机器学习:k-means聚类效果评估
接着上一回的工作,用kmeans聚类之后,感觉肘部法则有些问题,今天又看了一遍代码,发现fit()函数的参数输错了,应该输入归一化之后的X_norm
今天查阅了各种同学的分享,太多了,就不给出链接了,对聚类算法的评估,我筛选了下面三种方法
第一种
SSE 样本距离最近的聚类中心的距离总和 (簇内误差平方和)
只对单个族中的数据分析,族与族之间的关系没有涉及
所以可能有一定的问题
在sklearn中直接用km.inertia_就能得到
这是我使用之后的效果
#聚类
engine = create_engine('mysql+pymysql://root:123456@localhost:3306/stock?charset=utf8')
totalConcept = pd.read_sql_query(''' select * from totalConcept; ''' , engine)
totalConcept.drop(['index'],axis=1,inplace=True)
#分割数据
X, y = totalConcept.iloc[:, 1:].values, totalConcept.iloc[:, 0].values
from sklearn import preprocessing
#正则化
min_max_scaler = preprocessing.MinMaxScaler()
X_norm = min_max_scaler.fit_transform(X)
#kmeans聚类
#inertia样本到最近的聚类中心的距离总和
#肘部法则
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
distortions = []
for i in range(1, 40):
km = KMeans(n_clusters=i,
init='k-means++',
n_init=10,
max_iter=300,
random_state=0)
km.fit(X_norm)
distortions.append(km.inertia_)
plt.plot(range(1,40), distortions, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Distortion')
plt.show()
得到如下结果

哈哈哈,这是什么鬼
所以ss可能在某些情况下不适用
第二种
轮廓系数
https://blog.csdn.net/sinat_29957455/article/details/80113972
这位小伙伴分享了什么事轮廓系数
考虑了族内族外量方面的因素,系数越大越好
sklearn中
metrics.silhouette_score(X_norm, km.labels_ , metric=‘euclidean’)
可以直接计算
另外需要注意的是,使用轮廓系数,族数量必须大于等于2
使用轮廓系数评估
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
scores = []
for i in range(2, 100):
km = KMeans( n_clusters=i,
init='k-means++',
n_init=10,
max_iter=300,
random_state=0 )
km.fit(X_norm)
scores.append(metrics.silhouette_score(X_norm, km.labels_ , metric='euclidean'))
plt.plot(range(2,100), scores, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('silhouette_score')
plt.show()
我这里计算了100个族,得到结果

最大值就在 3 这里,至于到底分几类,之后在讨论
第三种
Calinski-Harabaz Index
https://blog.csdn.net/u010159842/article/details/78624135
这位笔者充分解释了这个指数
这种评估也同时考虑了族内族外的因素
类别内部数据的协方差越小越好,类别之间的协方差越大越好
sklearn中
metrics.calinski_harabaz_score
直接计算
同样进行使用
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
ch_scores = []
for i in range(2, 100):
km = KMeans( n_clusters=i,
init='k-means++',
n_init=10,
max_iter=300,
random_state=0 )
km.fit(X_norm)
ch_scores.append(metrics.calinski_harabaz_score(X_norm, km.labels_))
plt.plot(range(2,100), ch_scores, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('calinski_harabaz_score')
plt.show()
得到结果
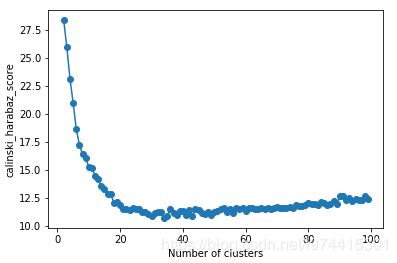
emmmmm,好吧,到底分几类,还需要联系股票中的基本面参数来分析,下一步,先可视化一下,再看下,km中的参数对结果有哪些影响,最后决定分几类,以及最终使用哪一类或者哪几类的概念