化繁为简,弱监督目标定位领域的新SOTA - 伪监督目标定位方法(PSOL) | CVPR 2020
论文提出伪监督目标定位方法(PSOL)来解决目前弱监督目标定位方法的问题,该方法将定位与分类分开成两个独立的网络,然后在训练集上使用Deep descriptor transformation(DDT)生成伪GT进行训练,整体效果达到SOTA,论文化繁为简,值得学习
来源:晓飞的算法工程笔记 公众号
论文: Rethinking the Route Towards Weakly Supervised Object Localization

- 论文地址:https://arxiv.org/abs/2002.11359
Introduction
由于训练数据难以大量标注,一些研究如何使用弱监督的方法来学习,弱监督的训练数据一般只包含image-level标签,无具体目标的定位标签/语义标签。在弱监督算法中,弱监督目标定位(WSOL)是最实际的任务,只需要定位给定标签的对象位置即可
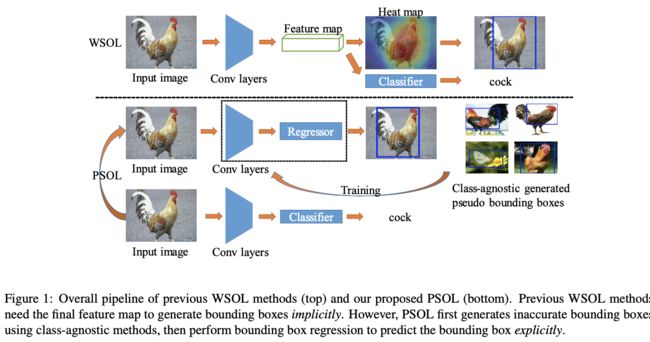
经过实验,论文认为WSOL中的定位部分应该为类不可知的,与分类无关。基于这个观察,将WSOL分为类不可知目标定位以及目标分类两部分,如图1所示,命名为伪监督目标定位(Pseudo Supervised Object Localization, PSOL)。算法首先生成通过Deep descriptor transformation(DDT)生成伪监督GT bbox,然后对这些bbox进行回归,去掉了WSOL中仅能有一层全连接的限制(当作卷积的channel-wise权重)以及定位与分类耦合导致的取舍问题
论文贡献主要如下:
- 弱监督目标定位应该分为类不可知目标定位和目标分类两个独立的部分,提出PSOL算法
- 尽管生成的bbox有偏差,论文仍然认为应该直接优化他们而不需要类标签,最终达到SOTA
- 在不同的数据集上,PSOL算法不需要fine-tuning也能有很好的定位迁移能力
Related Works
这里需要说明一下,弱监督目标定位(WSOL)与弱监督目标检测(WSOD)是不一样的,WSOL假设图片中只有一个目标,而WSOD则没有这种假设,所以WSOD一般需要额外的方法去生成region proposal
Methodology
A paradigm shift from WSOL to PSOL
当前WSOL能够生成生成带类别标签的bbox,但主要有以下几个问题:
- 学习目标不明确,导致定位任务性能下降。独立的CNN不能同时进行定位和分类任务,因为定位需要目标的全局特征,而分类只需要目标的局部特征
- CAM(Class Activation Mapping)存储一个三维特征图用于计算类别的heatmap,再用阈值过滤,但是一般阈值十分难确定
受selective search和Faster-RCNN的类不可知过程的启发,将WSOL分成两个子任务,类不可知的目标定位任务和目标分类任务,提出PSOL,直接通过伪GT bbox进行模型更新,不需要直接生成bbox,能够显著解决前面提到的问题
The PSOL Method

-
Bounding Box Generation
PSOL与WSOL的区别在于给无标签的训练图片产生伪bbox,Detection是最好的选择,能够直接提供bbox和类别。但是最大的检测训练集才80类,不能提供通用的目标检测,而且目前的detector大都需要大量的计算资源和输入尺寸,导致不能在大规模数据集上使用。除了detection模型,可以尝试定位方法来直接产生训练图上的bbox
- WSOL methods
首先通过预训练网络 F F F得到输入图片 I I I的最后卷积的特征图 G ∈ R h × w × d = F ( I ) G \in \mathbb{R}^{h\times w\times d}=F(I) G∈Rh×w×d=F(I),然后通过全局池化和最终的全连接层得到最后的标签 L p r e d L_{pred} Lpred。根据 L p r e d L_{pred} Lpred或 L g t L_{gt} Lgt,得到特定类别在最终全连接中的权重 W ∈ R d W\in \mathbb{R}^d W∈Rd,对 G G G中的空间位置进行channel-wise的加权并求和得到特定类别的heatmap H , H i , j = ∑ k = 1 d G i , j , k W k H, H_{i,j}={\sum}_{k=1}^d G_{i,j,k}W_k H,Hi,j=∑k=1dGi,j,kWk,将 H H H上采样到原来的大小,使用阈值过滤在产生最终的bbox
- DDT recap
协同监督方法在定位任务中有较好的表现,DDT是其中表现好且计算量最少的。对于 n n n张相同标签图的集合 S S S,使用预训练模型 F F F得到最终的特征图 G ∈ R h × w × d = R h w × d = F ( I ) G\in \mathbb{R}^{h\times w\times d}=\mathbb{R}^{hw\times d}=F(I) G∈Rh×w×d=Rhw×d=F(I),将这些特征图集合到一起得到大特征集 G a l l ∈ R n × h w × d G_{all}\in \mathbb{R}^{n\times hw\times d} Gall∈Rn×hw×d。在深度上使用主成分分析(PCA),得到特征值最大的特征向量 P P P,然后对 G G G进行channel-wise的加权并求和得到最终的heatmap H , H i , j = ∑ k = 1 d G i , j , k P k H, H_{i,j}={\sum}_{k=1}^d G_{i,j,k}P_k H,Hi,j=∑k=1dGi,j,kPk,将 H H H上采样到原来的大小,然后进行零过滤以及最大连通区域分析得到bbox
-
Localization Methods
在生成bbox后,使用bbox回归进行精调,这里使用单类别回归(single-class regression, SCR)。假设bbox为 ( x , y , w , h ) (x,y,w,h) (x,y,w,h), ( x , y ) (x,y) (x,y)为左上角坐标, ( w , h ) (w,h) (w,h)为宽高,首先将值进行转换 x ∗ = x w i x^*=\frac{x}{w_i} x∗=wix, y ∗ = y h i y^*=\frac{y}{h_i} y∗=hiy, w ∗ = w w i w^*=\frac{w}{w_i} w∗=wiw, h ∗ = h h i h^*=\frac{h}{h_i} h∗=hih,其中 w i w_i wi和 h i h_i hi为输入图片的宽和高。使用两个全连接层以及对应ReLU的子网来回归,最终的输出进行sigmoid激活,训练使用最小平方差
Experiments
Experimental Setups
- Datasets,使用ImageNet-1k和CUB-200,测试数据的bbox是准确标注的,而训练集上的bbox则通过前面提到的方法进行生成
- Metrics,验证3个指标:知道GT类别的定位准确率(GT-known Loc),当预测与GT的 I O U > 50 % IOU > 50\% IOU>50%时正确;Top-1定位准确率(Top-1 Loc),Top-1的分类正确且GT-known Loc正确;Top-5定位准确率(Top-5 Loc),Top-5结果中存在分类正确且GT-known Loc正确
- Base Models,有VGG16/Inception V3/ResNet50/DenseNet161,没有增大图片输入,一些WSOL方法要用到类别信息的权重(单层全连接)来生成heatmap,而PSOL不用。为了公平起见,增加VGG-GAP,将所有全连接层换成单层全连接,而对于回归模型,仍然使用双层全连接层加对应的ReLU
- Joint and Separate Optimization,对于联合优化模型(-Joint),在原来的基础上加入bbox回归分枝,然后同时训练模型的分类和定位。对于独立优化模型(-Sep),单独训练两个模型
Results and Analyses
Ablation Studies on How to Generate Pseudo Bounding Boxes

在验证集上对比了不同算法生成伪GT框的准确率,DDT-VGG16性能最优
Comparison with State-of-the-art Methods
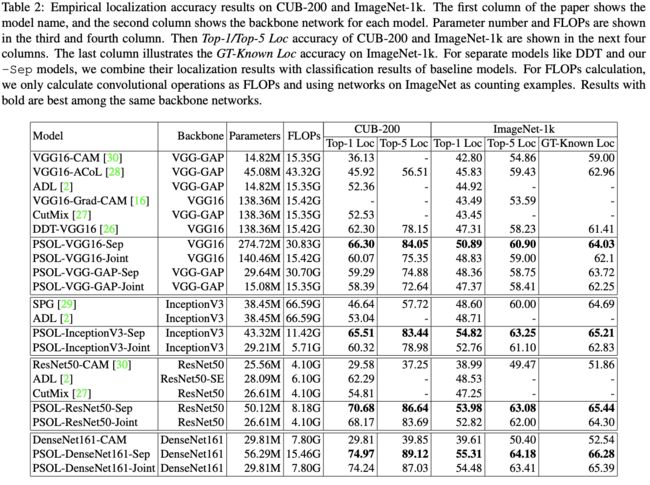
与SOTA对比并可视化结果后发现:
- DDT本身就已经比WSOL方法要好,说明类不可知是有用的,WSOL应该分为两个独立的模型
- 所有PSOL方法分开训练都比联合训练要好,说明定位和分类学习到的内容不一样
- POSL在CUB-200上都具有较大的优势,由于类别相似度较大,类别标签不一定能帮助定位,反而协同定位的DDT更占优
- CNN有能力去处理有噪声的数据并且得到更高的准确率,PSOL模型的GT-Known Loc基本都比DDT-VGG16高
- WSOL里的一些约束没有带到PSOL中,例如只允许单层全连接层以及更大的输出特征图,去掉常见的三层全连接层会影响准确率,VGG-Full比VGG-GAP要好。还有WSOL方法在复杂的网络上效果不好,如DenseNet,主要由于DenseNet使用多层进行分类,不仅仅是最后一层,最后一层的语义不如VGG等明确,而PSOL-DenseNet则避免了这个问题,达到最高准确率
Transfer Ability on Localization
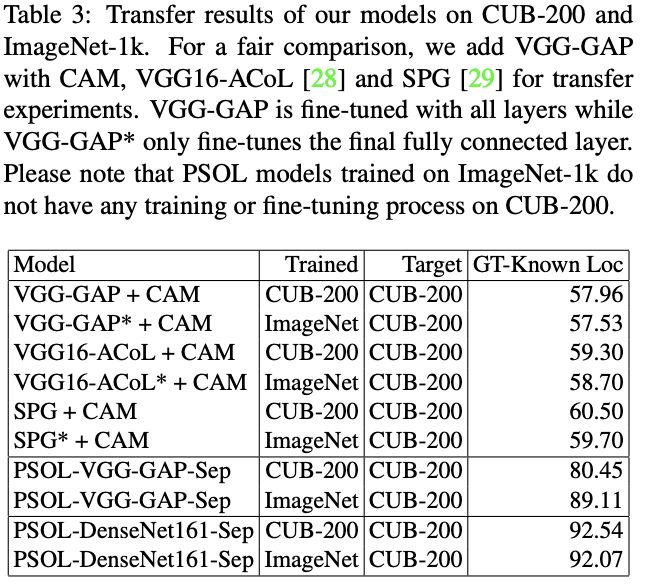
PSOL不需要任何监督信息就很好的从ImageNet迁移到CUB-200,甚至比fine-tune的WSOL方法都好,证明目标定位与类别关联是没必要的
Combining with State-of-the-art Classification

将分类部分的网络改为SOTA分类网络结合进行实验,PSOL性能依然比WSOL要好
Comparison with fully supervised methods

对比监督方法,这里论文的描述不是很清楚,表中有监督的分类网络应该都是使用WSOL方法+定位LOSS。从结果来看,从ILSVRC直接迁移过来的Faster-RCNN-ensemble精度最高,region proposal网络不需要fine-tuning就具有更好的处理不同类别的通用能力,说明定位与分类是分开的
CONCLUSION
论文提出伪监督目标定位方法(PSOL)来解决目前弱监督目标定位方法存在的问题,该方法将定位与分类分开成两个独立的网络,然后在训练集上使用Deep descriptor transformation(DDT)生成伪GT进行训练,整体效果达到SOTA,论文化繁为简,值得学习
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】
