OpenKiwi 使用的 QE 系统
QUETCH
QUality Estimation from scraTCH
http://www.statmt.org/wmt15/pdf/WMT37.pdf
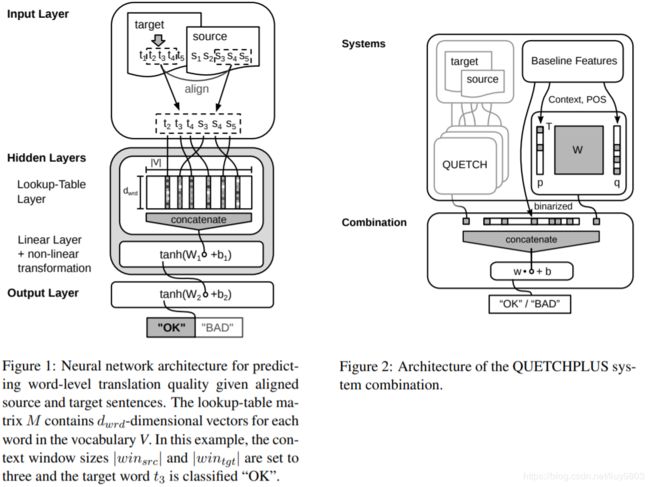
模型输入:对于 MT 中的每个单词,围绕该单词固定大小的窗口,与源句中对齐单词的窗口相连接,得到该目标单词的双语上下文向量。
模型结构:单隐层 MLP,lookup 得到词向量(训练中更新),激活函数为 tanh。
模型输出:softmax 计算每个单词的 OK/BAD 的概率,该模型单独训练以预测源句标签、gap 标签和目标标签。
NuQE
Neural QE
http://www.statmt.org/wmt17/pdf/WMT64.pdf
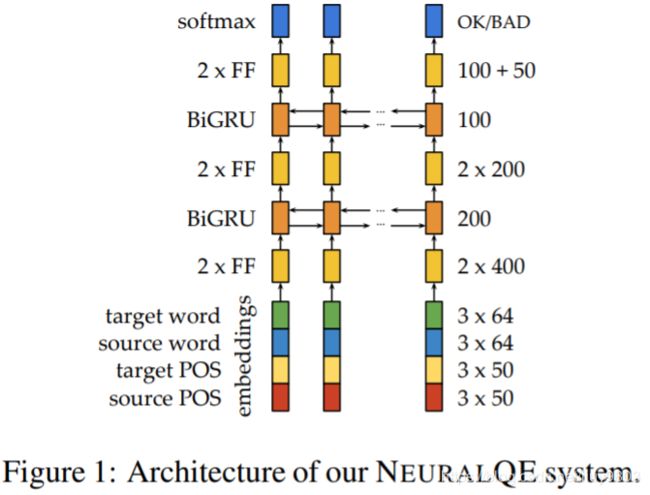
模型输入:源句 s 和目标句 t 的词级对齐 A,TurboTagger 获得的 POS 标签,每个目标与源对齐的词向量、上下文以及 POS 标签都被进行连接。
模型结构:
(1)两个 FF + ReLU 层,大小为400;
(2)一个 BiGRU + layer norm层,大小为200;
(3)两个 FF + ReLU 层,大小为200;
(4)一个 BiGRU + layer norm层,大小为100;
(5)两个 FF + ReLU 层,大小分别为100和50。
模型输出:softmax 计算 OK/BAD 标签。
Predictor-Estimator
http://www.statmt.org/wmt17/pdf/WMT63.pdf
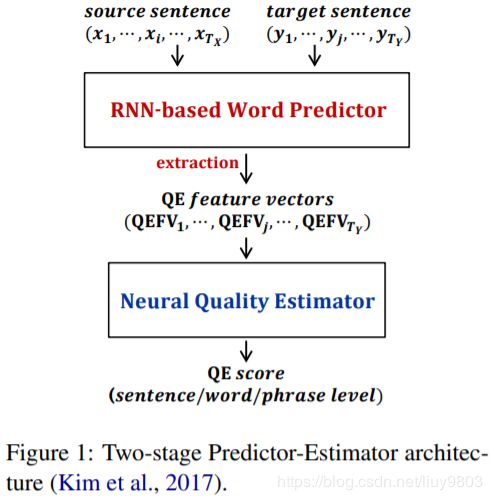
模型结构:
• Predictor,双向 LSTM 编码源句,目标句每个词上下文连接,并作为 softmax 层之前的 attention 中的 query,预测目标句每个词及上下文;
• Estimator,使用 predictor 特征多任务训练,计算每个词的 OK/BAD 标签和句子级 HTER 分数。
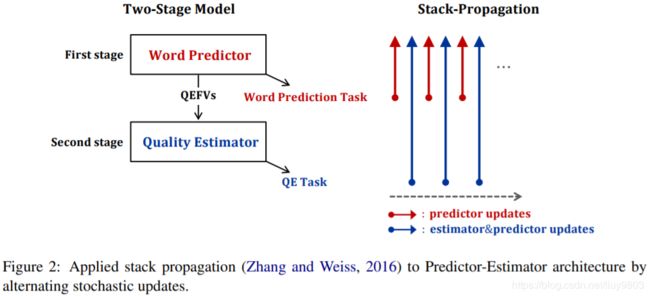
带有 stack propagation 的多任务学习,层之间可以相互学习有利的关系。
Stacked Ensemble
https://www.aclweb.org/anthology/Q17-1015.pdf
Stack 集成特征,如语法信息及 POS 标签,对齐的单词及上下文,语言模型提供的句法特性和共享任务提供的特征,该系统仅用于为 MT 单词生成单词级标签。模型结构集成及消融实验。

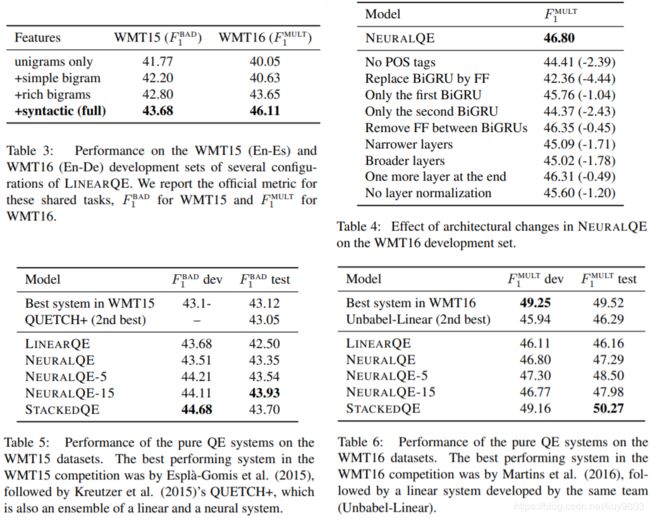
FullStackedQE,将 NeuralQE 和 APE QE 堆叠到 LinearQE 中,是 pure QE 和 APE-based QE 系统的混合。
APE 自动后编辑系统经过人工后编辑数据训练出来,它的输出可以作为伪后编辑数据,可以与创建原始标签相同的方式生成单词级质量标签和句子级分数,这样就可以得到伪QE训练数据。 使用APE-QE的两个变体:1. PSEUDO-APE,它训练常规机器翻译模型并将其输出用作生成伪参考数据;2. 带有额外解码约束的 APE-BERT,以奖励或惩罚源或翻译文本中不存在的单词。
Word Quality Estimation for NMT
https://github.com/Unbabel/word-level-qe-corpus-builder
WMT word-level QE task,同时考虑流利性和充分性,需要检测错误的单词、插入错误、源句与目标句相关的错误单词,标签 tags 是使用 fast_align, tercom 确定的,使用对齐确定可能与目标句错误相关的源词,并且在 tercom 对齐后,认为一个或多个连续插入是单个 gap(插入)错误。