学习总结《An Attention Enhanced Graph Convolutional LSTM Network forSkeleton-Based Action Recognition》
An Attention Enhanced Graph Convolutional LSTM Network forSkeleton-Based Action Recognition
一种基于骨架的注意力增强图卷积LSTM网络行为识别方法
投稿:
中国科学院自动化研究所模式识别国家实验室智能感知与计算研究中心
中国科学院大学
中国科学技术大学
收录:CVPR2019
本文提出一个新颖的注意增强图卷积LSTM网络(AGC-LATM)来对人类动作进行识别从骨架数据中。提出的AGC-LSTM不仅能捕获有判别特征在空间配置和时间的动态,也能探索共现关系在空间和时间领域中。在AGC-LSTM顶层我们也提出了一个时间分层框架来增强时序感受野,提高了高层与义表示的学习能力,并且显著的降低了计算成本。此外,为了选择有区分性的空间信息,采用注意力机制来增强每个AGC-LSTM层的关键点的信息。
现有的人体行为识别方法主要是基于RGB视频和2D骨骼数据。其中,基于RGB的行为识别方法主要是其中在对RGB帧和光流在空间和时序表达上进行建模。尽管,基于RGB的方法已经取得了很好的效果,但是其仍然存在一定的局限性,例如背景混乱,光照变化,外观变化等等。三维骨骼数据通过一组人体关键节点的三维坐标来表示人体结构。骨架序列不包含颜色信息,所以它不受RGB视频的限制。这样的建模方法可以对人体行为判别性的时序特征进行建模。
人体骨架具有三个显著特征:
1. 每个节点与其相连的节点之间存在较强的相关性,使得骨架包含丰富的人体结构信息。
2. 时间上的连续性不仅存在于同一关节点上(例如 手,腕和肘)
3. 时间和空间域之间存在着一种共现关系。本文提出了一个新的基于骨架的注意力增强图卷积LSTM网络(AGC-LSTM)的通用框架,通过同步学习上述的时间和空间特征,从而提高了骨架的表示能力。
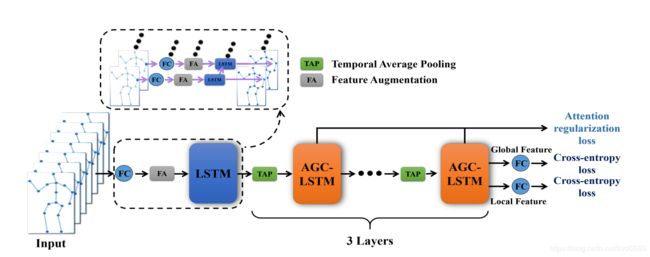
上图为本文提出的注意力增强图卷积LSTM网络(AGC-LSTM)的结构。特征增强利用位置特征计算特征差异,并将位置特征和特征差异连接在一起。LSTM被用来消除位置特征和特征差异之间的尺度差异。三个AGC-LSTM层能够对具有区分性的空间-时序特征进行建模。时间平均池化是在时间域中对平均池化的一个实现。我们使用所有节点的全局特征和最后一个AGC-LSTM层所关注节点的局部特征来对人体行为进行分类。
首先,将每个节点的坐标转化为具有线性层的空间特征。然后我们将空间特征和两个连续帧之间的特征差异连接起来从而组成一个扩展特征。为了消除两个特征之间的尺度差异,采用一个共享的LSTM来处理每个节点序列。接下来,我们准备使用三个AGC-LSTM层来对空间和时序特征进行建模。AGC-LSTM结构正如下图所示:

注释:上图是一个AGC-LSTM层的结构。不同于传统的LSTM网络,AGC-LSTM中的图卷积算子使得AGC-LSTM的输入,隐藏状态和单元存储器成为图结构数据。
如上图,由于AGC-LSTM的图卷积运算,AGC-LSTM不仅能有效的抓取空间配置和时序上的判别性特征,而且能够探索空间和时间域上的之间的共现关系。更特别的是,注意力机制在每个time-step 中能增强关键节点的特征,从而促进AGC-LSTM学习到更加具有判别性的特征。例如,肘,腕和手的特征对于握手这个动作非常重要,在行为识别过程中应该被增强。
受到CNN空间池化的启发,本文提出了一种时间平均池化的时间层次结构,以增加顶层AGC-LSTM层的时间感受野,从而增强学习高层时空语义特征的能力并且降低计算成本。最后,本文使用了所有节点的全局特征和最后一个AGC-LSTM层关注节点的局部特征来对人类行为进行分类。
提出的新网络(AGC-LSTM)的作用:
1. 能够有效抓取在空间构型和时间动态上的区别性特征
2. 能够探索在时空域上的共现关系
3. 提出了一个时间层次结构以此来增加AGC-LSTM顶层的时序接受域,而且能够提高学习高层语义表达的能力,显著减少计算量。
4. 对AGC-LSTM每层上的关键关节点进行增强处理,从而选择得到有区分性的空间信息。
本文的贡献:
1. 本文提出了一个基于骨架数据进行行为识别的新的通用AGC-LSTM网络。
我们是第一个进行图卷积LSTM网络实验的。
2. 本文提出的AGC-LSTM网络能够有效的抓取具有判别性的时空特征。更加具体的说,注意力机制将被用于增强关节点的特征,有助于提高时空表达力。
3. 本文提出了一个时间层次结构来增强学习学习高层时空语义特征的能力,并且能显著的降低计算成本。
4. 我们通过大量实验证明了,本文提出的模型在NTU RGB+D dataset 和 Northwestern-UCLA dataset的性能超过了目前最好的模型。
模型架构
3.1 图卷积神经网络
GCN是学习图结构数据表示形式的有效框架。各种GCN的变体已经在很多实验中取得了非常好的效果。对于基于骨架的行为识别,使Gt={Vt,Et}表示在t时单帧的人体骨架图,其中Vt代表N个关键节点的集合,Et是人体骨架边的集合。节点的邻接点集Vti被定义为 N(Vti) ={Vtj | d(Vti, Vtj)≤D} , 其中 d(Vti, Vtj) 代表Vti 到Vtj的最小路径长度。图标签的功能 ℓ:Vt→ {1,2, ..., K} 被设计用来给每个图节点 vti∈Vt 分配标签 {1,2, ..., K} ,它可以将节点Vti的邻居N(Vti)划分为固定数量的K个子集。
图卷积的计算公式为:
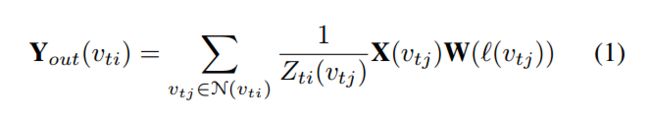
其中,X(Vti) 是节点Vtj 的特征。W(·)是一个权重函数,它从K权重分配由标签ℓ(vtj)索引的权重。Zti(vtj)是相应子集的编号,它规范了特征表示。Yout(vti) 表明图卷积在节点Vti的输出。进一步来说,通过邻接矩阵,上式又可表示为:
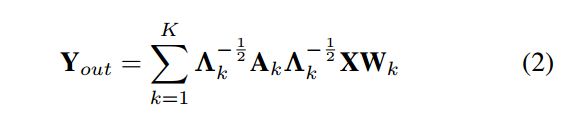
其中,Ak是空间维度上的邻接矩阵,标签k取值为k∈ {1,2, ..., K} 。 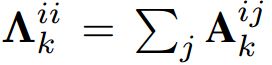 是一个表示度的矩阵。
是一个表示度的矩阵。
3.2 注意力增强图卷积LSTM
LSTM对于处理时序数据有着非常好的效果。但是,由于LSTM是全连接,对于基于骨架的行为识别忽略了空间相关性。相比于LSTM, AGC-LSTM不仅能够抓取空间结构和时序上的判别性特征,而且能够探索空间和时间域上的共现关系。
和LSTM类似, AGC-LSTM也包含三个门,一个输入门 i_t , 一个遗忘门f_t, 一个输出门 o_t 。然而,这些门是通过图卷积算子得到的。AGC-LSTM中 输入Xt, 隐含层Ht, 细胞记忆体Ct 都为图结构数据。
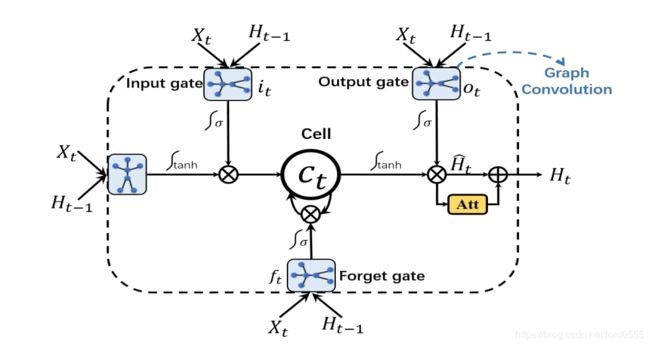
注释:该图为AGC-LSTM单元的结构。相比于LSTM,AGC-LSTM结构的内部计算为图卷积运算。为了突出更具判别性的信息,这个这个注意力机制用来增强关键节点的特征。
其中,AGC-LSTM单元的功能定义如下:
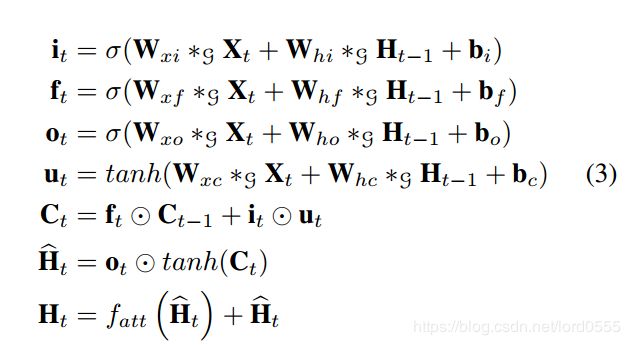
其中,∗G 表示图卷积运算,⊙表示Hadamard 积。
注:Hadamard 积计算如下:

σ(·) 代表sigmod 激活函数。u_t 代表非线性激活后的输入,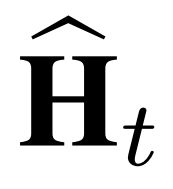 代表中间隐藏态。
代表中间隐藏态。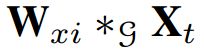 表示X_t与W_xi的图卷积,即为(1)式。
表示X_t与W_xi的图卷积,即为(1)式。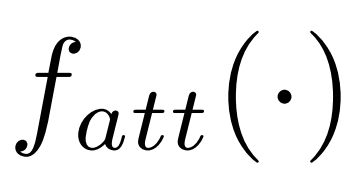 为一个注意力网络,他能选择关键节点的判别性信息。
为一个注意力网络,他能选择关键节点的判别性信息。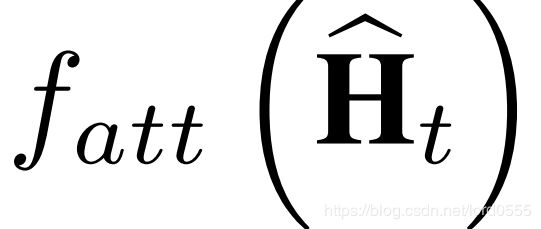 和 的和作为输出旨在不削弱非关注性节点信息的情况下增强关键节点的信息,从而保证空间关键信息的完整性。
和 的和作为输出旨在不削弱非关注性节点信息的情况下增强关键节点的信息,从而保证空间关键信息的完整性。
注意力网络通过一个软注意力机制来自适应的关注关键节点,它能够自适应的对节点的重要程度进行估计。
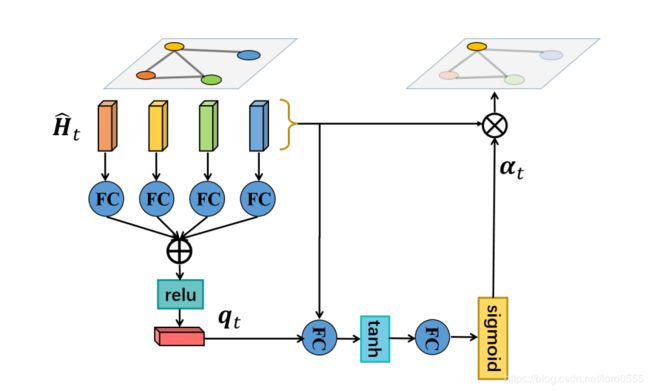
注:上图为空间注意力网络的插图。
AGC-LSTM的隐藏状态包含丰富的空间结构信息和时间动态,对于关键节点的选择具有有效的导向作用。因此,我们首先汇总所有节点的信息作为一个查询特征:

其中,W是可学习的参数矩阵。然后所有节点的注意力分数可以被如下计算:

其中,αt= (αt1, αt2, ..., αtN), U_s, W_h, W_q是可学习的参数矩阵。b_s, b_u为bias(偏离)。由于可能会存在多个关键节点,所以这里采用sigmod作为非线性激活函数。节点V_ti 的隐藏态H_ti 也可以被表示为(1 +α_ti)·H ̂_ti 。这个注意力增强隐藏状态H_t 将作为下一个AGC-LSTM层的输入。 注意, 在最后一个AGC-LSTM层,所有节点特征的聚合将充当全局特征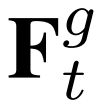 ,被注意节点的加权和将作为局部特征
,被注意节点的加权和将作为局部特征 :
:
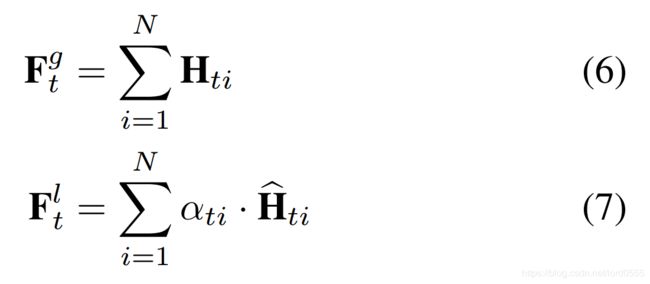
全局特征和局部特征被用来预测人体行为的类别。
3.3 AGC-LSTM 网络
接下来是本文所提出的框架的基本原理。
(1) 节点特征的表示。
对于骨架序列,我们首先使用一个线性层将每个节点的3D坐标映射到高维空间特征。第一个线性层将节点坐标编码成256维的矢量作为位置特征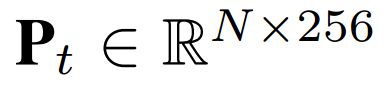 ,而
,而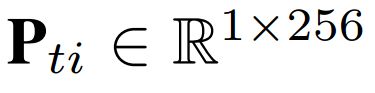 代表节点i的位置表示。由于只包含位置信息,位置特征P_ti 有利用在图模型上学习空间结构特性。两个连续帧之间的帧差异特征V_ti 能够促进AGC-LSTM网络动态特征的获取。为了兼顾着两个优点,将这两个特征连接到一起作为一个增强型特征来丰富特征信息。然而,相互连接的位置特征P_ti和帧差异特征V_ti存在着特征向量的尺度方差。因此,我们采用了LSTM层来消除两个特征之间的尺度方差:
代表节点i的位置表示。由于只包含位置信息,位置特征P_ti 有利用在图模型上学习空间结构特性。两个连续帧之间的帧差异特征V_ti 能够促进AGC-LSTM网络动态特征的获取。为了兼顾着两个优点,将这两个特征连接到一起作为一个增强型特征来丰富特征信息。然而,相互连接的位置特征P_ti和帧差异特征V_ti存在着特征向量的尺度方差。因此,我们采用了LSTM层来消除两个特征之间的尺度方差:
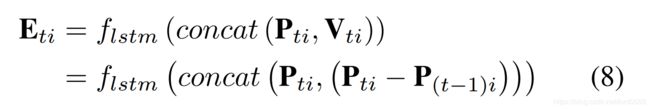
其中,E_ti是t时刻节点i的增强型特征。注意,线性层和LSTM层在不同节点之间共享。
(2) 时序层次结构
在LSTM层之后,增强特征序列{E1,E2, ...,ET} 作为节点特征被输入到接下来的GC-LSTM层,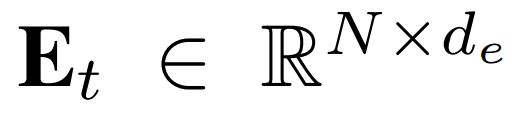 。本文提出的模型将三个AGC-LSTM层放在一起来学习spatial configuration 和 temporal dynamics 。受到CNN的空间池化的启发,本文提出了带有时间域上平均池化的AGC-LSTM的时间分层体系结构,从而使得顶层的AGC-LSTM层的时间感受野增大。通过时间层次结构,在AGC-LSTM顶层上每次输入的时间感受野变成了来自帧的短期clip,使得在时间动态上的感知更为敏感。另一昂面,它能在提升性能的前提下显著地减少计算成本。
。本文提出的模型将三个AGC-LSTM层放在一起来学习spatial configuration 和 temporal dynamics 。受到CNN的空间池化的启发,本文提出了带有时间域上平均池化的AGC-LSTM的时间分层体系结构,从而使得顶层的AGC-LSTM层的时间感受野增大。通过时间层次结构,在AGC-LSTM顶层上每次输入的时间感受野变成了来自帧的短期clip,使得在时间动态上的感知更为敏感。另一昂面,它能在提升性能的前提下显著地减少计算成本。
(3) AGC-LSTM
最后,每一个时间步的全局特征和局部特征转化为C类的总得分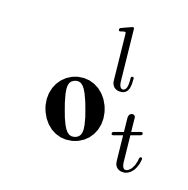 和
和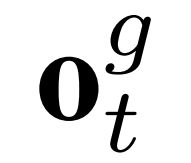 ,其中ot=(ot1, ot2, ..., otC)。
,其中ot=(ot1, ot2, ..., otC)。
然后预测概率作为第i类,然后获得:

在训练的过程中,考虑到顶层AGC-LSTM每个时间步的隐藏态都包含短期动态,使用下面的loss函数来监督模型:
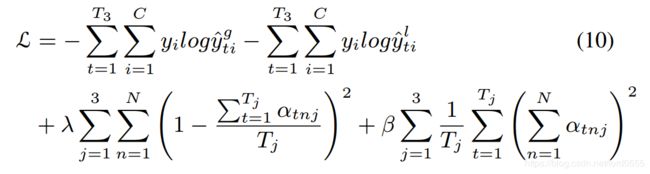
其中,y= (y1, ..., yC) 是真实标签。T_j表示在第j个AGC-LSTM层时间步的数量。第三个时期目的在于给予不同的关节点相同的注意。最后一个时期限制了感兴趣节点的数量。λ和β是权重衰减系数。注意只有最后一个时间步中 和
和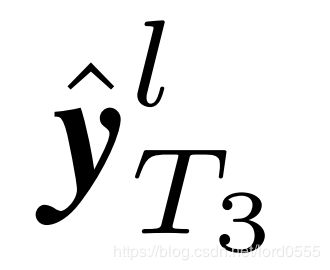 的和的概率才被用来预测人体行为的类别。
的和的概率才被用来预测人体行为的类别。
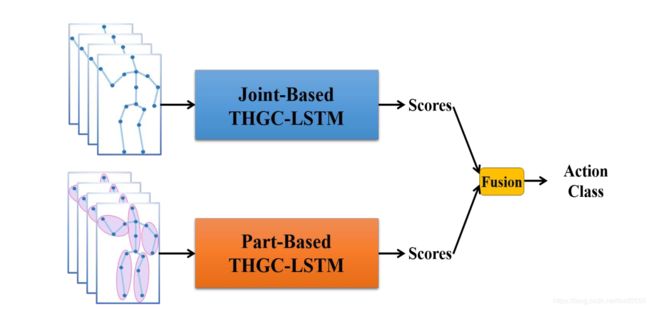
尽管基于联合的AGC-LSTM网络已经获得了最新技术成果,但本文还在零件级别上探索了所提出模型的性能。根据人体的物理结构,身体可以分为分为几个部分。类似于基于联合的AGC-LSTM网络,我们首先捕获具有线性层和共享LSTM层的零件特征。然后将作为节点表示的零件特征输入到三个AGC-LSTM层中以建模时空特性。
结果表明,我们的模型还可以在零件级别上实现出色的性能。此外,基于关节和零件的混合模型可以进一步提高性能。
注:下图为基于联接和零件的混合模型的说明。