是最终想要更好的效果必然要使用到有监督的算法,而现有较好的技术便是TextCNN。本文主要是整理捋顺一下TextCNN的整个过程以及背后的一些原理,包括自己踩坑的点,还有Tensorflow的一些框架问题。
2 项目
CNN做文本分类的项目及代码可以参考: TextCNN
3 论文
CNN做文本分类的论文可以参看: Convolutional Neural Networks for Sentence Classification
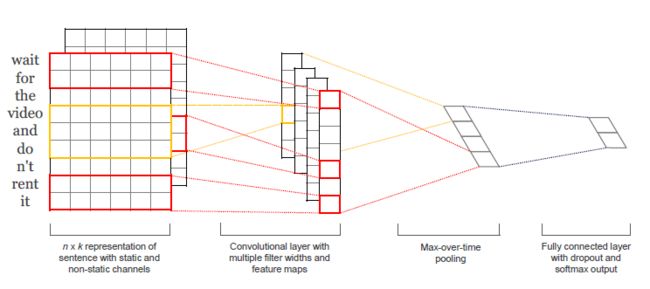
paper_models.png
上图是论文中给出的模型结构,但是这张图不是很清楚,下图可以更清楚的看清TextCNN的结构。
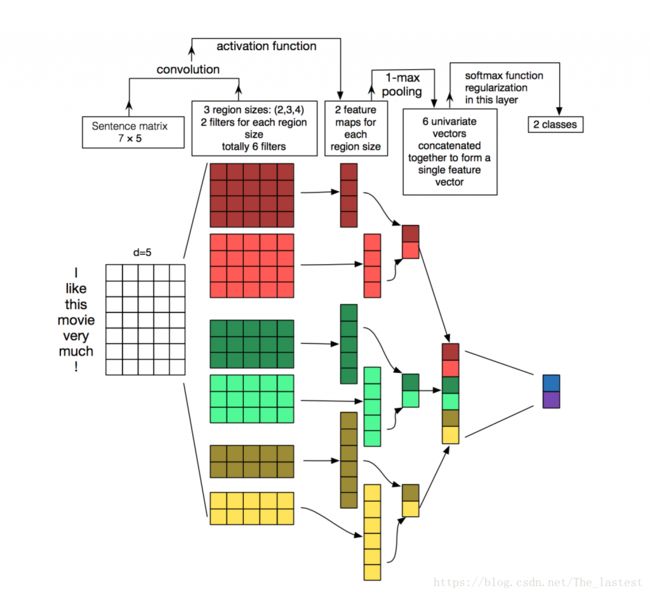
models.png
算法的主要流程是通过使用不同kernel_sizes的卷积核对文本embedding二维向量进行卷积操作,每一种kernel_sizes的卷积核有多个,这样就可以获得类似n-gram的句法特征,最后经过max_pooling,在进行一次拼接,即可以得到文档向量,经过全连接和softmax即可进行分类。
由上图所示,文档二维embedding向量为(7x5),卷积核的kernel_sizes有三种,分别为2,3,4,每种卷积核有2个,一共有2x3=6个卷积核。kernel_sizes=4的卷积核经过卷积之后得到(7-4+1)x1即4x1的向量,通过max_pooling之后得到一个数值,同理其余的5个卷积核分别进行卷积和池化操作,这样可以得到6个数值,然后将这6个数值拼接一起,注意拼接时候的维度,既可以得到文本新的向量。然后可以接全连接再接softmax即可以分类。
论文中另一case是针对算法的输入即embedding向量进行优化,可以使用Pre-trained的词向量代替随机初始化的embedding向量,分别对比随机初始化、静态预训练向量(不参与训练)、微调预训练向量(参与训练)和通过设置通道channels输入不同向量四种方式。最终效果个人感觉只能做一个参考,具体还要视业务场景而定。比如针对业务垂直领域很强的文本领域,使用基于大数据集的预训练向量可能不会有很好的效果,比如针对数码领域,如果随机初始化embedding向量,在通过train的方式更新,那么类似“苹果”之类的词语更会倾向“苹果手机”,而使用大数据集预训练的词向量,“苹果”这个词则可能更会倾向水果,这种引入预训练的方式可能会打破原有数据的结构平衡,当然如果对领域多元化的业务可能引入预训练效果会更好。另一个引入预训练词向量的好处是可以加快训练速度,这样即使效果得不到提升,但是速度得到提升也是蛮不错的。
4 代码
下面是一个标准的TextCNN的代码:
# coding: utf-8
import tensorflow as tf
import warnings
warnings.filterwarnings("ignore")
class TCNNConfig(object):
embedding_dim = 64 # 词向量维度
seq_length = 600 # 序列长度
num_classes = 10 # 类别数
num_filters = 256 # 卷积核数目
# kernel_sizes = [3, 4, 5] # 卷积核尺寸
kernel_sizes = 5 # 卷积核尺寸
vocab_size = 5000 # 词汇表达小
hidden_dim = 128 # 全连接层神经元
dropout_keep_prob = 0.5 # dropout保留比例
learning_rate = 1e-3 # 学习率
batch_size = 64 # 每批训练大小
num_epochs = 10 # 总迭代轮次
print_per_batch = 100 # 每多少轮输出一次结果
save_per_batch = 10 # 每多少轮存入tensorboard
class TextCNN(object):
def __init__(self, config):
self.config = config
# 三个待输入的数据
self.input_x = tf.placeholder(tf.int32, [None, self.config.seq_length], name='input_x')
self.input_y = tf.placeholder(tf.float32, [None, self.config.num_classes], name='input_y')
self.keep_prob = tf.placeholder(tf.float32, name='keep_prob')
self.cnn()
def cnn(self):
# 词向量映射
with tf.device('/cpu:0'):
embedding = tf.get_variable('embedding', [self.config.vocab_size, self.config.embedding_dim])
embedding_inputs = tf.nn.embedding_lookup(embedding, self.input_x)
with tf.name_scope("cnn"):
# CNN layer
conv = tf.layers.conv1d(embedding_inputs, self.config.num_filters, self.config.kernel_size, name='conv')
# global max pooling layer
gmp = tf.reduce_max(conv, reduction_indices=[1], name='gmp')
'''
for kernel_size in self.config.kernel_sizes:
gmps = []
with tf.name_scope("cnn-%s" % kernel_size):
# CNN layer
conv = tf.layers.conv1d(embedding_inputs, self.config.num_filters, kernel_size)
# global max pooling layer
gmp = tf.reduce_max(conv, reduction_indices=[1])
gmps.append(gmp)
gmp = tf.concat(values=gmps, name='last_pool_layer', axis=3)
'''
with tf.name_scope("score"):
# 全连接层,后面接dropout以及relu激活
fc1 = tf.layers.dense(gmp, self.config.hidden_dim, name='fc1')
fc2 = tf.contrib.layers.dropout(fc1, self.keep_prob)
fc = tf.nn.relu(fc2)
# 分类器
self.logits = tf.layers.dense(fc, self.config.num_classes, name='fc2')
self.y_pred_cls = tf.argmax(tf.nn.softmax(self.logits), 1) # 预测类别
with tf.name_scope("optimize"):
# 损失函数,交叉熵
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=self.logits, labels=self.input_y)
self.loss = tf.reduce_mean(cross_entropy)
# 优化器
self.optim = tf.train.AdamOptimizer(learning_rate=self.config.learning_rate).minimize(self.loss)
with tf.name_scope("accuracy"):
# 准确率
correct_pred = tf.equal(tf.argmax(self.input_y, 1), self.y_pred_cls)
self.acc = tf.reduce_mean(tf.cast(correct_pred, tf.float32))
代码中的TextCNN并没有设置可变kernel_sizes,统一设置kernel_sizes=5。通过修改注释代码即可以实现可变kernel_sizes。实验之后发现加入可变的kernel_sizes可以在实验的那个数据集上略微提升一点效果,但是提升不大,因为固定kernel_sizes=5效果就已经很好了,具体对比可以看GitHub的对比,所以在新的数据集上可以实验对比两种效果,kernel_sizes一般选2,3,4,5。
另一个困扰我比较久的是数据传输问题,数据在传送过程中的维度变化。现在就基于以上代码(tensorflow)捋顺一下数据传送过程中的维度变化。batch_size=64,seq_length=600,可得input_x (64, 600);vocab_size=5000,embedding_dim =64,可得embedding (5000, 64);embedding_inputs (64, 600, 64);num_filters=256,kernel_size=5,可得conv (64, 596, 256);gmp (64, 256);fc1 (64, 128);fc2(64, 128),fc1到fc2只经过一个dropout所以维度并没有变化;fc(64, 128),fu2到fc只经过一个relu所以维度没有变化。之后就是进行softmax操作了。
5 踩坑
- python2 对汉字真是太不友好了,各种编码问题
- 尽量不要并联太多and,不然速度会很慢,比如分词的时候可以先通过词长过滤掉一部分,然后全部收集,最后再遍历,筛掉停用词。如果分词的时候直接筛停用词,速度超级慢。
- 字符级和词语级从当前公开数据集上对比,效果相当,词语级速度更快,但是需要预先分词