吴恩达深度学习——目标检测学习
吴恩达深度学习——目标检测学习
- 目标检测概述
- 一、 目标定位:
- 1. 边界界框参数
- 2. 输出结果定义
- 3. 损失函数定义
- 二、 特征点检测
- 三、目标检测
- 1. 基于滑动窗的目标检测算法
- 2. 在卷积层中应用滑动窗目标检测
- 3. YOLO算法(一部分)
- 四、检测算法运作
- 1.交并比
- 2. 非极大值抑制
- 五、anchor box
- 六、YOLO算法
- 七、候选区域
目标检测概述
在最初接触的计算机视觉中,我们对图片进行的是图片分类,但是我们对图片中物体的位置是无从探知的,于是我们就有了一个想法,就是将物体的位置用边界框展示出来,这就是目标检测
目标检测:找到多个物体在图像中的位置
分类定位:只有一个较大的物体位于图像中央,然后对图片进行分类
一、 目标定位:
我们在做图片分类时,我们的输出层通常会采用softmax函数作为激活函数,因为他会给每一个样本产生一个向量,从而标记其类别。
假设我们做一个图片分类问题,判断图像中的物体是猪,狗,鸡,或者表示这些动物都不是。我们通常采用softmax在输出层进行激活,最后他会给每一个样本返回一个向量(如下),我们假设他的第一行表示是猪,第二行表示是狗,第三行表示是鸡,第四行表示什么也不是。
样本1 样本2 样本3 样本4
猪 [1] [0] [0] [0]
狗 [0] [1] [0] [1]
鸡 [0] [0] [1] [0]
无 [0] [0] [0] [1]
在样本1中,我们的猪显示是1,而其他是0,表明这个样本被我们的模型预测这个样本为猪,同理样本2表示我们的模型预测这个样本为狗,样本3为鸡,样本4什么都不是。
PS:真正的softmax不会这样返回,他会将图片是某个标签的可能性存在上面这样的向量中。但是概率通常是很多位小数不便于观察,并且我们通常认为概率最大的类别就是图片的类别,于是我们设定除了最大概率的标签置为1,不是最大则置为0。
1. 边界界框参数
要想给我们的目标绘制边框,我们首先需要获取目标的一些参数
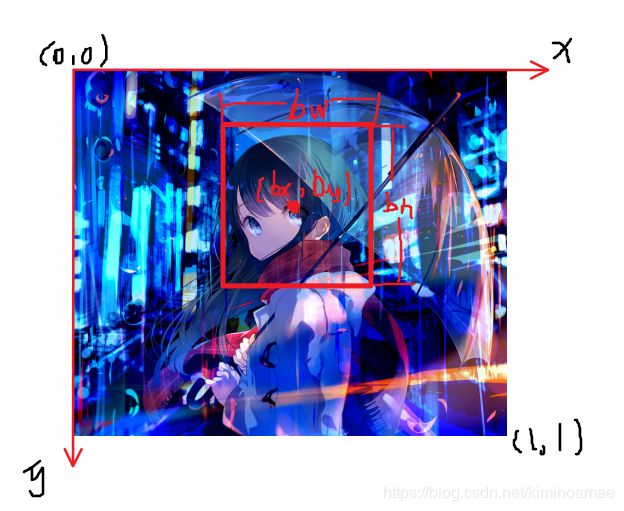
首先我们先定义图片的左上角为坐标系原点(0,0),向右为y轴的正方向,向下为x轴的负方向,定义右下角坐标为(1,1)。这样我们的坐标就会处于0~1之前,这样我们也方便判断从抽线到改点的距离相当于宽高的多少倍。
然后开始定义我们这些边界框参数的符号:
- 边界框的中心点:( b x b_x bx, b y b_y by)
- 边界框的高度: b h b_h bh
- 边界框的宽度: b h b_h bh
2. 输出结果定义
对于我们预测结果的输出需要一个标准的格式,我们现在来定义一个。
首先我们的结果应该也向softmax的输出结果一样是一个向量,但也不能只像上面一样只记录类别
以猪狗猫目标检测作为例子,为了便于解释我们选择每张图片只有一个对象
下面我们来定义一下需要记录的参数:
- pc:用于判断图片中是否存在我们需要检测的对象
- b x b_x bx, b y b_y by:我们要画的边界框的中心坐标
- b h b_h bh, b w b_w bw:我们的边界框高、宽
- c 1 c_1 c1, c 2 c_2 c2, c 2 c_2 c2, c 4 c_4 c4:我们对目标的分类
假设我们的 c 1 c_1 c1, c 2 c_2 c2, c 2 c_2 c2, c 4 c_4 c4分别表示:猪,狗,鸡,无,我们来表示一下如果图片是猪时输出的向量,和图像中没有我们的对象的图片(我们通常称这种图像为背景)。
猪 背景
pc [ 1 ] [0]
bx [0.5] [?]
by [0.5] [?]
bh [0.3] [?]
bw [0.3] [?]
c1 [ 1 ] [?]
c2 [ 0 ] [?]
c3 [ 0 ] [?]
c4 [ 0 ] [?]
对于背景来说,我们的pc自然是0,其他参数为什么置为问号呢?因为我们要进行目标检测前提是有目标在图像中,如果图像中没有目标,那我们的pc为0没问题,而既然他没有目标了,那么其他参数我们也不在乎了,所以他们是什么我们都不关心,所以置为问号。
3. 损失函数定义
对于损失函数来说我们选择的误差平方和,如果我们的pc不为0,就求每一个参数的误差平方和,反之,我们只求pc的误差平方和(只考虑pc的精确率)
L ( y , y i ) = { ( p c − p c i ) 2 + ( p c − p c i ) 2 + ⋅ ⋅ ⋅ + ( c 4 − c 4 i ) 2 , pc ≠ 0 ( p c − p c i ) 2 , pc = 0 L(y,y^i) = \begin{cases} (pc - pc^i)^2+(pc - pc^i)^2+···+(c_4 - {c_4}^i)^2,& \text{pc $\neq$ 0} \\ (pc - pc^i)^2, & \text{pc = 0 } \end{cases} L(y,yi)={(pc−pci)2+(pc−pci)2+⋅⋅⋅+(c4−c4i)2,(pc−pci)2,pc = 0pc = 0
当然选择误差平方和是为了便于理解,其实pc可以采用逻辑回归(交叉熵)来计算损失值,边界框参数使用误差平方和,目标分类可以使用softmax。
二、 特征点检测
神经网络可以通过输出图片上特征点的坐标来实现对目标特征的识别,下面我们来举两个例子
例子一:
假如我们在人脸识别过程中需要提取目标对象左眼左眼角的位置,我们可以在神经网络的最后一层多加一个参数点( l x l_x lx, l y l_y ly),如果我们需要从左到右找到各个眼角的位置我们可以多加入几个参数点( l x 1 l_{x1} lx1, l y 1 l_{y1} ly1),( l x 2 l_{x2} lx2, l y 2 l_{y2} ly2),( l x 3 l_{x3} lx3, l y 3 l_{y3} ly3),( l x 4 l_{x4} lx4, l y 4 ) l_{y4}) ly4),在记录这些点后,我们甚至能定义鼻子,下巴等点对应的位置,他们有的能帮助我们定义脸部或者是下颌的轮廓。
我们选择特征点的个数并生成包含这些特征点的标签训练集,然后就可以利用神经网络输出脸部的关键位置了,这对我们处理人类表情有很大的帮助。
我们来看下面的例子(图片来自网上搜索,侵权请与我联系)
我们先提取人脸上眼睛,鼻子,嘴巴上的特征点(下图)

在输出这些点后我们可以获得这样的点图(下图),我们可以很明显的看到点图很像一张笑脸,如果我们把它标记为笑脸,然后找到更多这样的有标记的点图作为训练集,我们是不是就能通过这样的训练集构造一个识别笑脸的神经网络了呢?

例子二:
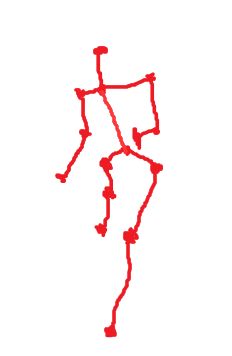
如果你对人体姿势感兴趣,我们可以定义一些关键的特征点,如胸部的中点,左肩,左肘,腰等等,然后通过神经网络标注这些关键特征点,再输出这些标注过的特征点,就相当于输出了人的姿势动作
举个实际例子
我们提取图中人物的一些关键点,然后通过神经网络标记并输出。

当我们移出图片时,能够得到一张简单的任务动作图(如下图),用和例子一相似的方法构造一个神经网络完成这类动作的识别,是不是就能识别人类姿势了呢?
特征点检测额外添加的特征点,每一个样本在输出中记录的顺序一定要是一致的,如果第一个样本第8,9个参数是人的左眼左眼角,而第二个样本第8,9个参数是人的右键左眼角,这样在训练时肯定会发生错误。
三、目标检测
1. 基于滑动窗的目标检测算法
首先我们要创建一个标签训练集,以汽车分类为例,我们将图像中有汽车标记为1,没有汽车标记为0(如下)

然后我们将图像裁剪到合适大小,使得我们的目标在图像的中央
然后我们开始滑动窗操作,首先我们得定义滑动窗的大小
之后,我们要把这个滑动窗移动到测试图片的左上角,使得滑动窗的左上角与图像的左上角对齐。
截取滑动窗内的图像,投入到卷积神经网络中,经过卷积处理,我们将得到这个滑动窗内是否含有目标(即返回1或0)。接着我们可以继续移动滑动窗,就像卷积计算那样一样。当有一个滑动窗被标记为1时,说明这个位置有我们的目标。
通常我们的图像像素都不低,如果我们一个像素一个像素得移动将会变得很慢,获得卷积输出也会变得很庞大,所以我们一般会选择较大的步长来实现滑动窗的快速移动。
当滑动窗遍历完整张测试图片后我们对测试样本的处理就结束了。我们可以选择不同大小的滑动窗对一个图片进行多次操作,这使得无论车子在什么位置,我们总有一个框能找到他

这个算法的缺点也很明显:因为在处理一张图片的过程中,传递给卷积网络的小窗口就会特别多,这就意味着很高的计算成本。
2. 在卷积层中应用滑动窗目标检测
-
把神经网络的全连接层转化成卷积层
- 我们以一个14x14x3的图像为例子,我们先使用16个5x5的过滤器将图像卷积成10x10x16的图像。
- 经过2x2的最大池化层后,我们生成一个5x5x16的图像。
- 经过全连接层后生成一个400的列向量,在做一次全连接层,放入softmax中生成标签向量。
- 这是一个普通卷积的过程,如果我们想要输入出的是一个卷积层而不是一个标签向量要怎么做呢?
- 我们和普通卷积一样做到全连接层之前,即上面得到5x5x16的图像处
- 我们不直接使其扁平化,而是使用5x5x16=400个5x5的过滤器,对其进行卷积运算,我们会获得一个1x1x100的输出
- 再用400个1x1的过滤器进行卷积,保持维度不变
- 最后用4个1x1的过滤器进行卷积,得出1x1x4的图像,这就不同于标签向量,而是一个卷积层

-
在卷积层中应用滑动窗目标检测(以一个14x14x3的图像为例)
- 我们先看一下将全连接层转化成卷积层的过程(为了表述简单,只展示了图形的正面,其实每一个正方形都是立体的)

- 现在,我们将图像的右边和下方添加两个像素,然后我们就可以得到一个16x16x3的图像,我们可以很清楚的发现右上角的图片就是我们要检测的图片。
- 现在我们使用和原图形处理相同的过滤器及个数处理图片,我们将会得到一个4x4的输出。而这4x4的输出分别代表原图形(红),原图形的右上角(绿),原图形的左下角(蓝),原图形右下角(紫)

- 对于最后输出的每一个点,都相当于是一个1x400的全连接层,将其投入到我们的softmax中,我们就会得到结果(目标是否在这个区域),然后我们就能判断目标究竟在这4个区域的哪个区域
- 这样做的原理是:我们不需要吧输入图片分割成四个子集,分别执行向前传播,而是把它作为一张图片输入给卷积层网络中进行计算,其中的公有区域可以共享很多计算。这极大提高了图片处理的计算速度。
- 放在实例中,我们不需要在每一次滑动都将剪切下来投入卷积网络中,而是整张图片投入卷积网络,一次获取所有区域的预测值,从而简化计算,提高效率。
- 他还有一个缺点就是边界框的位置可能不够准确
3. YOLO算法(一部分)
-
YOLO的意思是只看一次
-
实现过程:(以检测马路上的行人和车为例)
- 我们先把图片进行网格化(这里为了便于说明选择3x3的网格,实际运用中可能采用19x19的网格)

- 然后我们要定义标签y,我们的y应该是一个8维向量
[ pc ]是否有目标 [ bx ]目标中心点坐标 [ by ] y= [ bh ]目标的宽高 [ bw ] [ c1(人) ]目标的类别 [ c2(车) ] [ c3(背景) ]- 然后找到对象的中点,并将对象分配个包含其中点的格子,这样即使是图像在多个格子中,他从属的格子也是唯一的。
- 我们开始对9x9中的每个网格进行操作,可以很清楚得观察到我们的紫色格子是背景,他的标签向量对应y1,绿色和橙色的格子是有目标的,他们分别对应标签y2,y3
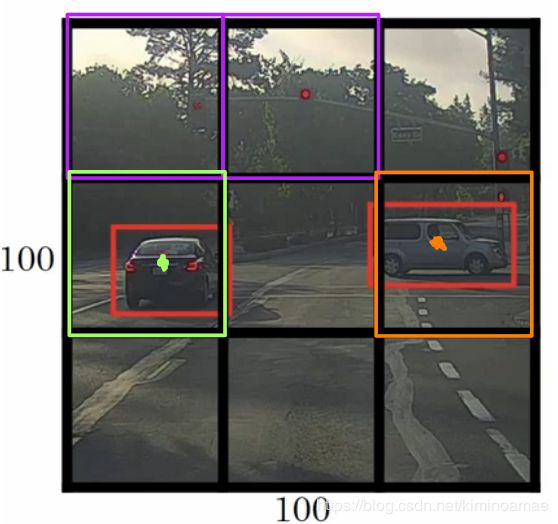
y1 y2 y3 1. pc [ 0 ] [ 1 ] [ 1 ] 2. bx [ ? ] [bx2] [bx3] 3. by [ ? ] [by2] [by3] 4. bh [ ? ] [bh2] [bh3] 5. bw [ ? ] [by2] [by3] 6. c1 [ ? ] [ 0 ] [ 0 ] 7. c2 [ ? ] [ 1 ] [ 1 ] 8. c3 [ ? ] [ 0 ] [ 0 ]- 从标签我们知道,每一个格子都对应一个8维的向量,于是我们对整张图像卷积过后的结果应该为3x3x8,每一个格子都分别代表了对应的标签
- 这个算法的优势在于,神经网络可以输出精确的边界框,同时他也是一次卷积实现的使得这个计算过程被简化
- 我们先把图片进行网格化(这里为了便于说明选择3x3的网格,实际运用中可能采用19x19的网格)
-
我们如何编码这个标签向量(以橙色方框为例子)
- 我们首先看他的中心位置,大概可以发现他到y轴的距离(x坐标)大概占据格子的30%,到x轴的距离(y坐标)大概占据格子的40%于是我们就将参数(bx,by)定义为(0.3,0.4)这个值的定义一定是在0~1之间的
- 接着我们来看边界框的宽高,他的高(竖直方向)大概占据整张格子的50%,他的宽(水平方向)大概占据格子的90%,于是我们将参数(bh,bw)定义为(0.5,0.9),但是由于我们的目标不一定全部在格子中,他可能在其他格子中也有,只是中心点正好落再我们的格子中,所以边界框的宽高是可能大于1的
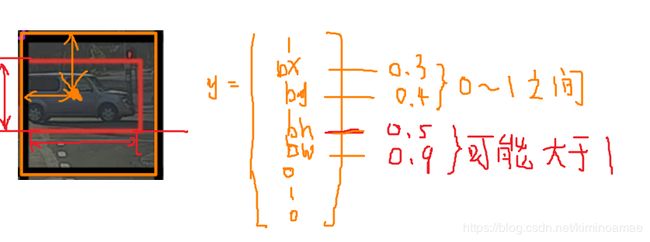
四、检测算法运作
1.交并比
我们在目标检测中画出了边界框(紫色),实际的边界框是(红色),我们要怎样才能知道我们这个紫色的边界框是否合理呢。

首先我们得先划分他们的交集和并集,交集就是两个框相交部分(橙色),并集就是两者一共所占面积(绿色),然后求橙色和绿色方框的面积
并 交 比 = 橙 色 面 积 绿 色 面 积 并交比 = \frac {橙色面积}{绿色面积} 并交比=绿色面积橙色面积
我们通常吧并交比的值定为0.5如果大于这个值就是效果良好,否则,效果不佳。
有些研究人员会把这个阈值设置为0.6,0.7,但0.5是最低阈值了,一般不会有人设置其为0.5以下的
2. 非极大值抑制
在检测图片过程中,我们检测对象可能不只检测一次,于是我们引入了非极大抑制,他能帮助我们只检测一次
我们举个检测汽车的例子
像下面这张图片,我们将其用19x19的格子划分,我们会发现他不在是一个对象大部分在一个格子中,有多个格子的大部分都是包含对象的(如图中的绿色,黄色格子),他们都会生成一个概率(pc)来说明自己的格子内有很大的可能性有对象,从而使得会产生多个边界框。

生成的边界框大概是这样
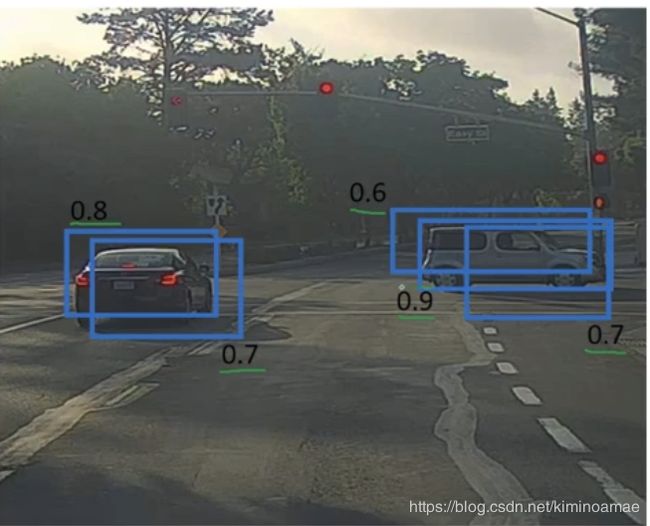
我们将每一个边界框的pc标记在他的边界框附近
非极大抑制的思路是这样的,我们先考虑他的pc值(我们的这个边界框有多大的概率有对象),我们需要定一个阈值(通常定为0.6),如果小于这个阈值,那我们可以说这个边界框有对象的概率太低了,我们不要了,于是就舍弃了这些边界框了。
然后我们找到,每一个对象最大pc值的边界框,对他进行高亮处理,对于与这个高亮边界框有很大并交比的边界框,我们进行暗淡处理或者说直接舍弃。因为我们已经有最优的边界框了,为什么还要考虑其他的呢?因此,这一过程主要有两步
一、找到最优边界框
二、舍弃和最优边界框有很大并交比的边界框
五、anchor box
anchor box 能解决两个对象出现在同一个格子里的问题
以人车模型为例子我们的标签y通常设置为8个维度,放到9x9的网格中,就会形成一个3x3x8的一个矩阵
anchor box究竟是什么呢?我们举一个简单的例子。如图现在人和车的中心点落在了同一个格子中,那么此时我们的这个格子就会变成有两个对象的格子,再用之前的方式来定义我们的标签显得不那么合适。但是,我们可以像图中一样生成两个边界框(一般是水平和竖直)分别称为anchor box1 和anchor box2。现在我们来重新定义一下用anchor box处理后的标签。

对于一个对象来说,我们只用定义一个边界框的参数即可,但这时有两个对象,我们是不是能把这两个边界框整合成一个边界框呢?答案是可以的!我们来看看具体怎么定义。(c1人,c2车,c3背景)
我们将两个anchorbox整合到一个标签
1. [pc1]
2. [bx1]
3. [by1]
4. [bh1] 前八个我们定义为第一个anchorbox
5. [bw1] 他用来检测人的模型
6. [c 1]
7. [c 2]
8. [c 3]
9. [pc2]
10. [bx2]
11. [by2]
12. [bh2] 后八个我们定义为第二个anchorbox
13. [bw2] 他用来检测车的模型
14. [c 1]
15. [c 2]
16. [c 3]
根据上述定义的标签我们可以得到图像边界框对应的标签为:
图中标签 如果在某个时刻人离开了车前的标签(我们不在乎第一个anchorbox有什么)
1. [ 1 ] [ 0 ]
2. [bx1] [ ? ]
3. [by1] [ ? ]
4. [bh1] [ ? ]
5. [bw1] [ ? ]
6. [ 1 ] [ ? ]
7. [ 0 ] [ ? ]
8. [ 0 ] [ ? ]
9. [ 1 ] [ 1 ]
10. [bx2] [bx2]
11. [by2] [by2]
12. [bh2] [bh2]
13. [bw2] [bw2]
14. [ 0 ] [ 0 ]
15. [ 1 ] [ 1 ]
16. [ 0 ] [ 0 ]
这样的标签就能帮助我们在一个格子里画出两个边界框来代表两个对象了,如果是三个对象呢?效果可能就没这么好了。anchor box一般只会用水平和竖直的边界框去处理。
六、YOLO算法
在第三点的时候我们介绍了一部分YOLO算法,现在我们将之前讲的部件组合成我们的YOLO算法
首先我们还是要定义一下我们的标签,就是采用anchor box的标记方法,我们都知道如果我们采用的3x3的网格划分,最后获得结果必然是3x3x16(或3x3x2x8),下面展示几种标记
一个格子中有两个物体 一个格子中有一个个体且 没有目标在格子中
水平的边界框与实际边界
框有更高的并交比
1. [ 1 ] [ 0 ] [ 0 ]
2. [bx1] [ ? ] [ ? ]
3. [by1] [ ? ] [ ? ]
4. [bh1] [ ? ] [ ? ]
5. [bw1] [ ? ] [ ? ]
6. [ 1 ] [ ? ] [ ? ]
7. [ 0 ] [ ? ] [ ? ]
8. [ 0 ] [ ? ] [ ? ]
9. [ 1 ] [ 1 ] [ 0 ]
10. [bx2] [bx2] [ ? ]
11. [by2] [by2] [ ? ]
12. [bh2] [bh2] [ ? ]
13. [bw2] [bw2] [ ? ]
14. [ 0 ] [ 0 ] [ ? ]
15. [ 1 ] [ 1 ] [ ? ]
16. [ 0 ] [ 0 ] [ ? ]
在实际操作过程中对于没有对象的物体我们不可能直接用?标记,他会变成一些数字,但是这些数字没有意义或者我们不关心
然后我们开始执行非极大抑制,这很简单只需要三步就可以了
第一步、 舍弃所有pc值(有目标的概率)小于阈值的边界框
第二步、 给予pc值最大的边界框高亮,一般这个pc值越高,他与我们的实际边界框的交并比也越大
第三步、 舍弃其与的边界框
经过这些步骤我们的YOLO算法就构建完成了
七、候选区域
在移动窗法中,我们会遍历每一个角落,就是说,无论图片是不是有我们要检测的对象我们都要对他进行检测,那我们不希望这些什么都没有的东西带入到算法中影响效率,于是我们有一个叫带区域的CNN(R-cnn)这种方法,就是我们尝试选择一部分有意义的窗口,然后在这些区域上运行卷积网络分类器。
R-CNN与CNN最大的不同就在与他有一个分割算法,用来判断那一块区域可能是有对象的一类算法。这一算法你可能会找到很多个色块,然后在这些色块上放置边界框,然后在这些色块上跑一下分类器,这要处理的位置应该比直接使用滑动窗处理得少,从而减少卷积网络分类器的运行时间。
在R-CNN运行的分割算法中,会产生可能的边界框,然后对他应用图片分类器,但是并不会直接将它的边界框作为结果,而是重新生成一个精度更高的边界框
法中,我们会遍历每一个角落,就是说,无论图片是不是有我们要检测的对象我们都要对他进行检测,那我们不希望这些什么都没有的东西带入到算法中影响效率,于是我们有一个叫带区域的CNN(R-cnn)这种方法,就是我们尝试选择一部分有意义的窗口,然后在这些区域上运行卷积网络分类器。
R-CNN与CNN最大的不同就在与他有一个分割算法,用来判断那一块区域可能是有对象的一类算法。这一算法你可能会找到很多个色块,然后在这些色块上放置边界框,然后在这些色块上跑一下分类器,这要处理的位置应该比直接使用滑动窗处理得少,从而减少卷积网络分类器的运行时间。
在R-CNN运行的分割算法中,会产生可能的边界框,然后对他应用图片分类器,但是并不会直接将它的边界框作为结果,而是重新生成一个精度更高的边界框
R-CNN唯一的确定就是运行太慢了,一些人也提出了解决方案,比如使用卷积实现滑动窗法。但事实上,他聚类得到的候选区域的过程仍然非常缓慢。还有一些人用卷积网络来代替分割算法,这使得速度又一次提升。但是在现实看来,R-CNN的速度用什么办法提升,都不如yolo的效率高。
总结:第一次写博客啊,讲得不对的地方请大佬指正啊,来都来了不点个赞再走吗?!!︿( ̄︶ ̄)︿