反爬虫,使用代理,爬取获取微信文章内容
爬虫和反爬虫是相辅相成的,本文介绍反爬虫案例
1,搜狗网页可以直接获取微信的文章
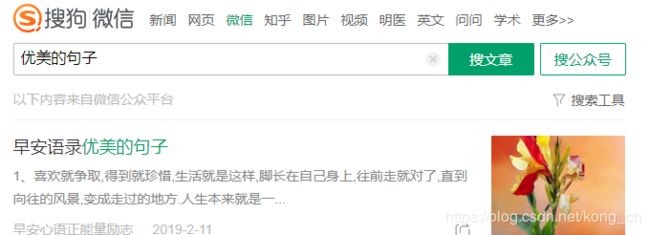
2,分析 请求相应 发现第一个页面的相应内容在页面显示出来
简化url地址 发现很多没用的参数,最后得到
https://weixin.sogou.com/weixin?query=%E4%BC%98%E7%BE%8E%E7%9A%84%E5%8F%A5%E5%AD%90&type=2&page=3&ie=utf8

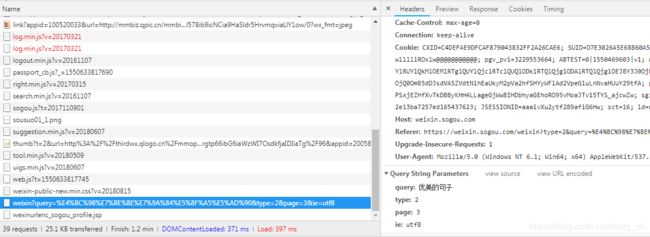
请求需要携带4个参数,分别为 query,type,page,ie。刚好是我们想要的。
data={
'query':keyword,
'type': 2,
'page':page,
'ie': 'utf8'
}
# 把字典进行编码 变成以 get请求参数的类型
queries=urlencode(data)
3,当进行request请求的时候会得不到自己想要的数据,原因是自己没有加上请求,还需要携带自己的cookies。
例如
headers={
'Cookie':'CXID=C4DEFAE9DFCAF879043832FF2A26CAE6; SUID=D7E3026A5E68860A5C2EF1090000B5C4; IPLOC=CN1100; SUV=0053D4546A0',
'Host': 'weixin.sogou.com',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36'
}
response=requests.get(url,allow_redirects=False,headers=headers,proxies=proxies)4,当多次请求的时候会出现没有办法获取,这时候你的代理被封了,需要自己设置新的代理,参数proxies就是代理。
这里引用了基于redis和flask的 免费代理组件,可以达到实时更新,判断代理是否可用等供能。代理的完整代码
https://github.com/germey/proxypool
5,引用代理,如果请求一次之后报异常错误,那么使用代理进行请求,还不对,换别的代理进行请求。代理提供为一个完整的接口,请求接口,获取即可。
具体代码如下
获取代理
def get_proxy():
try:
response=requests.get(proxy_pool_url)
if response.status_code == 200:
return response.text
except ConnectionError:
return None
使用代理爬取微信文章
def get_html(url,count=1):
print('Crawing',url)
print('Tring Count',count)
global proxy
global proxies
if count>= max_count:
print('请求次数太多了')
return None
try:
if proxy:
# 设置代理
proxies={
'http':'http://'+proxy
}
#allow_redirects=False 不让它自动跳转 proxies 代理
response=requests.get(url,allow_redirects=False,headers=headers,proxies=proxies)
if response.status_code == 200:
return response.text
if response.status_code == 302:
print('302')
proxy=get_proxy()
if proxy:
print('Using Proxy',proxy)
count+=1
return get_html(url)
else:
print('Get Proxy Failed')
return None
except ConnectionError as e:
print('Error',e.args)
proxy=get_proxy()
count+=1
return get_html(url,count)
6,完整代码参见我的gethub https://github.com/kongchuihang/Weixin_crawel