飞桨PaddlePaddle-Python小白逆袭大神课程总结
引言
人工智能,早在计算机发展之初,就被人们提出并成为一个研究方向。随着大数据时代的到来和软硬件技术的迅速进步,人工智能进入发展的黄金时期。Python作为学习AI技术的一大利器,百度飞桨7日训练营不仅让笔者体验到了AI技术的魅力,也让笔者明白“人生苦短,我用Python”的意义所在。
AI与Python之概述
人工智能,机器学习,深度学习,一张图告诉你!
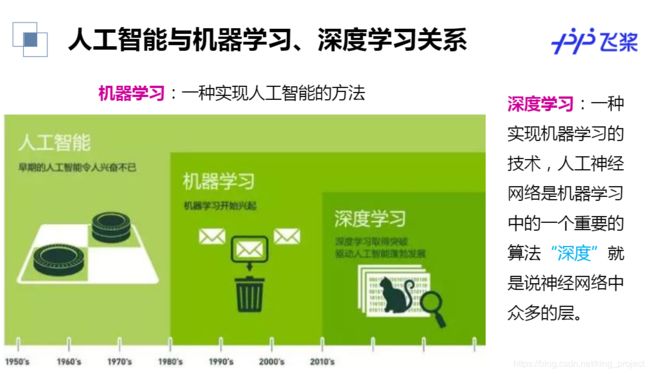
今天的人工智能尚处于弱人工智能阶段,目前的AI技术也大都是解决一些数据庞大,多有重复机械式动作的问题。所以,即使能打败人类围棋顶尖高手的AlphaGo也只不过是一个只会弈棋的“机器”,它确实干不了其他的。
但是,未来,AI拥有“思考力”,达到强人工智能阶段,或许可期!
同样的,Python作为一门早已存在的语言,AI技术的迅速发展,与其紧密相关。
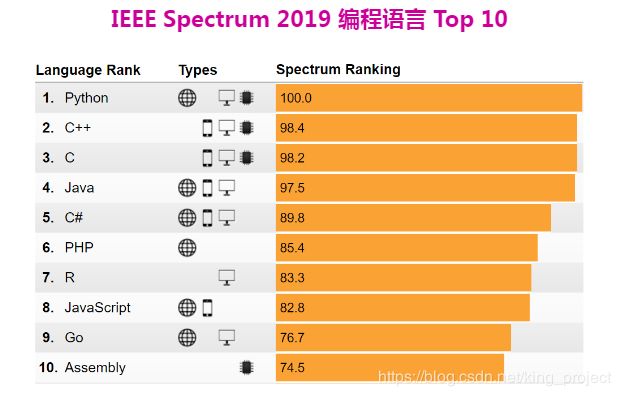
Python的语法极其简单,不像C、C++、Java…那么繁琐,反而与Matlab较为相似。AI技术中,常用Python作为开发语言。

Python是一门动态解释型语言,它之所以有强大的应用能,在于其广泛的模块(或包)。就是浏览器使用插件一样,Python引入各种各样的包来扩充其功能。
所以,学习AI不仅得掌握Python基础语法,也得熟练使用各种包。

爬虫——释放你的双手
爬虫的过程,就是模仿浏览器的行为,往目标站点发送请求,接收服务器的响应数据,提取需要的信息,并进行保存的过程。
Python为爬虫的实现提供了工具:requests模块、BeautifulSoup库
Requests:简单易用的HTTP库,网址:http://cn.python-requests.org/zh_CN/latest/
BeautifulSoup:可从HTML/XML中提取数据的Python库,网址:https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
上网的全过程:
普通用户:
打开浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 渲染到页面上
爬虫程序:
模拟浏览器 --> 往目标站点发送请求 --> 接收响应数据 --> 提取有用的数据 --> 保存到本地/数据库
爬虫的过程:
1. 发送请求(requests模块)
2. 获取响应数据(服务器返回)
3. 解析并提取数据(BeautifulSoup查找或者re正则)
4. 保存数据
通常来讲,requests模块发送请求后,服务器会返回一个html文本。所以需要用BeautifulSoup模块方法解析并提取数据将其存为Json格式的文件。下面为requests请求和BeautifulSoup处理返回数据的主要代码。
try:
response = requests.get(link,headers=headers)
#返回人物详情页文档对象
soup = BeautifulSoup(response.text,'lxml')
#返回包含相册集链接地址的所有标签
tables = soup.find_all('div',{'class':'summary-pic'})
#请求相册集链接地址
photoset = requests.get('https://baike.baidu.com'+ tables[0].find('a').get('href'),headers=headers)
#返回包含相册集页的所有标签
soup2 = BeautifulSoup(photoset.text,'lxml')
#返回包含相册集图片的所有标签
tag = soup2.find_all('a',{'class':'pic-item'})
#遍历取图片地址
for item in tag:
pic_urls.append(item.find('img').get('src').split('?')[0])
except Exception as e:
print(e)
PaddleHub——拯救你的发量
通常,初学AI技术的人,往往会因为多用数学语言描述的模型,数据清洗,数学模型…望而却步。在飞桨的7日训练营中,老师向学员介绍了使用PaddleHub框架来实现深度学习的应用。使用已有的模型,或迁移学习,或直接应用,略去繁琐的数据处理,模型建立,优化模型…的步骤。

码农界有句戏言:“发量与代码量成反比”。
事实上,python语言精简凝练,现有的较为完善的深度学习框架(如PaddleHub,TensorFlow,PyTorch)不仅多大的减少了代码量(保住了头发的小命~),而且对于初学者系统的学习深度学习的实现过程和应用具有很好的典范作用。

AI实战——《青春有你2》评论分析
以下是结合PaddleHub对爱奇艺《青春有你2》评论数据爬取,并进行词频统计和绘制词云。
重要的包:中文分词需要jieba、词云绘制需要wordcloud...
模型配置:使用porn_detection_lstm进行迁移学习
数据获取与预处理
def getMovieinfo(url):
'''
请求爱奇艺评论接口,返回response信息
参数 url: 评论的url
:return: response信息
'''
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'}
try:
response = requests.Session().get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
except Exception as e:
print(e)
def saveMovieInfoToFile(lastId,arr):
'''
解析json数据,获取评论
参数 lastId:最后一条评论ID arr:存放评论文本的list
:return: 新的lastId
'''
url = 'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=null&business_type=17&content_id=15068699100&hot_size=0&last_id='
url += lastId
comment_json = json.loads(getMovieinfo(url))
comment_list = comment_json['data']['comments']
for val in comment_list:
if 'content' in val.keys():
arr.append(val['content'])
# print(val['content'])
lastId = str(val['id']) # 下一分页评论id
return lastId
主程序
#评论是多分页的,得多次请求爱奇艺的评论接口才能获取多页评论,有些评论含有表情、特殊字符之类的
#num 是页数,一页10条评论,假如爬取1000条评论,设置num=100
if __name__ == "__main__":
num = 150
lastId = '0' # 评论分页id
arr = [] # 暂存爬取的评论
# 判断文件是否存在,path为文件路径
path = '/home/aistudio/iQiYi_comments.txt'
if os.path.exists(path):
os.remove(path)
with open('iQiYi_comments.txt','a',encoding='utf-8') as f:
for i in range(num):
lastId = saveMovieInfoToFile(lastId,arr)
time.sleep(0.5) # 间隔0.5s再次访问
for item in arr:
i_comment = clear_special_char(item) #去除文本中特殊字符
if i_comment.strip() != '':
try:
f.write(i_comment+'\n')
except Exception as e:
print(e)
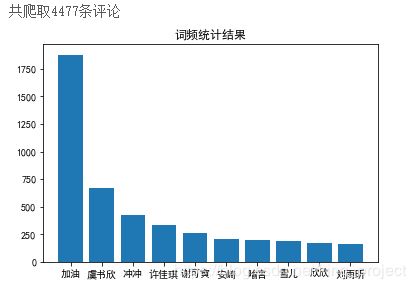
print('共爬取{}条评论'.format(len(arr)))
with open('iQiYi_comments.txt','r',encoding='utf-8') as f:
counts = {}
for line in f:
words = fenci(line)
stopwords = stopwordslist('stopwords.txt') # 创建停用词表
movestopwords(words,stopwords,counts) # 去除停用词,统计词频
drawcounts(counts,10) # 绘制词频统计表
drawcloud(counts) # 根据词频绘制词云图
test_text = []
text_detection(test_text,'iQiYi_comments.txt')
最终效果