Redis 复制的原理与优化
Redis 复制的原理与优化
- 什么是主从复制
- 复制的配置
- 全量复制和部分复制
- 故障处理
主从复制:
为应对单机故障问题,redis采用主从复制的方式 实现高可用。从节点将主节点数据复制过来 保持数据同步。
一主多从的高可用方式

主从复制的作用:多数据副本,扩展读性能。
主从复制的配置
- salveof命令
通过命令方式 slaveof 127.0.0.1 6379,将6380成为6379的从节点通过过来,命令异步响应。数据同步根据数据量大小来决定复制的时间大小。

取消复制 通过slaveof no one 命令,注意 6380的依然保留了6379的数据

- 配置
修改redis.conf配置文件
slaveof ip port 主节点的ip 端口号
slave-read-only yes 从节点只处理读请求
两种方式对比
| 方式 | 命令 | 配置 |
| 优点 | 无需重启 | 统一配置 |
| 缺点 | 不便于管理 | 需要重启 |
全量复制和部分复制
Redis在2.8及以上版本使用psync命令完成主从数据同步,同步过程分为:全量复制和部分复制
- 全量复制:一般用于初次复制场景,Redis早期支持的复制功能只有全量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会对主从节点和网络造成很大的开销。
- 部分复制:用于处理在主从复制中因网络闪断等原因造成的数据丢失场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。
部分复制是对老版复制的重大优化,有效避免了不必要的全量复制操 作。因此当使用复制功能时,尽量采用2.8以上版本的Redis。
psync命令运行需要以下组件支持:
- 主Redis的复制偏移量(replication offset)和从Redis的复制偏移量。
- 主Redis的复制积压缓冲区(replication backlog)。
- Redis的运行ID(run ID)。
runid
Redis 服务器的随机标识符(用于 Sentinel 和集群),重启后就会改变;当复制时发现和之前的 run_id 不同时,将会对数据全量同步。
[root@localhost data]# redis-cli -p 6379 info server | grep run
run_id:345dda992e5064bc80e01f96ea90f729b722b2ea
[root@localhost data]# redis-cli -p 6380 info server | grep run
run_id:cd46b4591e3d8984bc984223ed4321f8c6f9981b
复制偏移量
通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
1.参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在info relication中的master_repl_offset指标中:
127.0.0.1:6379> info replication
# Replication
role:master
...
master_repl_offset:1055130
2.从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量,统计指标如下:
127.0.0.1:6379> info replication
connected_slaves:1 slave0:ip=127.0.0.1,port=6380,state=online,offset=1055214,lag=1
...
3.从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统计信息在info relication中的slave_repl_offset指标中:
127.0.0.1:6380> info replication
# Replication
role:slave
...
slave_repl_offset:1055214
主从复制同步流程-全量复制
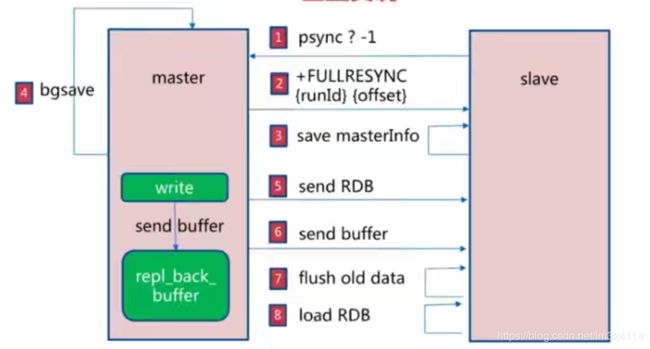
- slave 刚连接master 会执行后会给master 发送psync ?-1 表示全量复制
- master 会将自己的runId 和偏移量响应给slave
- slave 保存master runId偏移量等信息
- master 执行bgsave命令,进行RDB数据快照存储
- master 将存储的快照数据 发送i给salve
- master 将全量数据进行RDB存储时,也会对外提供服务这时写入的的操作数据也会存储在buffer中,将buffer发送给slave
- slave 清除老数据
- 加载RDB 进行数据同步
全量复制的开销
- bgsave时间
- RDB网络传输时间
- 从节点清空数据时间
- 从节点加载RDB时间
主从复制同步流程-部分复制

- 当网络出现抖动 slave与master失去连接
- 网络恢复 slave与master重连
- slave会将偏移量和runId 发送给master
- master收到 slave偏移量和runId 在系统中buffer中对比,如果偏移量在buffer中 就执行5、6 否则直接全量复制
- 将增量数据发送给slave
slave宕机

这种架构读写分离情况下,宕机的slave无法从master中同步数据
master宕机

Redis的master就无法提供服务了,只有slave可以提供数据读取服务
解决方法:把其中一个slave为成master,以提供写入数据功能,另外一台slave重新做为新的master的从节点,提供读取数据功能,这种解决方法依然需要手动完成

主从模式没有实现故障的自动转移,这就是Redis的sentinel的作用了
读写分离
读写分离:master负责写入数据,把读取数据的流量分摊到slave节点

读写分离一方面可以减轻master的压力,另一方面又扩展了读取数据的能力
读写分离可以遇到的问题:
- 复制数据延迟
大多数情况下,master采用异步方式将数据同步给slave,在这个过程中会有一个时间差
当slave遇到阻塞时,接收数据会有一定延迟,在这个时间段内从slave读取数据可能会出现数据不一致的情况
可以对master和slave的offset值进行监控,当offset值相差过多时,可以把读流量转换到master上,但是这种方式有一定的成本
- 读到过期数据
Redis删除过期数据的方式
方式一:懒惰策略
当Redis操作这个数据时,才会去看这个数据是否过期,如果数据已经过期,会返回一个-2给客户端,表示查询的数据已经过期方式二:
每隔一个周期,Redis会采集一部分key,看这些key是否过期
如果过期key非常多或者采样速度慢于key过期速度时,就会有很多过期key没有被删除
此时slave会同步包括过期key在内的master上的所有数据
由于slave没有删除数据的权限,此时基于读写分离的模式,客户端会从slave中读取一些过期的数据,也即脏数据- 从节点故障
slave宕机,从slave节点迁移为master节点的成本很高
在考虑使用读写分离之前,首先要考虑优化master节点的问题
Redis的性能很高,可以满足大部分场景,可以优化一些内存的配置参数或者AOF的策略,也可以考虑使用Redis分布式
主从配置不一致
第一种情况是:例如maxmemory不一致:丢失数据
如master节点分配的内存为4G,而slave节点分配的内存只有2G时,此时虽然可以进行正常的主从复制
但当slave从master同步的数据大于2G时,slave不会抛出异常,但会触发slave节点的maxmemory-policy策略,对同步的数据进行一部分的淘汰,此时slave中的数据已经不完整了,造成丢失数据的情况
另一种主从配置不一致的情况是:对master节点进行数据结构优化,但是没有对slave做同样的优化,会造成master和slave的内存不一致
规避全量复制
- 全量复制的开销是非常大的
第一次为一个master配置一个slave时,slave中没有任何数据,进行全量复制不可避免
解决方法:主从节点的maxmemory不要设置过大,则传输和加载RDB文件的速度会很快,开销相对会小一些,也可以在用户访问量比较低时进行全量复制
- 节点run_id不匹配
当master重启时,master的run_id会发生变化。slave在同步数据时发现之前保存的master的run_id与现在的run_id不匹配,会认为当前master不安全
解决方法:
做一次全量复制,当master发生故障时,slave转换为master提供数据写入,或者使用Redis哨兵和集群Redis4.0版本中提供新的方法:当master的run_id发生改变时,做故障转移可以避免做全量复制
- 复制缓冲区不足
复制缓冲区的作用是把新的命令写入到缓冲区中
复制缓冲区实际是一个队列,默认大小为1MB,即复制缓冲区只能保存1MB大小的数据
如果slave与master的网络断开,master就会把新写入的数据保存到复制缓冲区中
当写入到复制缓冲区内的数据小于1MB时,就可以做部分复制,避免全量复制的问题
如果新写入的数据大于1MB时,就只能做全量复制了在配置文件中修改rel_backlog_size选项来加大复制缓冲区的大小,来减少全量复制的情况出现
规避复制风暴
主从架构中,master节点重启时,则master的run_id会发生变化,所有的slave节点都会进行主从复制
master生成RDB文件,然后所有slave节点都会同步RDB文件,在这个过程中对master节点的CPU,内存,硬盘有很大的开销,这就是复制风暴
单主节点复制风暴解决方法
更换复制拓朴
单机多部署复制风暴

一台服务器上的所有节点都是master,如果这台服务器系统发生重启,则所有的slave节点都从这台服务器进行全量复制,会对服务器造成很大的压力
主节点分散多机器
将master分配到不同的服务器上Redis的主从模式简单总结
一个master可以有多个slave
一个slave还可以有slave
一个slave只能有一个master
数据流向是单向的,只能从master到slave