MySQL分库分表必知必会
1. 为什么要分库分表(设计高并发系统的时候,数据库层面该如何设计)?
一个高并发系统的瓶颈主要在数据库层, 为了缓解数据库的压力, 我们可以这样做:
- 使用Redis缓存减少数据库的读并发.
- 使用Kafka消息队列来进行写并发削峰.
- 数据库SQL优化, 必须走索引.
- 水平分表.
- 读写分离.
- 垂直分库.
- 水平分库.
2. 分库分表的类型
- 垂直分表
垂直分表一般在表设计时就应该做好. 根据业务将一个表拆分为多个表, 表的结构不同, 如订单表, 订单支付表, 订单项表等. - 水平分表
当表的数据量太大时, 可以进行水平拆分, 将一个表拆分为多个表. 表的结构相同, 只是将数据拆分. - 垂直分库
当数据库的并发压力太大时, 可以根据业务将一个数据库拆分为多个数据库, 部署在不同的数据库服务器上. 如订单库, 用户库, 营销活动库等等 - 水平分库
当垂直分库后数据库的并发压力太大时, 可以进行水平拆分, 将一个库拆分为多个库, 数据库中的表结构和表数量都相同, 只是将数据拆分.
3. 分库分表后带来的问题
全局ID生成
这是水平分库分表后的问题.
(1) UUID
全球唯一, 但太长了, 不适合做全局ID.
(2) 序列表生成全局ID
当写并发不高时, 可以使用此方法. 从t_sequence表中获取ID, 每次获取一批ID, 然后在内存中自增返回.
CREATE TABLE `t_sequence` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT '自增id',
`table_name` varchar(64) NOT NULL COMMENT '表格名称',
`max_id` bigint(20) NOT NULL COMMENT '当前的最大id',
`step` smallint(6) NOT NULL COMMENT '每次取的id跨度',
`modify_time` datetime DEFAULT NULL COMMENT '修改时间',
PRIMARY KEY (`id`),
UNIQUE KEY `ind_tbl_name` (`table_name`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 ROW_FORMAT=COMPACT;
/**
* 从t_sequence表中获取ID, 每次获取一批ID, 然后在内存中自增返回.
*/
public Long getNextId() {
sequenceLock.lock();
try {
if (nextId < maxId) {
return nextId++;
}
//更新nextId和maxId, 循环多次(伪代码)
select id,max_id,step from t_sequence where id=? and table_name=?
update t_sequence set max_id = max_id +step,modify_time=now() where id=? and table_name=? and max_id=?
nextId = max_id;
maxId = nextId + step;
return nextId++;
} finally {
sequenceLock.unlock();
}
}
(3) SnowFlake算法
Snowflake 是 Twitter 开源的分布式 ID 生成算法, 其结果为 long(64bit) 的数值.
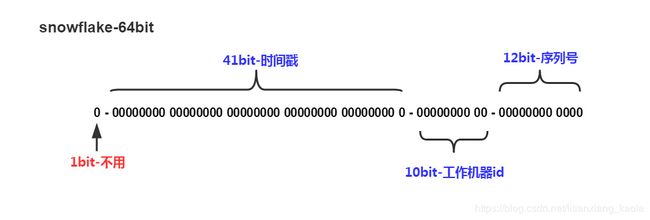
分片策略
这是水平分库分表后的问题. 这里MySQL的分片策略和Redis集群的分片策略差不多, 可以相互对照下.
(1) ID取模分片
最简单且使用最广泛的分片策略, 缺点是扩容后需要迁移数据.
(2) 一致性哈希算法
是ID取模分片的优化方案, 但扩容后仍然有部分数据需要迁移.
(3) Range分片
根据时间范围分片, 比如每月一张表, 每天一张表等, 在一些统计业务中会用到.
分布式事务
这是垂直分库后的问题. 分布式事务解决方案
跨节点Join和聚合
分库分表后的数据入Elasticsearch, 然后在Elasticsearch进行搜索聚合.
4. 一个单库单表的系统在分库分表后, 如何动态切换(不停机切换)?
- 数据双写
数据同时写入旧库和新库 - 数据迁移
写个临时程序进行数据迁移, 迁移的过程中要比较update_time字段. - 校验旧库和新库数据是否一致
写个临时程序遍历旧库和新库的数据是否一致, 修改不一致的数据.(update_time比旧库大的数据不处理) - 删除旧库的写入代码
然数据迁移完毕后, 就不再需要双写了.
5. 如何设计可以动态扩容缩容的分库分表方案?
一开始一个数据库服务器中就设计32个库, 每个库中32张表, 当数据库服务器并发压力太大时, 就迁移一半的数据库到另一个数据库服务器上, 最终可以达到32个数据库服务器, 每个数据库服务器上一个数据库. 这是种比较奢侈的设计方案, 也只有大厂敢这么设计.
6. 如何实现MySQL的读写分离?MySQL主从复制原理的是啥?如何解决MySQL主从同步的延时问题?
(1) 如何实现MySQL的读写分离?
当单库的并发太高时, 我们就需要做读写分离, 写请求走主库, 读请求走从库, 来降低数据库服务器(MySQL)的压力. 使用Sharding-JDBC中间件来实现.
(2) MySQL主从复制原理的是啥?
MySQL主从复制原理
(3) 如何解决MySQL主从同步的延时问题?
- 并行复制
MySQL5.7开启并行复制后, 主从同步延时问题基本就解决了. - 分库
主从同步延时的根本原因还是主库写并发太高, 我们可以通过分库来降低单库的写并发. - 优化代码
较短时间的主从同步延时是可以接受的, 我们不要写那种insert+select+update式的语句, 即插入一条数据后立即查询, 然后再修改.
7. 用过哪些分库分表中间件?不同的分库分表中间件都有什么优点和缺点?
- Sharding-JDBC
Client层的中间件, 不需要额外部署, 运维成本点, 但由于与代码强耦合, 版本升级比较麻烦, 适合中小型公司. - MyCat
Proxy层的中间件, 需要额外部署, 运维成本高, 但对各个系统来说是透明的, 版本升级简单, 适合大公司.
Sharding-JDBC和MyCat这两个中间件随便用哪个都可以, 都比较方便.