深度学习(神经网络)
温馨提示:或许笔者自己都没有搞太懂~
参考课程:YUN-NUNG (VIVIAN) CHEN的深度学习课程
参考书籍:http://lamda.nju.edu.cn/weixs/book/CNN_book.pdf
还是强烈推荐一下简单的:https://zhuanlan.zhihu.com/p/74631214
1.网络训练(神经网络前馈运算+反馈运算)
前馈运算:后一层的输入(z)=前一层的输出(a)与对应权值(w-两层间的连接线上)加权求和。

![]()
反馈运算(backpropagation):后一次迭代的权值w/偏置b=前一次迭代的权值w/偏置b-学习率×误差(Loss)对前一次迭代权值w/偏置b的偏导数
①YUN-NUNG (VIVIAN) CHEN版
- 参数:

- 损失函数:

- 梯度计算:

上图红框计算方法(最初我笔算推导时,简单的以为这一步不需要这样计算,直接求导得W(想法显然错误)。但是,现在发现,后一层的输出![]() 取决于前面所有层的计算,因此,若想笔算验证神经网络反向传播求导,可以通过构建小的神经网络验证)
取决于前面所有层的计算,因此,若想笔算验证神经网络反向传播求导,可以通过构建小的神经网络验证)

- 算法:



从这里就可以看出求偏导分成两部分后就变得很简单了。
②Xiu-Shen WEI版
- 损失函数(目标函数):
![]() (回归问题),
(回归问题),![]() (分类问题)
(分类问题)
这里的![]()
- 链式参数更新法则:

我理解为:(1.7)下一个样本![]() 对上一个样本更新的权重
对上一个样本更新的权重![]() 求偏导,然后用
求偏导,然后用![]() 更新w产生
更新w产生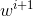 ;(1.8)细化
;(1.8)细化![]() 的求解过程。
的求解过程。

2.卷积操作
- 计算方式:图片对应位置与卷积核对应位置加权求和。(滑动的卷积核)
- 卷积核理解:其实在网络训练过程中,训练的就是卷积核对应位置的值,也就是1中前馈运算中的权重w

3.实质问题
网络训练其实就是不断更新权值w以及偏置b,权值就是卷积核中不同位置的参数值
附一篇知乎:https://zhuanlan.zhihu.com/p/27897220(通俗的讲解了图片在深度学习网络中各个实现步骤)
4.正则化
即“规则化”,防止过拟合,如:dropout层,用于丢弃一些拟合过于理想的情况。
深度学习中常用正则化操作:
①参数添加约束,如Weight Decay
②训练集合扩充,如图片旋转,缩放
③dropout,去掉部分w连接,形成子网络。如

5.AlexNet结构详述
参考网站:https://blog.csdn.net/xiequnyi/article/details/52232855
6.反卷积
就是用转置的卷积核卷积图片。
7.momentum--梯度下降加速技术
![]() ,
, 是学习率,
是学习率,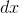 是梯度
是梯度
![]() ,
, 是一个常量(影响momentum的)
是一个常量(影响momentum的)
其中,v是momentum,上一次的v(即momentum)和这一次的负梯度方向相同,下次梯度下降的幅度就会加大,加速收敛。
8.对于目标检测的理解
1)目标检测本质:目标定位与目标识别任务的统一;
2)两个框架:①手工设计特征的传统目标检测算法②自主学习特征的深度学习目标检测算法;
3)两个深度学习目标检测框架:①基于候选区域的目标检测框架,rcnn、spp-net、fast-rcnn、faster-rcnn、r-fcn②基于回归的目标检测框架,yolo、ssd;
4)传统目标检测算法
①策略:滑动窗口,包括区域选择、特征提取、分类器设计
②特征描述:Harr小波特征、LBP局部二值特征、SIFT尺度不变特征、HOG方向直方图特征
③难识别因素:姿态、颜色、光照(有阴影)
5)一个好的概念:特征是计算机理解高层信息和人类获取原始像素信息之间的桥梁
6)卷积神经网络
①局部连接:不同的卷积核,训练过程改变卷积核的各个权重weight,训练形成之后的不同卷积核可以提取不同的局部特征;
②参数共享:不同对象都会使用同一卷积核提取特征,由此看来不同类对象需要的特征参数是共享的。可以有效的防止过拟合(原因:参数越多,拟合能力越强,减少参数量,自然可以有防止过拟合的作用);
③池化(下采样):保证对提取特征的位移、扭曲等形变特征不变性;
④底层特征偏颜色、纹理,高层特征不明确;

底层:颜色+线条 高层:抽象,表达能力更强
⑤非极大值抑制(NMS):为了删除多余的预测框,筛选出所有的最佳预测框
首先将所有预测框的得分置信度进行高低排序,选出其中得分最高的预测框,然后继续遍历剩下所有的预测框,如果与之前最高得分预测框的 IoU大于给定的阈值,则将该预测框删除,之后重复迭代上述过程,直到筛选出最佳预测框为止。


NMS前(左图) NMS后(右图)
⑥边框回归:让定位更准确
参考网站:https://blog.csdn.net/zijin0802034/article/details/77685438/
先做平移![]()
![]()
![]()
再做缩放![]()
![]()
![]()
目标损失函数: ,
,![]() 是输入 Proposal 的特征向量,
是输入 Proposal 的特征向量,![]() 是要学习的参数(*表示 x,y,w,h, 也就是每一个变换对应一个目标函数) ,
是要学习的参数(*表示 x,y,w,h, 也就是每一个变换对应一个目标函数) ,![]() 是得到的预测值。 我们要让预测值跟真实值
是得到的预测值。 我们要让预测值跟真实值![]() 差距最小。
差距最小。
⑦rcnn检测算法:

step1,对于输入图像,首先使用选择性搜索算法提取大约 2K个候选区域;
step2,使用压缩裁剪等方法使得每一个候选区域具有相同大小(227*227),并送入卷积网络进行特征提取,输出固定大
小的卷积特征向量;(相同维度的特征向量才能运用分类器分类)
step3,通过训练特定类别的线性 SVM 分类器进行分类。
缺点:每个候选区域都要进行一次卷积网络所有卷积、池化运算;压缩裁剪导致特征丢失。
⑧spp-net
参考网站:https://blog.csdn.net/v1_vivian/article/details/73275259

step1,通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
step2,特征提取阶段。这一步就是和R-CNN最大的区别了,这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化(对特征图划分3中区域:4*4,2*2,1*1,ROIPooling(7*7)的思想类似),提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度会大大提升。
step3,最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
优点:检测速度提升30~170倍,step2体现出来的。
⑨fast-rcnn

⑩faster-rcnn
小目标漏检原因:因为 Faster R-CNN 只采用 Conv5_3 卷积层产生的特征图作为 RPN 网络的输入,高层卷积特征图往往会缺少图像的细节信息,并且小目标在高层特征图中的分辨率相对更小。假如输入图像大小为512*512,经过 VGG-16 网络后得到的特征图大小为 32*32,对于特征图上的一个点就要负责周边至少 16*16 大小区域的特征表达,从而造成原图中很小物体的特征就难以得到充分的表示。
解决办法:将高分辨率、低语义信息的低层特征和低分辨率、高语义信息的高层特征进行融合,利用高层的语义信息来处理目标尺度变化的问题,同时用低层信息进行精确定位。融合多层卷积层提取融合特征图,作为 RPN 网络的输入,丰富的特征信息,提取得到更加精细化的候选区域。在目标检测阶段采用在线难例样本挖掘算法进行训练,剔除简单无用样本,对表达能力更强的有效样本进行充分训练,使得检测模型表达能力更强。
9.cross_entropy和focal_loss的理解
| 交叉熵cross_entropy | focal_loss | |
| 公式 | ||
| 正样本 (y=1) |
|
|
| 负样本 (otherwise) |
|
|
| log(p)图像 (a=10) |
||
| 总结 | focal_loss对于分类正确的样本,很大程度上减小了目标loss值,因此,反向求导更新权重的过程,weight和bias的梯度会减小,自然会削弱分类正确的样本的训练。 虽然分类错误的样本也减小了loss,但是影响程度不太大。 |
|