X86/X64处理器体系结构及寻址模式
由8086/8088、x86、Pentium发展到core系列短短40多年间,处理器的时钟频率几乎已接近极限,尽管如此,自从86年Intel推出386至今除了增加一些有关流媒体的指令如mmx/sse之外,其他新增的大多数指令都可以从最初的指令集中组合实现同样的功能,整个编程模型维持了约有20多年。
1. 处理器体系结构
1.1. 处理器简要结构
我们都知道CPU的根本任务就是执行指令,对计算机来说最终都是一串由“0”和“1”组成的序列。CPU从逻辑上可以划分成3个模块,分别是控制单元、运算单元和存储单元,这三部分由CPU内部总线连接起来。如下所示:
1. 控制单元:控制单元是整个CPU的指挥控制中心,由指令寄存器IR(Instruction Register)、指令译码器ID(Instruction Decoder)和操作控制器OC(Operation Controller)等,对协调整个电脑有序工作极为重要。它根据用户预先编好的程序,依次从存储器中取出各条指令,放在指令寄存器IR中,通过指令译码(分析)确定应该进行什么操作,然后通过操作控制器OC,按确定的时序,向相应的部件发出微操作控制信号。操作控制器OC中主要包括节拍脉冲发生器、控制矩阵、时钟脉冲发生器、复位电路和启停电路等控制逻辑。
2. 运算单元:是运算器的核心。可以执行算术运算(包括加减乘数等基本运算及其附加运算)和逻辑运算(包括移位、逻辑测试或两个值比较)。相对控制单元而言,运算器接受控制单元的命令而进行动作,即运算单元所进行的全部操作都是由控制单元发出的控制信号来指挥的,所以它是执行部件。
3. 存储单元:包括CPU片内缓存和寄存器组,是CPU中暂时存放数据的地方,里面保存着那些等待处理的数据,或已经处理过的数据,CPU访问寄存器所用的时间要比访问内存的时间短。采用寄存器,可以减少CPU访问内存的次数,从而提高了CPU的工作速度。但因为受到芯片面积和集成度所限,寄存器组的容量不可能很大。寄存器组可分为专用寄存器和通用寄存器。专用寄存器的作用是固定的,分别寄存相应的数据。而通用寄存器用途广泛并可由程序员规定其用途,通用寄存器的数目因微处理器而异。这个是我们以后要介绍这个重点,这里先提一下。
我们将上图细化一下,可以得出CPU的工作原理概括如下:
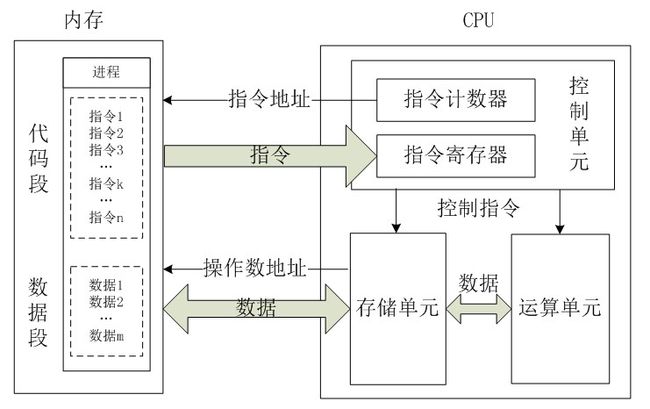
总的来说,CPU从内存中一条一条地取出指令和相应的数据,按指令操作码的规定,对数据进行运算处理,直到程序执行完毕为止。
1.2. 寄存器简要结构
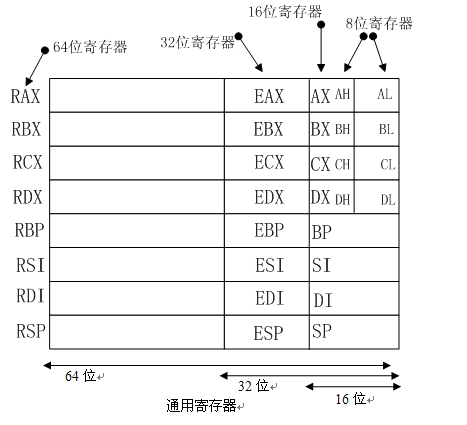

以上所列出的一些通用寄存器(注:其中RSP为专用寄存器,之所以把它放在通用寄存器组中只是为了方便记忆整个模型),除了数据位宽度不同之外,并无多大差别:
- RAX(累加器):RAX如果是8/16/32位寻址,则只改变该寄存器的一部分。累加器用于乘法、除法及一些调整指令,同时也可以保存存储单元的偏移地址。
- RBX(基址):用于保存存储单元的偏移地址,同时也能寻址存储器数据,作为偏移地址访问数据时默认使用数据段基址DS作为段前缀。
- RCX(计数):可保存访问存储单元的偏移地址,或在串指令(REP/REPE/REPNE)以及移位、循环和LOOP/LOOPD指令中用作计数器。
- RDX(数据):可使用RDX/EDX/DX/DH/DL寻址,同时作为通用寄存器也用于保存乘法形成的部分结果或者除法之前的部分被除数,也可用于寻址存储单元。
- RBP(基指针):可用RBP/EBP/BP寻址,同时作为偏移地址访问存储单元时默认使用堆栈段基址SS作为段前缀。
- RDI(目的变址):可用RDI/EDI/DI寻址,常用于在串指令中寻址目的数据串。
- RSI(源变址):如RDI一样,RSI也可作为通用寄存器使用,通常为串指令寻址源数据串。
段寄存器CS、DS、ES、SS、FS、GS以及RSP为专用寄存器,以下是这些寄存器的概要描述:
- RSP(堆栈指针):RSP寻址称为堆栈的存储区,通过该指针存取堆栈数据。用作16位寄存器时使用SP,如果是32位则为ESP。
- CS(代码段):代码段寄存器存放程序所使用的代码在存储器中的基地址。 • DS(数据段):存放数据段的基地址。
- ES(附加段):该段寄存器通常在串指令(LODS/STOS/MOVS/INS/OUTS)中使用,主要用于在存储器中将数据进行成块转移。
- SS(堆栈段):为堆栈定义一个存储区域。主要用来存放过程调用所需参数、本地局部变量以及处理器状态等。
- FS与GS:这两个段寄存器是386~Core2中新增的段寄存器,以允许程序访问附加的存储器段。可以将其视为“通用的段寄存器”,通过将段的基地址存入这两个寄存器中可以实现自定义的寻址操作,从而增加了编程的灵活性。
每一个寄存器都有一个”可见”部分和一个”隐藏”部分。(这个隐藏部分有时也指一个”描述符缓存”(descriptor cache)或者”阴影寄存器”(shadow register))。当一个段选择器被加载到段寄存器的可见部分,处理器也会自动把基址,段界限,和段描述符中的访问控制信息加载到段寄存器的隐藏部分。把信息缓存在段寄存器(可见和隐藏部分)允许处理器不经过额外的总线循环(bus cycles)去段描述符总读取基址和界限来转换地址。当描述符表发生了更改,软件有义务重新加载段寄存器。如果不这样做,段寄存器中使用的老段描述符还是会继续使用。
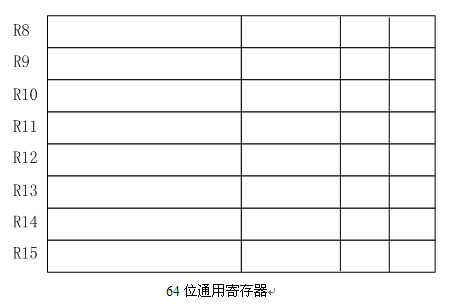
如上图所示,在Pentium4及更高型号处理器中增加了R8~R15这8个64位通用寄存器,这些新增的64位寄存器仍支持按字节、字、双字或四字方式寻址,而不同之处在于只有最右边的数据位可以用来作为单独的一个字节/字等。注意在使用这些新增寄存器的其中一个部分时需要在寄存器末尾添加控制字,例如:
- mov R11D, R8D ;其中字母D用于表示双字访问
- ;也可以将D改为B或者W,B表示字节访问,W表示字访问
- ;如果不加任何控制字则使用整个寄存器

RIP寻址代码段中当前执行指令的下一条指令,当处理器工作在实模式下时使用16位的IP寄存器,当工作于保护模式时则使用32位的EIP。指令指针可由转移指令或调用指令修改。需要注意的是,在64位模式中由于处理器包含40位地址总线,所以总共可以寻址240=1TB的内存。
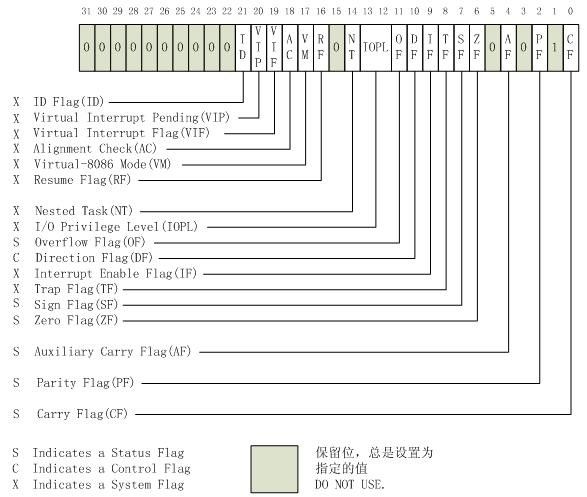
EFLAGS(program status and control) register主要用于提供程序的状态及进行相应的控制,在64-bit模式下,EFLGAS寄存器被扩展为64位的RFLGAS寄存器,高32位被保留,而低32位则与EFLAGS寄存器相同。
32位的EFLAGS寄存器包含一组状态标志、系统标志以及一个控制标志。在x86处理器初始化之后,EFLAGS寄存器的状态值为0000 0002H。第1、3、5、15以及22到31位均被保留,这个寄存器中的有些标志通过使用特殊的通用指令可以直接被修改,但并没有指令能够检查或者修改整个寄存器。通过使用LAHF/SAHF/PUSHF/POPF/POPFD等指令,可以将EFLAGS寄存器的标志位成组移到程序栈或EAX寄存器,或者从这些设施中将操作后的结果保存到EFLAGS寄存器中。在EFLAGS寄存器的内容被传送到栈或是EAX寄存器后,可以通过位操作指令(BT, BTS, BTR, BTC)检查或修改这些标志位。当调用中断或异常处理程序时,处理器将在程序栈上自动保存EFLAGS的状态值。若在中断或异常处理时发生任务切换,那么EFLAGS寄存器的状态将被保存在TSS中 【the state of the EFLAGS register is saved in the TSS for the task being suspended.】 ,注意是将要被挂起的本次任务的状态。
EFLAGS寄存器的状态标志(0、2、4、6、7以及11位)指示算术指令(如ADD, SUB, MUL以及DIV指令)的结果。位于EFLAGS寄存器的第10位DF标志(DF flag) 控制串指令(MOVS, CMPS, SCAS, LODS以及STOS)。设置DF标志使得串指令自动递减(从高地址向低地址方向处理字符串),清除该标志则使得串指令自动递增。EFLAGS寄存器中的系统标志以及IOPL域(System Flags and IOPL Field) 用于控制操作系统或是执行操作,它们不允许被应用程序所修改。
2. 处理器工作及寻址模式
对于一根实际的、实实在在的、物理的、可看得见、摸得着的内存条而言,处理器把它当做8位一个字节的序列来管理和存取,每一个内存字节都有一个对应的地址,我们叫它物理地址,用地址可以表示的长度叫做寻址空间。而CPU是如何去访问内存单元里的数据的方式就叫做寻址。
2.1. 实模式
8086得CPU在内存寻址方面第一次引入了一个非常重要的概念—-段。在8086之前都是4位机和8位机的天下,那是并没有段的概念。当程序要访问内存时都是要给出内存的实际物理地址,这样在程序源代码中就会出现很多硬编码的物理地址。段寄存器的产生源于Intel 8086 CPU体系结构中数据总线与地址总线的宽度不一致。也就是为了实现16位8086 CPU实现20位地址总线位宽。为了支持分段机制,Intel在8086的CPU里新增了4个寄存器,分别是代码段CS,数据段DS,堆栈段SS和其他ES。这样一来,一个物理地址就由两个部分组成,分别是“段地址”:“段内偏移量”。在实模式中,通常寻址时都是通过段寄存器+通用寄存器,即基址+变址的方式进行寻址。例如,ES=0x1000,DI=0xFFFF,那么这个数据ES:DI在内存里的绝对物理地址就是:
AD(Absolute Address)=(ES)*(0x10)+(DI)=0x1FFFF
就是讲段基地址左移4位然后加上段内偏移量就得到了物理内存里的绝对地址,经过这么一个变换,就可以得到一个20位的地址,8086就可以对20位的1M内存空间进行寻址了。如下:

很明显,这种方式可以寻址的最高地址为0xFFFF:0xFFFF,其地址空间为0x00000~0x10FFEF,因为8086的地址总线是20位,最大只能访问到1MB的物理地址空间,即物理地址空间是0x00000~0xFFFFF。当程序访问0x100000~0x10FFEF这一段地址时,因为其逻辑上是正常的,CPU并不会认为其访问越界而产生异常,但这段地址确实没有实际的物理地址与其对应,怎么办?此时CPU采取的策略是,对于这部分超出1M地址空间的部分,自动将其从物理0地址处开始映射。也就是说,系统计算实际物理地址时是按照对1M求模运算的方式进行的,在有些技术文献里你会看到这种技术被称之为wrap-around。还是通过一幅图来描述一下吧:
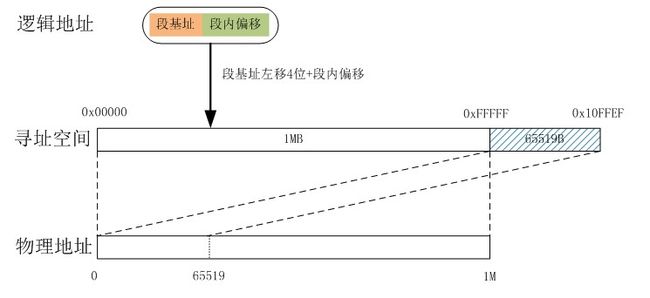
根据前面的讲解我们可以发现段基址有个特征,其低4位全为0,也就是说每个段的起始地址一定是16的整数倍,这是分段的一个基本原则。这样每个段的最小长度是16字节,而最大长度只能是64KB。这里我们可以计算一下,1MB的物理地址空间能划分成多少个段。
如果每个段的长度为16字节,这样1MB物理地址空间最多可以划分成64K个段;
如果每个段的长度为64KB,那么1MB的物理地址空间最多能划分成16个段。
8086这种分段基址虽然实现了寻址空间的提升,但是也带来一些问题:
- 同一个物理地址可以有多种表示方法。例如0x01C0:0x0000和0x0000:0x1C00所表示的物理地址都是0x01C00。
- 地址空间缺乏保护机制。对于每一个由段寄存器的内容确定的“基地址”,一个进程总是能够访问从此开始64KB的连续地址空间,而无法加以限制。另一方面,可以用来改变段寄存器内容的指令也不是什么“特权指令”,也就是说,通过改变段寄存器的内容,一个进程可以随心所欲地访问内存中的任何一个单元,而丝毫不受限制。不能对一个进程的内存访问加以限制,也就谈不上对其他进程以及系统本身的保护。与此相应,一个CPU如果缺乏对内存访问的限制,或者说保护,就谈不上什么内存管理,也就谈不上是现代意义上的中央处理器。
8086和后来的80186,这种只能访问1MB地址空间的工作模式,我们将其称之为“实模式”。我的理解就是“实际地址模式”,因为通过段基址和段偏移算出来的地址,经过模1MB之后得出来的地址都是实际内存的物理地址。
虽然现在CPU已经发展到了64位的酷睿6代,但是仍然保持着实模式这个工作模式。CPU的实模式是为了与8086处理器兼容而设置的。在实模式下,CPU处理器就相当于一个快速的8086处理器。CPU处理器被复位或加电的时候以实模式启动。这时候处理器中的各寄存器以实模式的初始化值工作。CPU处理器在实模式下的存储器寻址方式和8086基本一致,由段寄存器的内容乘以16作为基地址,加上段内的偏移地址形成最终的物理地址,这时候它的32位地址线只使用了低20位,即可访问1MB的物理地址空间。在实模式下,CPU处理器不能对内存进行分页机制的管理,所以指令寻址的地址就是内存中实际的物理地址。在实模式下,所有的段都是可以读、写和执行的。实模式下CPU不支持优先级,所有的指令相当于工作在特权级(即优先级0),所以它可以执行所有特权指令,包括读写控制寄存器CR0等。这实际上使得在实模式下不太可能设计一个有保护能力的操作系统。实模式下不支持硬件上的多任务切换。实模式下的中断处理方式和8086处理器相同,也用中断向量表来定位中断服务程序地址。中断向量表的结构也和8086处理器一样,每4个字节组成一个中断向量,其中包括两个字节的段地址和两个字节的偏移地址。应用程序可以任意修改中断向量表的内容,使得计算机系统容易受到病毒、木马等的攻击,整个计算机系统的安全性无法得到保证。
2.2. 保护模式(IA-32模式)
由于8086的上述问题,1982年,Intel在80286的CPU里,首次引入的地址保护的概念。也就是说80286的CPU能够对内存及一些其他外围设备做硬件级的保护设置(实质上就是屏蔽一些地址的访问)。自从最初的x86微处理器规格以后,它对程序开发完全向下兼容,80286芯片被制作成启动时继承了以前版本芯片的特性,工作在实模式下,在这种模式下实际上是关闭了新的保护功能特性,因此能使以往的软件继续工作在新的芯片下。后续的x86处理器都是在计算机加电启动时都是工作在实模式下。
也就是说,在保护模式下,程序不能再随意的访问物理内存了,有些内存地址CPU做了明确的保护限制。在这些要求下,286时代的“根据段寄存器确定段基址”方法已经行不通了,我们需要的不仅仅是基址,还需要访问权限等额外的信息,而且我们不想把具体的基址暴露给用户。
2.2.1. 段描述符
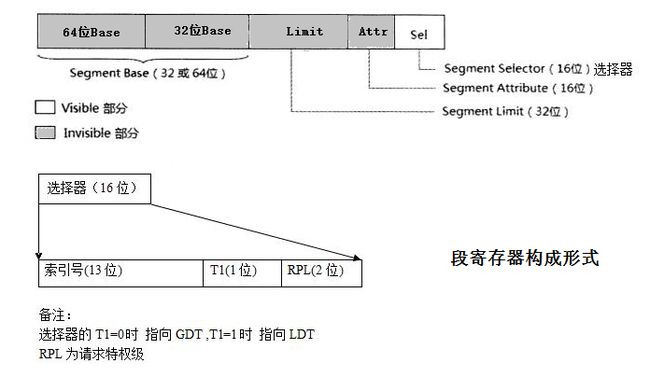
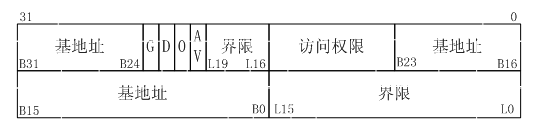
为了解决这些问题,intel引入一个中间结构体,段描述符。并增设了两个寄存器:GDTR (global descriptor talbe register)指向全局段描述符数组(表);LDTR (localdescriptor table register)执行局部段描述符数组(表)。而6个段寄存器,CS/DS/SS/ES包括后来的FS/GS,其内容不在用作基址,而是用作索引去段描述符数组中查找对应的段描述符。段描述符占8个字节,其定义以及其中各个标志位的定义如下:

段限制字段(Segment limit field) 确定段的大小。处理器将两个段限制字段放在一起形成一个20-bit的值。根据G(粒度(granularity))标记位设置的不同,处理器有两种方式解析段限制。
- 如果G标记位被清除了,段大小范围从1 byte到1 MByte,步长为一个字节。
- 如果G字段设置了,段大小范围从4 KBytes到4GBytes,步长为4-KByte。
处理器有两种方式使用段限制,取决于段是向上扩展段(expand-up
segment)还是向下扩展段(expand-down
segment)。对于向上扩展段,逻辑地址的偏移量范围从0到段大小限制。大于段限制的偏移量会产生一个通用保护异常(GP,对于除了SS之外的段)或者栈错误异常(stack-fault
exception)(SS,对于SS段)。对于向下扩展段,段限制有一个反向函数;偏移量范围从段限制加上1到加上FFFFFFFFH或者FFFFH,取决于B标记位的设置。小于或者等于段限制的偏移量会产生一个通用保护异常或者栈错误异常。在向下扩展段中申请新的内存的时候,会减少段限制字段的值,并且新申请的空间在段地址空间的底部而不是顶部。IA-32
架构栈总是向下增长的,使这个机制对于扩展段来说非常便利。
基址字段(Base address fields) 在4-GByte线性地址空间中定义了段基址byte0的位置。处理器将三个基址字段加在一起形成一个32-bit的值。段基址需要在16-byte的边界对齐。对染16-byte对齐并不是必须的,但是在16-byte边界对齐的代码和数据的程序有最佳表现。
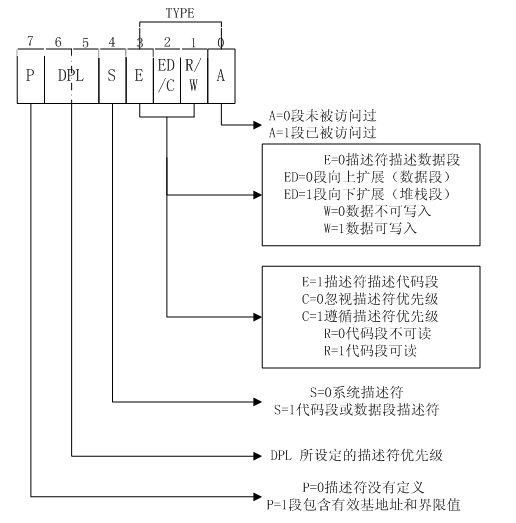
类型字段(Type field) 指定了段和门的类型并且指定了段的访问方式以及段数据增长方向。对这个字段的解释取决于描述符类型是应用(代码和数据)描述符或是系统描述符。类型字段的编码在代码,数据,和系统描述符中是不同的。
S(描述符类型(descriptor type))标识 决定了这个段描述符是一个系统段(S标记位清0)或是一个代码或者数据段(S标记位设置了)。
DPL(描述符优先级(descriptor privilege level))字段 决定了段的特权级别。特权级别范围从0到3,其中0是最大特权级别。DPL用来控制对段的访问的。
P(segment-present) flag 决定了是否这个段现在是在内存(set)还是不在(clear)。如果标记位为clear,如果有段选择器指向段描述符加载到段寄存器的时候,处理器将会产生一个段不在异常(segment-not-present exception)(NP)。内存管理软件使用这个标记位来控制当前时间哪些段真正的加载到物理内存。它在分页虚拟内存之外提供了一个额外的控制。
下图展示了当segment-present是clear状态时,段描述符的格式。当这个标记位是clear,操作系统或者执行指令可以直接使用标记为”可用(Avilable)”的位置来存储自己的数据,比如缺失段下落的信息。
D/B(操作的默认大小/栈指针大小和/或上界)标记位 在段描述符是一个可执行代码段,一个向下扩展段,或是栈段不同情况下,表现出不同的方法。(在32-bit代码和数据段中,应该总是被设置成1,而在16-bit代码和数据段中总是0);
- 可执行代码段(Executable code segment)
此时标记位也称为D标记,它决定了段中有效地址和指针运算符的默认大小。如果标记位是set,认定是一个32-bit地址和32-bit或者8-bit的运算符;如果是clear,认定是一个16-bit的地址和16-bit或者8-bit运算符。 - 栈段(Stack segment)(通过SS寄存器指向数据段)
此时标记也称为B(big)标记,它决定了在隐式栈操作使用中栈指针的大小(比如pushes,pops,和calls)。如果标记为set,会使用一个存储在32-bit
ESP寄存器的32-bit栈指针;如果标记是clear,会是欧诺个一个存储在16-bit的SP寄存器的16-bit栈指针。如果栈段被设置成向下扩展的数据段,B标记也指定了栈段的上界。 - 向下扩展数据段(Expand-down data segment)
此时标记也称为B标记,它指定了段的上界。如果标记是set,上界就是FFFFFFFFH(4
GBytes),否则(clear)就是FFFFH(64 KBytes)。

G(粒度(grandularity))标记位 决定段限制的缩放比例。如果粒度标记是clear,段限制是以字节为单元的;如果是set,段限制是以4-KByte为单元的。(这个标记并不影响基址的粒度。)当粒度标记位是set的,检查偏移量有没有超过段限制时,不会测试一个偏移量中最不重要12个位(the twelve least significant bits of an offset are not tested when checking the offset against the segment limit. )。比如,当粒度标记是set的,段限制为0意味着有效偏移量是0到4095。
L(64-bit 代码段)标记 在IA-32e模式,段描述符第二个双字(doubleword)中的bit21决定了一个代码段是否包含了原生64-bit代码。值为1决定了代码段中的指令按照64-bit模式执行。值为0决定了代码段中的执行按照兼容模式执行。如果L-bit是set的,D-bit必须是clear的。当不在IA-32e模式或者非代码段,bit21是保留的,而且必须是0。
可用与保留位(Available and reserved bits) 段描述符的第二个双字的bit20对系统软件是可用的。
通过段描述符,我们能够得到如下信息:
- 段的基址,由B31-B24/B23-B16/B15-B0构成,一共32位,基址可以是4GB空间中任意地址;
- 段的长度,由L19-L16/L15-L0构成,一共20位。如果G位为0,表示段的长度单位为字节,则段的最大长度是1M,如果G位为1,表示段的长度单位为4kb,则段的最大长度为1M*4K=4G。假定我们把段的基地址设置为0,而将段的长度设置为4G,这样便构成了一个从0地址开始,覆盖整个4G空间的段。访存指令中给出的“逻辑地址”,就是放到地址总线上的“物理地址”,这有别于“段基址加偏移”构成的“层次式”地址(其实应该算作“层次式”地址的特例),所以intel称其为flat地址即平面地址。
- 段的类型,代码段还是数据段,可读还是可写
描述符表存储在由操作系统维护着的特殊数据结构中,并且由处理器的内存管理硬件来引用。这些特殊结构应该保存在仅由操作系统软件访问的受保护的内存区域中,以防止应用程序修改其中的地址转换信息。同时,为了避免每次访问内存时都通过段寄存器去查表、去读和解码一个段描述符,每次更改段寄存器的内容时,CPU将段寄存器指向的段描述符中的段基址、长度以及访问控制信息等加载到CPU中的“影子结构”中缓存起来。后续对该段的访问控制都通过“影子结构体”来进行。
但是如果可以修改GDTR和LDTR的内容呢?我们不就可以随便指定GDTR到我们自己伪造的段描述数组从而掌控程序吗?为了解决这个问题,intel将访问这两个寄存器的专门指令设为特权指令(LGDT/LLDT,SGDT/SLDT),这些指令只有当CPU处于系统状态(即在操作系统内核中)才能使用,用户空间无法访问寄存器的内容。这样一来,工作1-2就完成了。
2.2.1.1. 段描述符实例
以下是一个典型的代码段描述符:
- 基地址域的数据位宽度为16+8+8=32,该域指示存储器段的起始位置。
- 20位的界限域指示段的最大偏移量,通常与描述符中的特征位(G位,也称为粒度位)一起使用,当G置位时,将在20位的界限域的尾部添加FFFH形成一个32位的值。
- AV位指示段是否有效,当AV=1时指示当前存储器段有效,反之则无效,该位由操作系统使用,但Linux系统通常将其所省略。
- 偏移量的数据位宽度为32时D位被置位,为16时该位被清零。
下图详细解释了访问权限域的各个位:
下表为Linux内核对段描述符的典型设置方式:
| 段 | 基地址 | G | 界限 | S | TYPE | DPL | D | P |
|---|---|---|---|---|---|---|---|---|
| 用户代码段 | 0x0000 | 0000 | 1 | 0xF FFFF | 1 | 10(0x1010) | 3 | 1 |
| 用户数据段 | 0x0000 | 0000 | 1 | 0xF FFFF | 1 | 2(0x0010) | 3 | 1 |
| 内核代码段 | 0x0000 | 0000 | 1 | 0xF FFFF | 1 | 10(0x1010) | 0 | 1 |
| 内核数据段 | 0x0000 | 0000 | 1 | 0xF FFFF | 1 | 2(0x0010) | 0 | 1 |
上述设置分别与Linux内核中的宏__USER_CS,__USER_DS,__KERNEL_CS,__KERNEL_DS相对应。
- 4个段的基地址均被设置为0,这意味着在Linux下逻辑地址即为线性地址。
- 界限为0xF FFFF且粒度位G被置位为1,因此所有段的大小最多可达4GB。
- D位置位,所以偏移量的数据位宽度为32。
- P位被置位为1,指示所有段的基地址和界限域均是有效的。
- S位被置位,指示该描述符为代码段或数据段描述符。
- DPL域指示段的优先级,上述设置方式表示将最高优先级00分配给内核代码/数据段,而将最低优先级11分配给用户代码/数据段。
- 根据TYPE域中的E位指示当前段为代码段或是数据段。在用户/内核代码段描述符中,C=0表示忽视描述符优先级,R=1表示当前段可读,A=0表示当前段尚未被访问。相应地,在用户/内核数据段描述符中,ED=0表示该段将向上扩展,W=1表示数据可写入,A=0同样表示当前段尚未被访问过。
2.2.2. 段选择符
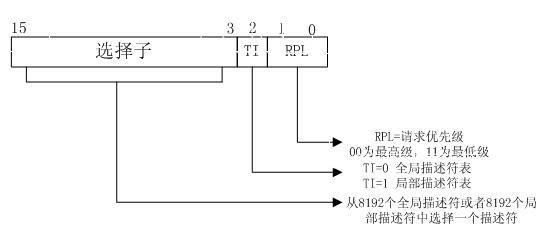
16位段寄存器中的内容,称之为段选择符,除了高13位用作段描述符数组的索引外(因此理论上段描述符数组最多可以8192个元素),低3位有其他的用途,如下所示:
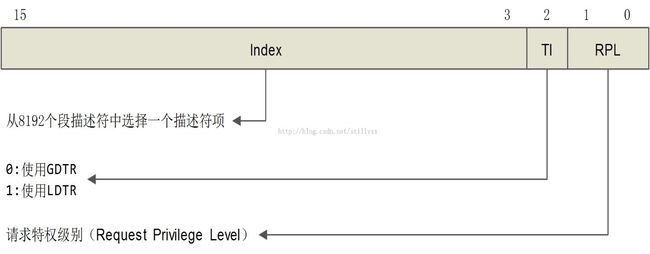
Index (Bits3 through 15) – 从GDT或者LDT中的8192个描述符中选择一个。处理器将index的值乘以8(段描述符中的字节数),然后加上GDT或者LDT的基址(各自从GDTR或者LDTR寄存器)。
由于有两个描述符数组,所以TI(Table Index)位用来确定从哪个数组中索引。
在前面的段描述符结构中,我们看到了特权级别字段(DPL),为什么还需要在这里设置一个特权字段(RPL)呢?
intel的CPU有四种特权级别,0级最高,3级最低。每条指令都有其适用级别,如前述的LGDT指令要求0级特权,通常用户的应用程序都是3级。Linux/windows中对CPU特权进行了简化,只区分用户级别和系统级别,分别对应3级和0级,这是后话。一般应用程序的当前级别由其代码段的局部段描述符(即用段寄存器CS索引LDTR指向的局部描述符项)中的dpl(descriptor privilege level)决定,当然,每个段描述符的dpl都是在0级状态下由内核设定的。而全局段描述符中的dpl有所不同,它表示所需的级别。段选择符中的rpl也表示请求级别。这样,当我们需要改变某个段寄存器(比如数据段DS)中的内容(段选择符)来访问一款新段空间时,CPU要做权限检查:
- 当前程序有权访问新的段吗?比较当前程序的当前级别与新段描述符中的dpl
- 新的段选择符有权访索引新的段吗?比较新的段选择符中的rpl与新段描述符的dpl。
当然,具体的权限检查比这要复杂,设计到段描述符中C位的取值,详情情况请参考其他资料。
至此,工作1-3都完成了,保护模式已经建立了,我们来看看当访存指令给出“逻辑地址”时,CPU如何将其转换为“物理地址”送往地址总线:
- 根据指令性质确定该使用哪个段寄存器,如跳转指令则目标地址在代码段CS,取数据的指令目标地址在数据段;
- 根据段寄存器的内容找到对应的段描述符。其实这一步不用找,前面介绍过了,段寄存器对应的段描述符已经在CPU的“影子结构”中了。
- 从段描述符中获得基址
- 将指令中的“逻辑地址”与段的长度比较,确定是否越界
- 根据指令的性质和段描述符中的访问权限确定是否越权
- 将指令中的“逻辑地址”作为位移,与基地址相加得到实际的“物理地址”
GDT的第一个实体不是处理器使用的。一个指向GDT第一个实体的段选择器(意思是说,一个index是0,且TI标记为0的段选择器)是作为一个”空段选择器”(null segment selector)。当一个带有空选择器的段寄存器(除了CS和SS之外)被加载了,处理器并不会产生异常。但是当一个带有空选择器的段寄存器被用来访问内存的时候,会产生异常。一个空选择器可以用来初始化未使用的段寄存器。当CS或者SS寄存器带有空段选择器时,会产生一个通用保护异常(general-protection exception)(GP)。
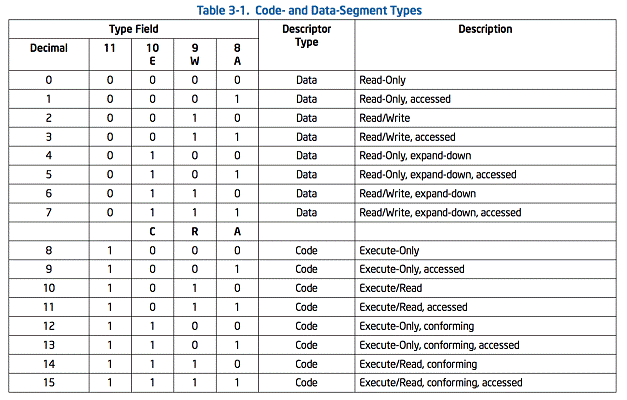
2.2.3. 代码和数据段描述符类型
当段描述符中S(段描述符(descriptor type))标记是设置的表示这个描述符是一个数据或者代码段的描述符。类型字段中的最高顺序位(描述符第二个双字的bit11)决定了这个段是一个数据段(clear)还是一个代码段(set)。
当是一个数据段,类型字段的三个低位(bits 8,9 and 10)视为访问(accessed)(A),可写(write-enable)(W),和扩展方向(expansion-direction)(E)的。查看表3-1,关于代码和数据段总类型字段的编码。数据段只能是可读或者读写段,由write-enable位决定。
栈段是必须可读写的数据段。将一个不可写的数据段加载到SS寄存器将会产生一个通用保护异常(GP)。如果栈段的大小需要动态改变,栈段需要是一个向下扩展的数据段(expansion-direction)标记是set的)。这里,动态改变段限制将会使栈空间被加在栈的底部。如果想要静态的栈段空间大小,栈寄存器可能是向上扩展类型或者向下扩展类型。
访问位(accessed bit)决定了这个段定义了从上次操作系统或者执行指令clear这个位之后,这个段是否是可以访问的。无论何时处理器将段选择符加载到段寄存器,它都会设置这个位,假定包含这个段描述符的内存支持处理器写。这个位会保持set状态直到显式的clear。这个位可以在虚拟内存管理中使用和在debugging中使用。
对于代码段,类型字段中三个低顺序位分别意味着可访问(accessed)(A),可读(read enable)(R),和一致(conforming)(C)。代码段可以使只执行(execute-only)或者可执行/读取(execute/read),取决于可读位的设置。一个可执行/读取段可能用在常量和静态数据都已经被放置在指令代码的ROM中。数据可能通过使用重写前缀的CS指令或者在数据段寄存器(DS,ES,FS or GS寄存器)中加代码段的段选择器来读取。在保护模式下,代码段是不可写的。
代码段可以是一致的(conforming)或者是非一致的(nonconforming)。将执行程序转换成更加特权的(more-privileged)一致段允许代码继续在当前特权级别执行。在不同特权级别的非一致段中进行转换会导致一个通用保护异常(GP),除非使用一个调用门或者任务门。不访问受保护功能和处理某些类型的异常(比如,除异常或者溢出)的系统工具可能被加载在一致代码段中。需要避免被从低特权等级的程序和过程中执行的系统工具需要被放置在非一致代码段。
注意
- 无论触发段是一致的还是非一致的,执行过程不能通过一个调用(call)或者一个跳转(jump)到一个低特权的(特权等级的数字更大)代码段。试图进行这样的操作会导致一个通用保护异常。
- 所有的数据段都是非一致的,意味着它们无法在低特权的程序或者过程中被访问。然而,不同于代码段,数据段可以不经过使用一个特殊的访问门被更高特权程序或者过程访问。如果GDT或者LDT的段描述符被放置在ROM中,如果软件或者处理器想要更新(写入)基于ROM(ROM-based)段描述符,处理器会进入一个模糊的循环。设置所有ROM中的段描述符的可访问位可以避免这个问题。当然,移除试图修改ROM中段描述符的操作系统或者可执行代码(也可以避免这个问题)。
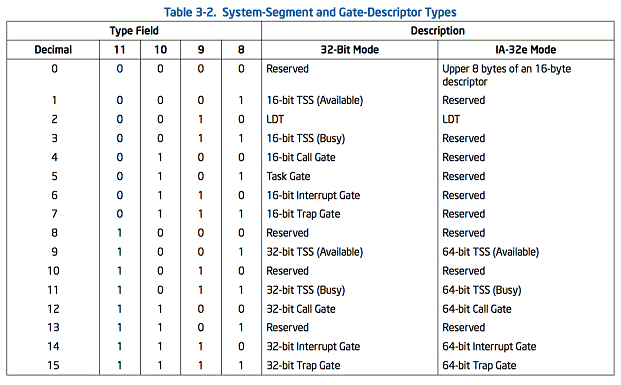
2.2.4. 系统描述符类型
当段描述符中的S(描述符类型(descriptor type))标志位是clear,描述符类型是系统描述符。处理器能识别下列类型的系统描述符:
- 本地描述符-表(local descriptor-table)(LDT)段描述符
- 任务状态段(task-state segment)(TSS)描述符
- 门调用(call-gate)描述符
- 中断门(interrupt-gate)描述符
- 陷阱门(trap-gate)描述符
- 任务门(task-gate)描述符
这些描述符类型分为两类:系统段(system-segment)描述符和门(gate)描述符gate。系统段描述符指向系统段(LDT和TSS段)。门描述符分为放置有指向代码段中的过程实体的门(call,interrupt, and trap gates)或者放置TSS的段选择器的门(task gates)。
表3-2显示的是系统段描述符和门描述符中的类型字段的编码。注意在IA-32e模式下,系统描述符是16字节的而不是8字节。
2.2.5. 段描述符表
一个段描述符表是一个段描述符的数组(参见图3-10)。一个描述表的长度是可变的,并且最多可以容纳8192(2^13)个8-byte的描述符。有下面两种描述符表:
- 全局描述符表(the global descriptor table)(GDT)
本地描述附表(the local descriptor tables)(LDT)
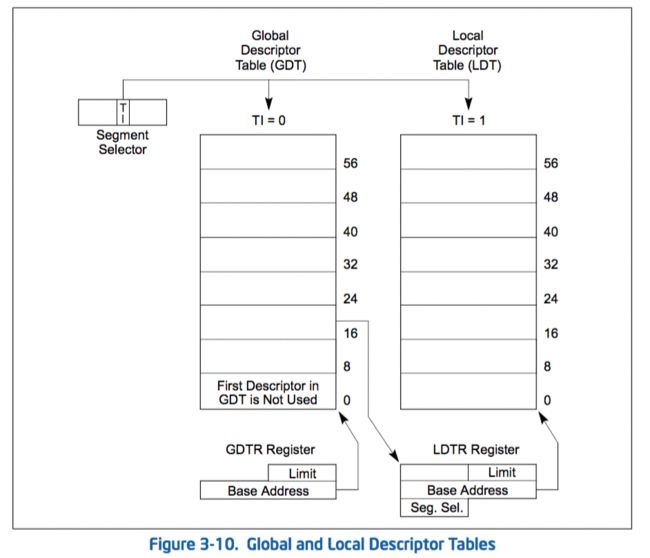
每一个系统必须定义一个GDT提供给系统里面所有的程序和任务。定义一个或者多个LDT是可选项。比如,可以给每一个正在运行的独立的任务定义一个LDT,或者一些或者所有任务共享一个相同的LDT。
GDT本身不是段;相反的,它是一个线性地址空间里面的数据结构。GDT的线性地址的基址和限制必须被加载到GDTR寄存器中。GDT的基址必须是8字节边界对齐的,以满足处理器的最佳表现。GDT的限制值是通过字节描述的。和段一样,通过将限制值和基址相加可以得到最后一个地址的有效字节。限制值为0实际上意味着一个有效字节。因为段描述符总是8字节长的,GDT限制值应该总是比8得倍数少1(也就是说,8N-1)。
GDT中的第一个描述符不是给处理器使用的。当把一个指向这个”空描述符(null descriptor)”的段选择器加载到数据段寄存器(DS,ES,FS, or GS)并不会产生异常。但是试图使用这个描述符来访问内存的时候,会产生一个通用保护异常(GP)。通过使用这个段选择器初始化段寄存器,意外引用到未使用的段寄存器,会保证产生一个异常。
LDT是位于LDT类型的系统段。GDT必须包含一个LDT段的段描述符。如果系统支持多LDTs,每一个必须在GDT总有一个分隔的段选择器和段描述符。GDT可以位于LDT段描述符的任意位置。
一个LDT和他的段选择器是可访问的。为了排除在LDT中访问时的地址转换,LDT的段选择器,基本线性地址址,限制,和访问权限存储在LDTR寄存器中。
当(将GDT)在GDTR中store时(使用SGDT指令),一个48-bit”伪描述符(pseudo-descriptor)”保存在内存中(参见图3-11)。为了避免对齐用户模式(特权等级3)下的对齐检查错误,加的描述符需要位于偶数位的字地址(就是说,address MOD 4 = 2)。这使得处理器存储一个对齐的字,紧接着是一个对齐的双字。用户模式程序经常不存储伪描述符,但是通过这种方式对齐伪描述符可以避免产生一个对齐检查错误异常。当使用SIDT指令store IDTR寄存器时,也需要相同的对齐。当store LDTR或者任务寄存器(各自使用SLDT或者STR指令),伪描述符应该存放在双字地址(就是说,address MOD 4 = 0)。

2.2.5.1. 段寄存器及段描述符表寄存器
在保护模式下使用32位通用寄存器,因而可供寻址的物理内存多达232=4GB。并且此时处理器对段寄存器的使用方式也发生了改变,段寄存器不再被解释为段的基地址,而是将该寄存器的16个位分成3个用于不同功能的域:
如上图所示,第3~15位存放选择子(Selector),用于索引描述符表内的一个描述符,该描述符用于描述存储器段的位置、长度和访问权限。并且在TI=0时选择全局描述符表(Global Descriptor Table, GDT),TI=1时选择局部描述符表(Local Descriptor Table, LDT)。其中全局描述符表包含所有进程的段定义,而局部描述符表则通常由某个指定的进程所使用。因为段选择子为13位,所以总共可以在一个全局/局部描述符表中索引出8192(213=8192)项,而每个描述符的大小为8个字节,因此每个全局/局部描述符表占用64KB内存空间。通常情况下操作系统并不为应用创建LDT,除非应用程序显示要求这么做,并且所有的进程均共享同一个GDT,这就意味着默认情况下整个系统的分段结构只由一个GDT指示。此外上述段描述符表的基地址被存放在一组专用寄存器中,这些专用寄存器被称为段描述符表寄存器:
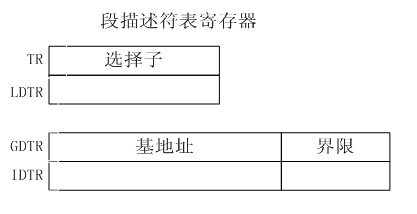
如图所示,TR中包含的选择子用于从任务的描述符表中索引出一个描述符,从而在多任务系统中实现上下文切换操作,LDTR寄存器中包含的选择子则用于从局部描述符表中索引出一个描述符。另外的GDTR与IDTR寄存器包含基地址及界限域,其中界限域的数据位宽度为16,基地址域的数据位宽度为32。在进入保护模式之前,必须先初始化中断描述符表,此后在保护模式下,全局描述符表的基地址及其界限才被装入GDTR中。
- 寻址全局描述符时,首先根据GDTR得到全局描述符表的基地址,之后通过段寄存器中的13位段选择子索引出其中的一个描述符。
- 在寻址局部描述符之前,操作系统会在全局描述符表中为某个具体应用的局部描述符表进行注册。此后若段寄存器中的TI域被置位,则通过GDTR中的基地址域及LDTR中的段选择子从全局描述符表中找到对应的描述符,该描述符包含了局部描述符的基地址,界限及访问权限等,接着根据段寄存器中的13位段选择子在局部描述符表中索引出相应的局部描述符表项,图解如下:
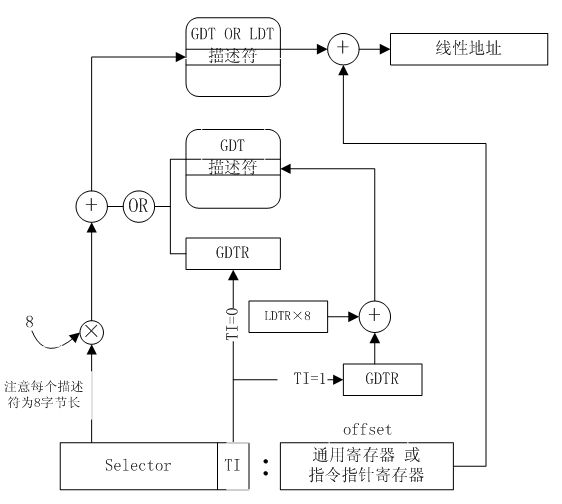
另外段寄存器中的RPL域指示对存储器段的请求优先级。因为该域数据位的宽度为2,所以总共有4种可以使用的优先级。但Windows/Linux均只使用其中的两种,且将优先级00赋予内核和驱动,而将优先级11分配给应用程序。优先级从环0~环3逐渐降低,注意只有请求优先级(RPL)等于或高于段描述符中访问权限域的优先级(DPL)才允许访问,否则系统将指示应用程序违例。
2.2.5.2. IA-32e模式下的段描述符表
在IA-32e 模式,一个段描述符表可以包含最多8192(2^13)个8-byte描述符。段描述符表总的每一个实体可以是8字节的。系统描述符扩展成16字节(拥有两倍的实体空间)。
GDTR和LDTR寄存器被扩展了以存放64-bit基址。相应的伪描述符是80位的。 下列的系统描述符被扩展成16字节:
- 调用门(call gate)描述符
- IDT门(IDT gate)描述符
- LDT和TSS描述符
2.3. 长模式(IA-32e模式)
目前的CPU大多是支持X86-64技术的兼容CPU,这包括AMD64以及Intel的IA32E(后被正式命名为EM64T,Extended Memory 64 Technology),因为AMD64先出,而EM64T与AMD64完全兼容,所以也统一称为AMD64技术。由于AMD64技术向下兼容,所以很好的承接了以前的16位、32位资源,与此相应,X86-64兼容CPU可以运行在多种模式之下,除了熟悉的实模式,保护模式,还有长模式(Long mode)等,在长模式下,处理器完全执行64位指令,使用64位地址空间(物理内存的寻址能力却没有被完全扩展到64位,因为目前的众多CPU在其寿命期限之内都没有机会见识到如此巨大的内存)和64操作数。因此,为了降低制造成本,目前的CPU被限制在略少于64位寻址。注意,当前的这些限制可以(也极有可能)随着未来新型CPU微架构的发布而改变。结果就是,如果物理内存容量受限,即使开启全部的64位虚拟地址空间也没有用。后者因此被加以限制来节省成本。具体来说,CPU中可以节省成本的地方有读取/存储单元、缓冲存储器大小和MMU和TLB的复杂程度。
当处于长模式(Long mode)时,64位应用程序(或者是操作系统)可以使用64位指令和寄存器,而32位和16位程序将以一种兼容子模式运行。x86-32架构的cpu,从很早的版本开始就支持“物理地址扩展”(PAE),该技术通过内存分页机制将应用程序使用的32位地址映射到36位或52位。同样,x86-64的cpu会做一个从64位线性地址到64位物理的映射,之后检查这个64位物理地址的63到52位是否全0或全1,并取该地址的51到0位作为实际的物理地址。因此:
- 就目前的cpu来说,无论工作在长模式下,还是32位保护模式下,寻址能力都是52位。但是,因为线性地址从32位提高到了64位,单个程序能够使用的内存量变多了。实际上,32位windows上的程序只能使用2gb内存,而64位windows的64位程序可用的内存量实际上是无限的。
- 长模式下cpu屏蔽了段机制,简化了应用程序的内存管理,提高了单个寄存器的运算位数,并引入了一系列的新指令集和前缀(比如rex),使得合理优化过的64位程序比32位程序效率要高一些。
- 长模式下引入了rip相对寻址机制,使得“位置无关代码”的实现更容易而且更快。
不过,因为64位windows下也要兼容32位程序,所以windows不得不维持两份相关代码,这就是wow64的来历,wow64会多占用一些资源。
还有一点是,64位下的兼容模式不再支持16位程序,所以运行16位程序需要额外的软件,比如dosbox。
2.3.1. x64下的物理资源及系统数据结构
2.3.1.1. segment registers
x64 体系在硬件级上最大限度地削弱了 segmentation 段式管理。采用平坦内存管理模式,因此体现出来的思想是 base 为 0、limit 忽略。但是,x64 还是对 segmentation 提供了某种程度上的支持。体现在 FS 与 GS 的与众不同。segment registers 的 selector 与原来的 x86 下意义不变。
在 64 bit 模式下:
(1)code register(CS)
- CS.base = 0(强制为 0,实际上等于无效)
- CS.limit = invalid
- attribute:仅 CS.L 、CS.D、CS.P、CS.C 以及 CS.DPL 属性是有效的。
注意:64 bit 模式下的 code segment descriptors 中的 L 位、D 位、P 位、C 位以及 DPL 域是有效的。code segment descriptor 加载到 CS 后仅 CS.L 、CS.D、CS.P、CS.C 以及 CS.DPL 属性是有效的。
在 compatibility 模式下 code segment descriptor 和 CS 寄存器与原来 x86 意义相同。
(2)data registers (DS、ES 以及 SS)
- DS.base = 0(强制为 0,实际上等于无效)
- DS.limit = invalid
- DS.attribute = invalid:所有的属性域都是无效的。
data registers 的所有域都是无效的。data segment 的 attribute 是无效的,那么也包括 DPL、D/B 属性。
在 64 bit 模式下,所有的 data segment 都具有 readable/writable 属性,processor 对 data segment 的访问不进行权限 check 以及 limit 检查。
(3)FS 与 GS
- FS.base 是完整是的 64 位。
- FS.limit = invalid
- FS.attribute = invalid
与其它 data registers 不同的是,FS 与 GS 的 base 是有效的。支持完整的 64 位地址。但是 limit 和 attribute 依旧无效的。
1、为 FS 和 GS 加载非 0 的 64 位 base 值,使用以下指令:
mov fs, ax
或
pop fs注意:这条指令只能为 fs 提供 32 位的 base 值,这根本的原因是:data segment descriptor 提供的 base 是 32 位值。在 x64 里的 segment descriptor 是 8 个字节。也就是 base 是 4 个字节。通过 selector 加载 base 值,只能获取 32 位地址值。
2、为 FS 和 GS提供 64 位地址值,可以使用以下指令:
mov ecx, C0000100 /* FS.base msr 地址 */
mov edx, FFFFF800
mov eax, 0F801000
wrmsr /* 写 FS.base */
上面代码为 FS.base 提供 0xFFFFF8000F801000 地址。
mov ecx, C0000101 /* GS.base msr 地址 */
mov edx, FFFFF800
mov eax, 0F801000
wrmsr /* 写 GS.base */
上面代码为 GS.base 提供 0xFFFFF8000F801000 地址。
另一种方法是使用 swapgs 指令,这条指令将 kernelGS 地址与 GS.base 交换。
2.3.1.2. descriptors 结构
x64 体系已经不提供对 segmentation 的支持(或者说最大程度削弱了),对于 user segment descriptor 来说,还是停留在 x86 的阶段,绝大部分的功能已经去掉。但是对于 system descriptor 来说,它是被扩展为 16 个字节,是 128 位的数据结构。因此,descriptors 结构要分两部分来看。
1) user segment descriptors
在 long mode 下对 user segment descriptor 有两种解释结果:
- 64 位模式下的 descriptor
- compatibility 模式下的 descriptor
在 compatibility 模式下 code segment descriptor 与 legacy x86 的 code segment descriptor 在意义在只有一点差异,在 legacy x86 模式下不存在 L 属性,这个 L 位在 legacy x86 模式下是 0 值。而 compatibility 模式下的 L 属性也是 0 值。实际上它们是相等的。
下面是在 64 位模式下的解释:
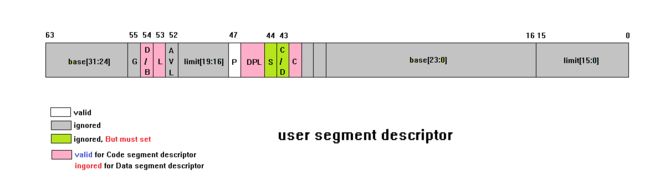
它们的 segment descriptor 的 S = 1 指示它们是 user segment descriptor。上图灰色部分的 limit 和 base在 user segment descriptor 里是无效被忽略的,有部分属性是支持的。然而 attribute 部分对于 Code segment descriptor 和 Data segment descriptor 有着不同的表现,粉红色部分在 code segmnt descriptor 里是有效的,在 data segment descriptor 里是无效的。
a) Code segment descriptor
上图中的白色部分和红色部分在 code segment descriptor 里是有效的,它们是:
- C(Conforming):指示 code segment 是 conforming 还是 non-conforming
类型,它们在权限控制上的表现是不一样的。 - DPL(Descriptor Privilige Level): 指示访问 code segment 需要的权限
- P(Present):指示 code segment 是否加载在内存中
- L(Long):指示 code segment 是 64 位模式代码还是 compatibility 模式代码
- D(Default operand size):指示 code segment 的 default operand size
这些 attribute 位加载到 CS 寄存器后,在 CS 寄存器的 attribute 里同样是有效的。虽然 x64 体系非常想抛弃 segmentation 机制,但是为了整个 x86 架构的兼容性不得以而为之:
- C 和 DPL 为权限控制和转移而保留
- L 和 D 为 processor 模式和指令操作数而设
- P 恐怕是最没有异议
图中绿色部分比较特别:
- S(system) 标志
- C/D(Code/Data)标志
虽然这两个标志是无效的,但是您必须为它设置初始值,在设置初始值后你不能进行更改,这是无效的一面。对于 Code segment descriptor 来说,它必须设为(注意是:必须):
- S = 1
- C/D = 1
说明这个 descriptor 是 code segment descriptor,如果你尝试加载一个 S = 0 或者 C/D = 0 的 descriptor 进入 CS 寄存器,将会产生 #GP 异常。而下面两个类型属性是无效的:
- R(Readable)
- A(Accessed)
那么 Code segment 在 64 位模式下强制为 Readable 可读。
b) Data segment descriptor
在 data segment descriptor 情况有些特别。对于加载到 ES, DS, SS 寄存器的 data segment descriptor 来说仅有一个属性是有效的:
- P(Present)
对于加载到 FS 和 GS 寄存器的 data segment descriptor 来说 base 是有效的,那么可以在 FS 和 GS 寄存器的 base 里设置非 0 的 segment base 值。 同样必须设置 S 和 C/D 属性,在 data segment descriptor 里它们必须为:
- S = 1
- C/D = 0
指示该 descriptor 是 data segment descriptor,如果尝试加载 S = 0 或者 C/D = 1 的 descriptor 进入 DS,ES,SS,FS 以及 GS 寄存器会产生 #GP 异常。下面的类型属性是无效的:
- E(Expand-Down)
- W(Writable)
- A(Accessed)
那么在 64 位模式下,data segment 被强制为 Expand-Up 和 Writable 的。
2) system descriptors
包括 LDT descriptor、TSS descriptor 。这些 descriptor 被扩展为 16 个字节共 128 位。descriptor 的 base 域被扩展为 64 位值。用来在 64 位的线性地址空间中定位。在 compatibility 模式下,LDT / TSS 依旧是 32 位的 descriptor。

64 位模式下的 system segment descriptor 是 16 bytes 共 128 位,包括:
- 20 位的 segment limit
- 64 位的 segment base
- 12 位的 segment attribute
在 64 位模式下 user segment descriptor 是 8 bytes,而 system segment descriptor 是 16 bytes 的,它们存放在 GDT 表中就可能会产生了跨 descriptor 边界的问题。
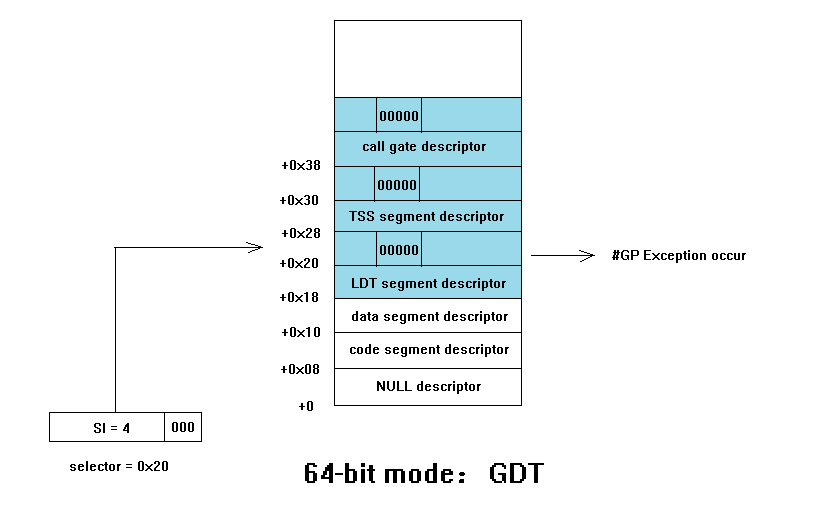
上图显示了在 64 位模式下的一个跨 descriptor 边界产生 #GP 异常的示例:
当使用 selector = 0x20 企图访问一个 user segment descriptor,但是并不如愿,+0x20 位置上并不是一个有效 user segment descriptor,它只是 LDT descriptor 的高半部分
结果会怎样?答案是:未知
因此为了防止这种未知结果的产生,x64 体系中建议:须将 system descirptor(包括 call gate descriptor)的高 64 位中的对应 S 标志和 type 位置上置00000,但是不包括 interrupt gate 和 trap gate。由于 00000(代表 0 类型的 system descriptor)是无效的 descriptor 类型,因此访问这样的 descriptor 会导致 #GP 异常的发生。从而避免未知结果的产生。这就是上图中上半部分的 S 和 type 域为何置为 00000 的原因。当然这个跨 descriptor 边界的情况在 LDT 也可能发生。但是在 IDT 是不可能发生的,那是因为 IDT 只能存在 system descriptor 不可存放 user segment descriptor。因此 IDT 表的索引因子固定为 16,这就是 interrupt gate 和 trap gate 的高半部分 s 和 type 域不用置为 00000 的原因。
LDT/TSS segment descriptor 大部分属性是有效的,包括:
- type
- S
- DPL
- P
- AVL
- G
它们的 type 包括:
- type = 2 :64-bit LDT
- type = 9 :available 64-bit TSS
- type = B :busy 64-bit TSS
64 位模式的 system segment descriptor 已经不支持 16 位的 TSS,原来的 32 位 TSS 变成了 64 位的 TSS。
system segment descriptor 在 compatibility mode 下依旧是 32 位的 descriptor,这和 64 bit 模式下区别很大。在一个可以执行 legacy 32 位程序的 OS 里,应该要准备两份 LDT/TSS segment descriptor:64 位的 LDT/TSS segment descriptor 和 32 位的 LDT/TSS segment descriptor
3) gate descriptor
long mode 下不存在 task gate。所有的 gate(call、interrupt / trap) 都 64 位的。gate 所索引的 code segment 是 64 位的 code segment(L = 1 && D = 0)
注意:
1、long mode 下的 segment descriptor 与 x86 原有的 segment descriptor 格式完全一致,只是在 64 bit 模式中 descriptor 的大部分域是无效的。
2、64 bit 模式下的 system descriptor 被扩展为 16 个字节。由于 system descriptor 中的 base 是有效的,base 被扩展为 64 位,故 system descriptor 被扩展为 128 位。
2.3.1.3. descriptor table
在 long mode 下 GDT 可以容纳:
- 32 位的 code segment descriptor
- 32 位的 data segment descripotr
- 64 位的 LDT segment descriptor
- 64 位的 TSS segment descriptor
- 64 位的 call gate descriptor
全部 system descriptor(包括:LDT/TSS descriptor 和 call gate descriptor)都扩展为 64 位的 descriptor
注意:这些 system GDT entries 是 16 bytes 128 位的大小,这里所说的 64 位的descriptor 是指 descriptor 的类型是 64 位,它的大小实际上 16 bytes,上文已经提过在 long mode 下“跨 descriptor 边界”问题的产生就是因为这里有 32 位的 descriptor 和 64 位的 descriptor 同时存放在 GDT 里所造成的。
1) long mode 下 GDT 的 base
GDTR.base 扩展为 64 位,因此 GDT 可以在 64 位线性空间的任何位置,但 limit 还是 16 位不变。
2) long mode 下 GDT 的索引
long mode 下 GDT 依然是按以前的方式索引查找 descriptor,即:selctor.SI * 8 而不是 selector.SI * 16,这是因为还存在 32 位的 code/data segment descriptor 的缘故。这是造成跨 descriptor 边界的原因。
3) long mode 下的 LDT
在 long mode 下的 LDT 可以存放:
- 32 位 code/data segment descriptor
- 64 位的 call gate desciptor
因此,在 LDT 同样存在“跨 descriptor 边界”的问题,IDTR.base 被扩展为 64 位,它的值由 64 位的 LDT segment descriptor 加载而来
4) long mode 下的 IDT
在 long mode 下 IDT 可以存放:
- 64 位的 interrupt gate descriptor
- 64 位的 trap gate descriptor
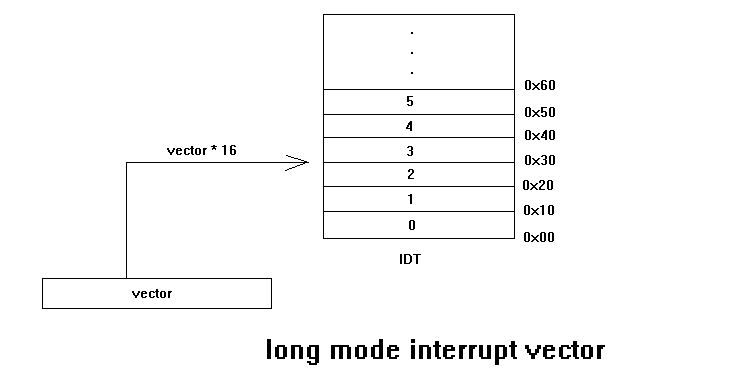
在 long mode 的 IDT 里不存在跨 descriptor 边界问题,interrupt vector 的索引大小固定是 16 bytes
2.4. 其他模式
2.4.1. 系统管理模式
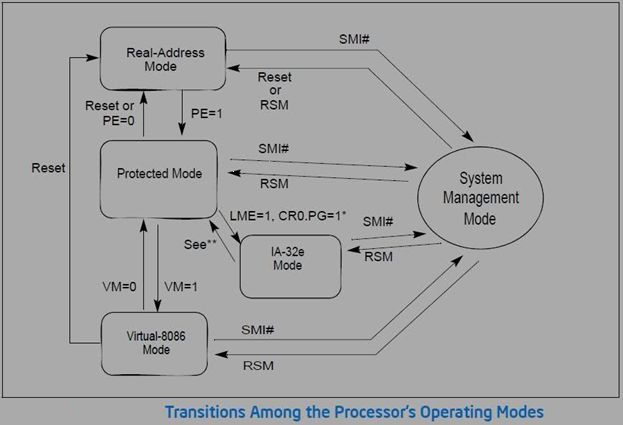
系统管理模式,System Management Mode,系统管理模式(SMM)是Intel在386SL之后引入x86体系结构的一种CPU的执行模式。系统管理模式只能通过系统管理中断(System Management Interrupt, SMI)进入,并只能通过执行RSM指令退出。SMM模式对操作系统透明,换句话说,操作系统根本不知道系统何时进入SMM模式,也无法感知SMM模式曾经执行过。为了实现SMM,Intel在其CPU上新增了一个引脚SMI# Pin,当这个引脚上为高电平的时候,CPU会进入该模式。在SMM模式下一切被都屏蔽,包括所有的中断。SMM模式下的执行的程序被称作SMM处理程序,所有的SMM处理程序只能在称作系统管理内存(System Management RAM,SMRAM)的空间内运行。可以通过设置SMBASE的寄存器来设置SMRAM的空间。SMM处理程序只能由系统固件实现。下图显示了SMM与其他处理器运行模式(保护模式,实模式和虚拟- 8086)之间的切换过程。
2.4.2. 虚拟8086模式
虚拟8086模式,Virtual-8086 Mode,V86模式,在保护模式下CPU可以进入到这种模式,即虚拟8086模式是保护模式下的一种工作方式。CPU把V86任务作为与其它任务具有同等地位的一个任务,可以支持多个V86任务,每个V86任务是相对独立的。在虚拟8086模式下,处理器工作方式类似于8086。