分布式存储综述、存储原理与设计
目录
分布式存储概念
分布式文件系统的发展
分布式存储系统的分类
数据类型三大类
分布式存储类型
分布式存储系统的特性
单机存储原理与设计
多机存储原理与设计
FLP定理与设计
CAP定理与设计
2PC协议与设计
Paxos协议与设计
这篇博客主要来总结一下分布式存储系统的历史,发展以及特性,从而对分布式存储系统有一个大概的了解,主要从一下几个部分来介绍分布式存储:
分布式存储概念
分布式存储系统顾名思义就是将大量的普通服务器,通过网络互联,对外作为一个整体提供存储服务。具有可扩展性、可用性、可靠性、 高性能、易维护、低成本等特性。
分布式文件系统的发展
- 80年代
· 代表:AFS、NFS、Coda
· AFS:1983年 Carnegine Mellon大学和IBM共同合作开发Andrew文件系统(Andrew File System, AFS),AFS设计目标是将至少7000个工作站连接起来,为每个用户提供一个共享的文件系统,将高扩展性、网络安全性放在首位,客户端高速缓存,即使网络断开,可以对部分数据缓存。
· NFS:1985年Sun公司基于UDP开发了网络共享文件系统(Network File System, NFS),NFS由一系列NFS命令和进程组成的客户机/服务器(C/S)模式。NFS第三版,加入了基于TCP传输,第三版发布六年后,NFS成为Linux中的稳定版本。
· Coda:1987年 Carnegine Mellon大学在基于AFS的基础上开发了Coda文件系统,它为Linux工作站组成的大规模分布式计算环境设计的文件系统,通过两种互补机制为服务器和网络故障提供了容错机制,服务器复制机制,一个文件拷贝到多个服务器上,无连接操作机制,将缓存端暂时作为服务端的执行模式,Coda注重可靠性和性能优化,它提供了高度的一致性。
- 90年代
· 代表:xFS、Tiger Shark 、SFS…
· 背景:进入九十年代,随着Windows的问世,极大促进了微处理器的发展和PC的广泛普及,互联网和多媒体技术也犹如雨后春笋般发展起来,一方面:对多媒体数据的实时传输需和应用越来越流行,另一方面:大规模并行计算技术的发展和数据挖掘技术应用,迫切需要能支持大容量和高速的分布式存储系统。
· xFS:UC Berkeley参照当时高性能多处理器领域的设计思想开发了xFS文件系统,xFS克服了以往分布式文件系统只适用局域网,而不适用于广域网和大数据存储问题,提出广域网进行缓存较少网络流量设计思想,采用层次命名结构,减少Cache一致性状态和无效写回Cache一致性协议,从而减少了网络负载。
- 20世纪末
· 代表:SAN、NAS、GFS、HDFS、GPFS…
· 背景:到了二十世纪末,计算机技术和网络技术得到了飞速发展,磁盘存储成本不断降低,磁盘容量和数据总线带宽的增长速度无法满足应用需求,海量数据的存储逐渐成为互联网技术发展急需解决的问题,对于分布式存储系统技术的研究越来越成熟,基于光纤通道的存储区域网络(Storage Area Network)技术和网络附连存储(Network Attached Storage)技术得到了广泛应用。
· SAN:设计目标是通过将磁盘存储系统或者磁带机和服务器直接相连的方式提供一个易扩展、高可靠的存储环境,高可靠的光纤通道交换机和光纤通道网络协议保证各个设备间链接的可靠性和高效性,设备间的连接接口主要是采用FC或者SCSI,光纤通道交换机主要是为服务器和存储设备的链接提供一个称为“SAN fabric”的网状拓扑结构。
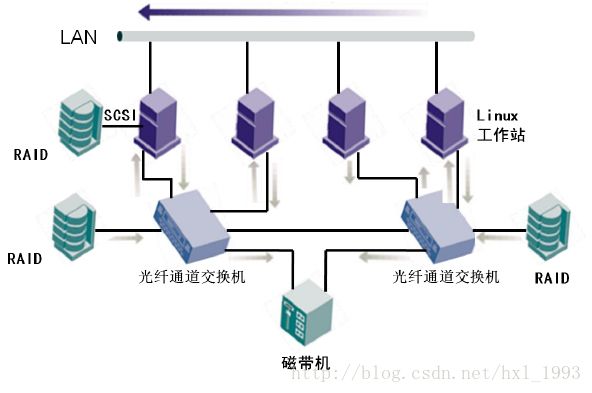
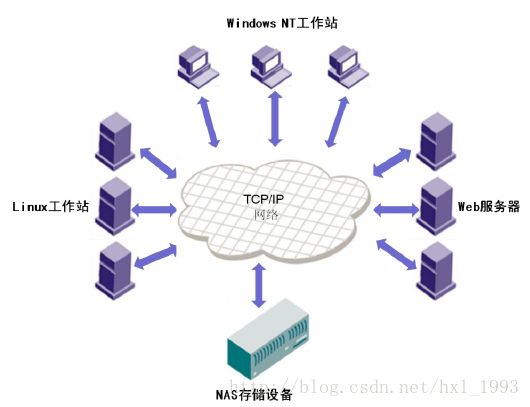
· NAS:通过基于TCP/IP协议的各种上层应用(NFS等)在各工作站和服务器之间进行文件访问,直接在工作站客户端和NAS文件共享设备之间建立连接,NAS隐藏了文件系统的底层实现,注重上层的文件服务实现,具有良好扩展性,网络阻塞,NAS性能受影响。
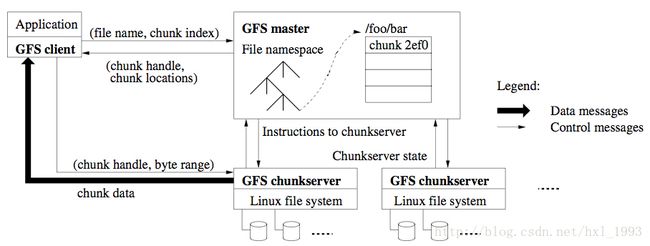
· GFS:Google为大规模分布式数据密集型应用设计的可扩展的分布式文件系统,Google将一万多台廉价PC机连接成一个大规模的Linux集群,它具有高性能,高可靠性,易扩展性,超大存储容量等优点。Google文件系统采用单Master多Chunk Server来实现系统间的交互,Master中主要保存命名空间到文件映射、文件到文件块的映射、文件块到Chunk Server的映射,每个文件块对应到3个Chunk Server。
- 现在
· 代表:HBase、Cassadra、MongoDB、DynamoDB…
· HBase:列存储数据库,擅长以列为单位读取数据,面向列存储的数据库具有高扩展性,即使数据大量增加也不会降低相应的处理速度,特别是写入速度。
· MongoDB:文档型数据库它同键值(Key-Value)型的数据库类似,键值型数据库的升级版,允许嵌套键值,Value值是结构化数据,数据库可以理解Value的内容,提供复杂的查询,类似于RDBMS的查询条件。
· DynamoDB:Amazon 公司的一个分布式存储引擎,是一个经典的分布式Key-Value 存储系统,具备去中心化,高可用性,高扩展性的特点,达到这个目标在很多场景中牺牲了一致性,Dynamo在Amazon中得到了成功的应用,能够跨数据中心部署于上万个结点上提供服务,它的设计思想也被后续的许多分布式系统借鉴。
分布式存储系统的分类
数据类型三大类
- 非结构化数据:指其字段长度不等,并且每个字段的记录又可以由可重复或不可重复的子字段构成,没有规律,比如文本、图像、声音、影视等等。
- 半结构化数据:介于完全结构化数据(如关系型数据库、面向对象数据库中的数据)和完全无结构的数据(如声音、图像文件等)之间的数据,HTML文档就属于半结构化数据。它一般是自描述的,数据的结构和内容混在一起,没有明显的区分。
- 结构化数据:结构化数据即行数据,存储在数据库里,可以用二维表结构来逻辑表达实现的数据,数据模式和内容是分开的,数据的模式需要预先定义。
分布式存储类型
- 分布式文件系统:存储大量的文件、图片、音频、视频等非结构化数据,这些数据以对象的形式组织,对象之间没有关系,这数据都是二进制数据,例如GFS、HDFS等。
- 分布式Key-Value系统:用于存储关系简单的半结构化数据,提供基于Key的增删改查操作,缓存、固化存储,例如Memached、Redis、DynamoDB等。
- 分布式数据库系统: 存储结构化数据,提供SQL关系查询语言,支持多表关联,嵌套子查询等,例如MySQL Sharding集群、MongoDB等等。
分布式存储系统的特性
- 高可用性:指分布式存储系统在面对各种异常时可以提供正常服务的能力,系统的可用性可以用系统停服务的时间和正常服务时间的比例来衡量,例如4个99的可用性(99.99%)要求一年停机的时间不能超过365*24*60/10000 = 53分钟。
- 高可靠性:重点指分布式系统数据安全方面的指标,数据可靠不丢失,主要用多机冗余、单机磁盘RAID等措施。
- 高扩展性:指分布式存储系统通过扩展集群服务器规模从而提高系统存储容量、计算和性能的能力,业务量增大,对底层分布式存储系统的性能要求越来越高,自动增加服务器来提升服务能力,分为Scale Up与Scale Out,前者指通过增加和升级服务器硬件,或者指通过增加服务器数量。衡量可扩展性的要求集群具有线性的可扩展性,系统整体性能与服务器数量呈线性关系。
- 数据一致性:分布式存储系统多个副本之间的数据一致性,有强一致性,弱一致性,最终一致性,因果一致性,顺序一致性。
- 高安全性:指分布式存储系统不受恶意访问和攻击,保护存储数据不被窃取,互联网是开放的,任何人在任何时间任何地点通过任何方式都可以访问网站,针对现存的和潜在的各种攻击与窃取手段,要有相应的应对方案。
- 高性能:衡量分布式存储系统性能常见的指标是系统的吞吐量和系统的响应延迟,系统的吞吐量是在一段时间内可以处理的请求总数,可以用QPS(Query Per Second)和TPS(Transaction Per second)衡量。系统的响应延迟是指某个请求发出到接收到返回结果所消耗的时间,通常用平均延迟来衡量。这两个指标往往是矛盾的,追求高吞吐量,比较难做到低延迟,追求低延迟,吞吐量会受影响。
- 高稳定性:这是一个综合指标,考核分布式 存储系统的整体健壮性,任何异常,系统都能坦然面对,系统稳定性越高越好。
单机存储原理与设计
1.单机存储引擎:存储引擎是存储系统的发动机,决定了存储系统能够提供的功能和性能。存储系统提供功能:Create、Update、Read、Delete(CURD)。存储引擎类型有:
- · 哈希存储引擎
- · B树存储引擎
- · LSM存储引擎
2.哈希存储引擎:基于哈希表结构的键值存储系统,数组+链表的方式实现,支持持Create、Update、Delete、随机Read,O(1)Read复杂度。
3.B树存储引擎:基于B Tree实现,支持单条记录的CURD,还支持顺序扫描、范围查找,RDBMS使用较多,例如:MySQL,InnoDB 聚簇索引,B+树。
4.LSM树存储引擎:Log Structured Merge Tree,对数据的修改增量保存在内存中,达到指定条件后(通常是数量和时间间隔),批量将更新操作持久到磁盘,读取数据时需要合并磁盘中的历史数据和内存中最近修改操作,LSM优势在于通过批量写入,规避了随机写入问题,提高写入性能,LSM劣势在于读取需要合并磁盘数据和内存数据。LSM通过Commit Log避免了内存数据丢失,首先将修改操作作写入到Commit Log中,保证操作数据的可靠性。 典型案例设计:LevelDB。
5.数据模型:数据模型是存储系统外壳,分类有:
- · 文件:以目录树的方式组织文件 Linux、Mac、Windows
- · 关系型:每个关系是一个表格,由多个行组成,每个行由于多个列组成,如MySQL、Orcale等
- · 键值(Key-Value)存储型:Memcached、 Tokyo Cabinet、Redis
- · 列存储型:Cassadra、HBase
- · 图形(Graph)数据库:Neo4J、InfoGrid、Infinite Graph
- · 文档型:MongoDB、CouchDB
6.事务与并发控制
- · 事物四个基本属性:原子性、一致性、隔离性、持久性
- · 并发控制:锁粒度,MongoDB:Process->DB->Table->Row,提供Read并发,Read不加锁:写时复制、MVCC
7.数据恢复:操作日志
多机存储原理与设计
1、单机存储与多机存储:单机存储的原理在多机存储仍然可用,多级存储基于单机存储。
2、多机数据分布:区别于单机存储,数据分布在多个节点上,在多个节点之间需要实现负载均衡,数据分布方式:
- · 静态方式:取模,uid%32。
- · 动态方式:一致性hash,会有数据漂移的问题。
- 负载均衡:多节点之间数据的均衡,负载高的节点迁移到负载低的节点(数据迁移)。
3、复制:分布式存储多个副本,保证了高可靠和高可用,Commit Log。
4、故障检测:心跳机制、数据迁移、故障恢复。
FLP定理与设计
1.FLP:FLP Impossibility(FLP不可能性)是分布式领域中一个非常著名的结果,1985年Fischer、Lynch and Patterson三位作者发表论文,并获取Dijkstra奖,在异步消息通信场景,即使只有一个进程失败,没有任何方法能够保证非失败进程达到一致性。
2.FLP系统模型基于以下几个假设:
- 异步通信:与同步通信最大区别是没有时钟、不能时间同步、不能使用超时、不能探测失败、消息可任意延迟、消息可乱序
- 通信健壮性:只要进程非失败,消息虽会被无限延迟,但最终会被送达,并且消息仅会被送达一次(重复保证)
- Fail-Stop模型:进程失败不再处理任何消息
- 失败进程数量:最多一个进程失败
3.FLP定理带给我们的启示:
1985年FLP证明了异步通信中不存在任何一致性的分布式算法(FLP Impossibility),人们就开始寻找分布式系统设计的各种因素,一致性算法既然不存在,如果能找到一些设计因素,适当取舍以最大限度满足实现系统需求成为当时的重要议题,出现了CAP定理。
CAP定理与设计
1.CAP定理:2000年Berkerly的Eric Brewer教授提出了一个著名的CAP理论,CAP是一致性(Consistency)、可用性(Availability)、分区可容忍性(Tolerance of network Partition)的首字母缩写。在分布式环境下,三者不可能同时满足。
- 一致性(Consistency):Read的数据总是最新的(Write的结果),这里指的是强一致性。
- 可用性(Availabilty):机器或者系统部分发生故障,仍然能够正常提供读写服务。
- 分区容忍性(Tolerance of network Partition):机器故障、网络故障、机房故障等异常情况下仍然能够满足一致性和可用性。
2. CAP设计:分布式存储系统需要能够自动容错,也就是说分区容忍性需要保证。如果保证一致性,需要强同步复制,主副本之间网络异常,写操作被阻塞,可用性无法保证。如果保证可用性,采取异步复制机制,保证了分布式存储系统的可用性,强一致性无法保证,设计时一致性和可用性需要折中权衡。金融行业中,不允许数据丢失,需要强一致性。
2PC协议与设计
1、2PC协议:Two Phase Commit(2PC),用于实现分布式事物,有两类节点,协调者和事物参与者,每个节点都会记录Commit Log,保证数据可靠性,两阶段提交由两个阶段组成:
- 请求阶段(Prepare Phase):协调者通知参与者准备提交或者取消事务,之后进入表决阶段,每个参与者将告知协调者自己的决策:同意or不同意
- 提交阶段(Commit Phase):收到参与者的所有决策后,进行决策:提交or取消,通知参与者执行操作:所有参与者都同意,提交 or 取消,参与者收到协调者的通知后执行操作
2、2PC协议与设计:2PC协议是阻塞式,事务参与者可能发生故障:设置超时时间,协调者可能发生故障:日志记录,备用协调者。
Paxos协议与设计
- Paxos协议:用于解决多个节点之间的一致性问题,多个节点,只有一个主节点,主节点挂掉,如果选举新的节点,主节点往往以操作日志的形式同步备节点。角色:提议者(Proposer)和接受者(Acceptor)。Proposer发送accept消息到Acceptor要求接受某个提议者,如果超过一半的Acceptor接受,意味着提议值生效,Proposer发送acknowledge消息通知所有的Acceptor提议生效。
- 2PC与Paxos:作用不同:2PC协议保证多个数据分片上操作的原子性,Paxos协议保证一个数据分片多个副本之间的数据一致性。2PC最大缺陷无法处理协调者宕机,Paxos可以处理协调者宕机,两者可以结合使用。
- Paxos协议用法:实现全局的锁服务或者命名和配置服务,将用户数据复制到多个数据中心。
---------------------
原文:https://blog.csdn.net/hxl_1993/article/details/62929904