LSTM复现(pytorch)用到的知识点总结
构建数据集使用torchtext
TEXT = torchtext.data.Field(lower=True)
train, val, test = torchtext.datasets.LanguageModelingDataset.splits(path=r"D:\pytorch\PyTorchclass\data\class2\text8\text8", train="text8.train.txt", validation="text8.dev.txt", test="text8.test.txt",
text_field=TEXT)
构造了训练集、交叉验证集、测试集。
构建词汇表:
TEXT.build_vocab(train, max_size=MAX_VOCAB_SIZE)
print(type(TEXT.vocab.itos)) # itos全程idx_to_word,是一个list,存放所有词汇

print(type(TEXT.vocab.stoi)) # stoi即word_to_idx,是一个字典,key为word,idx为value

构造.BPTTIterator迭代器:
train_iter, val_iter, test_iter = torchtext.data.BPTTIterator.splits((train, val, test), batch_size=BATCH_SIZE,device=device, bptt_len=50, repeat=False, shuffle=True)
迭代器需要通过iter()再next()访问
it = iter(train_iter)
print(next(it)) # [torchtext.data.batch.Batch of size 32][.text]:[torch.cuda.LongTensor of size 50x32 (GPU 0)][.target]:[torch.cuda.LongTensor of size 50x32 (GPU 0)]
print(next(it).text)
print(next(it).target)
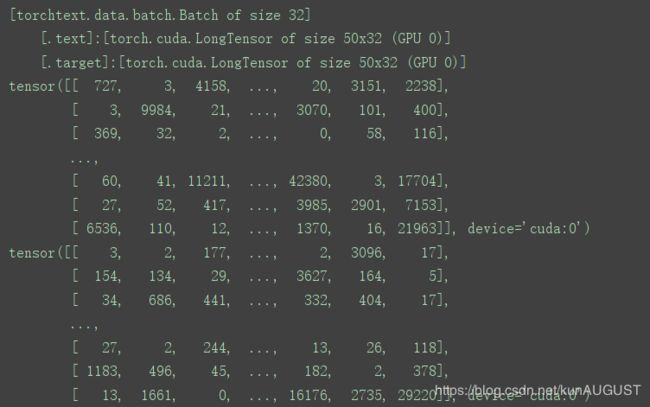
其中torch.text的维度是(seq_len,batch_sieze),也就是每一列对应一个句子(包括50个单词),而每一行表示一次输入(batch_size表示同时输入的数据维度)
print(next(it).text.size())
![]()
构建网络:
vocab_size表示词汇表的总词汇个数(50002)
embed_size = 100 表示词向量的维度(也就是,将每个单词表示成一个向量,这个向量的维度)
hidden_size表示LSTM网络中cell的个数。
在搭建网络时有
emb层:将text(seq_len, batch_sieze)映射为(seq_len, batch_sieze,embed_size)

也就是说,输入从二维变成三维,seq_len是按时间读入的,在同个时间点t,只需要考虑水平这个维度即可
现在我们拿到了(batch_sieze,embed_size)这个矩阵,也就是X(t) 来把它传入LSTM
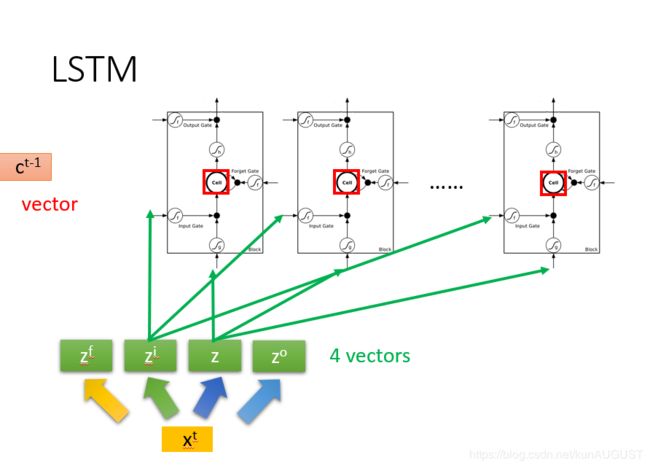
我们要从X(t)获得ZF,ZI,Z,ZO,需要乘4个权重矩阵weight(这也就是网络要训练的内容),假设我的weight权重是(embed_size, num_cell)维的,那么我的Z的维度就是(batch_size, num_cell)维的。如果不考虑batch_size的话就是(1, num_cell)维的,是一个vector,与LSTM的cell维度相同。
在这里,num_cell的维度一定是与Z的维度相同的,在构建神经网络时,它叫hidden_size
问题一:在NLP任务中,词向量维度(embedding size)是否一定要等于LSTM隐藏层节点数(hidden size)?
当然不是,embed_size乘了weight得到hidden_size, 两者是不同的
参考:https://www.codetd.com/article/952604
class RNNModel(nn.Module):
def __init__(self, vocab_size, embed_size, hidden_size):
super(RNNModel, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size)
self.linear = nn.Linear(hidden_size, vocab_size)
self.hidden = hidden_size
def forward(self, text, hidden):
# text:(seq_len, batch_size)
emb = self.embed(text)
# emb:(seq_len, batch_size, embed_size)
output, hidden = self.lstm(emb, hidden)
# output:(seq_len, batch_size, hidden_size)
# hidden:(1, batch_size, hidden_size) (1, batch_size, hidden_size)
out_vocab = self.linear(output.view(-1, output.shape[2])) # 线性变换要求输入为二维的
out_vocab = out_vocab.view(output.size(0), output.size(1), out_vocab.size(-1)) # 变回3维
return out_vocab, hidden