学习总结《HOPE-Net: A Graph-based Model for Hand-Object Pose Estimation》
《HOPE-Net: A Graph-based Model for Hand-Object Pose Estimation》
本文提出了轻量HOPE-Net模型,用于在真实2D或3D情况下进行 手-物体姿态识别。
效果图如下:

HOPE-Net采用了两个自适应级联的图卷积网络,一个在2D坐标下去估计手部关节点和物体,另一个图卷积网络将2D坐标转换为3D坐标。
本文提出的网络在2D和3D的姿态识别方面的精确度都有提高。
本文提出的基于图卷积将2D转换到3D已经应用到了很多3D空间下的检测问题上,在该问题中可以先预测2D关节点,然后将2D关节点转换到3D坐标下。
为什么要先进行2D估计在进行3D估计?
因为基于目标检测的模型在2D的手关节点检测中表现更好,而在3D空间下,由于非线性程度高,输出空间大,所以基于回归的模型比较流行。
本文的贡献:
1. 提出了一个轻巧的深度学习框架HOPE-Net,可以实时在2D和3D坐标下预测手和手操纵的物体。该模型能够精准的从单帧RGB图像预测手和物体的姿态。
2. 我们介绍了自适应图U-Net, 他是一个基于图卷积的神经网络通过新颖的图卷积,池化和上采样层将手和物体姿态从2D转换到3D。这些层新的形式使得它相比于已有的图U-Net模型相比更加的稳定和健壮。
3. 通过大量的实验,我们验证了我们的方法在实时运动场景下的手和物体3D姿态估计任务上超越现在最先进的模型。
不能讲手姿态和物体姿态分开预测的原因:当手对一个物体进行某种操作时,手的姿态极大地限制着物体的姿态。所以,手的姿态和物体的姿态之间存在着非常强的关系。
本篇文章的两个研究思路: 级联的手-物体姿态预测模型 和 基于图数据的图卷积网络。
前人做在手-物体姿态估计方面过的研究:
Oikonomidis将 手-物体 交互作为上下文,从而更好的估计多视图图像中的二维手姿态。
Choi 训练了两个网络,一个以物体为中心,另一个以手为中心,以此来抓取物体和手之间的个性信息。在这两个网络中共享信息,以学习更好的表示预测三维手部姿势。
本文提出了一个新的U-Net图结构,它具有不同的图卷积,池化和上采样。我们使用一个自适应的邻接矩阵作为我们的图卷积层和新的可训练的池化层和上采样层。
HOPE-Net网络结构图如下:

在模型的初始部分是一个ResNet10网络结构,它的作用是图像编码器并且进行初始2D坐标下手部节点和物体顶点的预测。它将坐标与用作三层图卷积的输入图的特征的图像特征关联起来,以利用领域的能力来更好的估计2D姿态。最后,将前面步骤中预测得到的二维坐标传递到我们的自适应Graph U-Net 从而得到手和物体的三维坐标。
3.1 图像编码器和图卷积
在图片编码器部分,采用的是一个轻量级残差神经网络(ResNet10)来帮助减少过拟合。这个图像编码器对于每个输入的图像都会输出一个2048D的特征向量。然后使用一个全连接层对2D坐标下的关键点(手的关节和物体紧密边界框的拐角)进行初步的预测。我们将这些特征与每个关键点的初始2D预测连接起来,为每个关键点生成一个包含2050个特征的图(其中2050是2048个图特征加上X和Y的初始估计)。
在该图上附加一个三层的自适应图卷积网络以使用邻接信息并修改关键点的2D坐标。将图像特征和每个关节点预测的X和Y连接起来,使得图卷积网络根据图像特征和二维坐标的初始预测来修改二维坐标。然后将最终得到的手和物体关键点的二维坐标输入到我们的自适应Graph U-Net中,该网络是一个使用自适应卷积,池化和上采样的图卷积网络,它将坐标从2D转化成3D。
3.2 自适应Graph U-Net
这一部分,我们将介绍基于图的模型,它的模型基于预测的二维坐标预测手关节点和物体的三维坐标。
在这个网络中通过在编码部分应用图的池化简化了输入图。在解码器部分,通过上采样层又增加了上一层被简化的节点。类似于经典的U-Net,在每个解码图卷积中,使用跳跃连接和从编码阶段到解码阶段的具体特征。有了这个架构。我们训练一个网络,这个网络将图形简单化以获得手和物体的全局特征,但是也尝试通过在编码器和解码器设置跳跃连接的方式保留本地特征。将HOPE问题建模为一个图有助于使用来预测更精确的坐标,并发现手和对象之间的关系。
本文中提出的网络与传统的U-Net在图卷积,池化和上采样部分有非常大的不同。作者发现sigmoid在pooling层会导致梯度消失,并且无法更新所选择的节点。因此作者采用了一个全连接层去池化节点和更新在图卷积层中的邻接矩阵,将邻接矩阵作为卷积核应用到我们的图中。此外,Gaoet删除了顶点和连接到它们的所有边,并且没有重新连接正在重新维护的顶点的过程。这种方法对于删除节点及其边不会改变图的连通性的密集图可能没有问题,但是在具有稀疏邻接矩阵的图中,假如图是网格或手骨架或身体骨架时,删除一个节点及其边可以将图切割成多个相互独立的子图和破坏连通性是图卷积神经网络最重要的特征。作者认为使用图卷积网络,可以避免这个问题,因为网络在每个池化层之后都会找到结点的连通性。

上图为本文中的自适应Graph U-Net 结构的原理图,它被用来从2D的坐标估计3D坐标。在每个pooling层,大致将节点数减少了一半,在每个上采样层,大致又将节点数增加了一倍。图中的红色箭头跳过了层特征,这些特征被传递给解码器,与上采样特征连接在一起。
3.2.1 图卷积
图卷积网络的核心部分是图卷积的运算部分。本文基于Renormalization Trickmentioned 实现图卷积操作:具有N个节点的输入图的图卷积层的输出特征,K个输入特征,l个输出特征,每个结点的运算操作如下:

σ 代表的是激活函数,W是可训练的权重矩阵,X是输入的特征矩阵,Ã 是图的行归一化邻接矩阵。
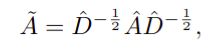
 = A + I 和 Ď 是对角结点度矩阵,Ã可以简单定义为每个结点使用其他结点特征的程度,因此 ÃX 是新的特征矩阵,其中每个节点的特征都是该结点自身和与它相邻接点的平均特征。因此,使用一个有效的邻接矩阵在这个框架中更好的模拟HOPE问题是非常必要的。
这里的邻接矩阵是可以通过训练自动调优的,更像是“亲和力”矩阵,每个结点都可以通过加权边连接到图中的其他结点。而自适应图卷积运算在反向传播步骤中,更新邻接矩阵A以及权重矩阵W,这种方法就能够允许我们去模拟手关节之间没有直接连接的关节点之间的微妙关系(尽管部分关节点之间没有直接连接但是他们之间存在非常强的物理关系)。在网络结构中,将RELU作为图卷积层的激活函数。在实验中作者发现,当这个网络不使用批处理或组规范化时,该网络训练速度相对更快,泛化效果相对更好。
3.2.2 图池化
Sigmod 函数有非常明显的弱点,使用sigmod函数会在pooling反向传播过程中产生非常小的梯度。这样就造成了网络在整个训练阶段无法更新随机初始化选择的pooled nodes,并且失去了可训练池化层的优势。
为了解决上述问题,作者采用了一个全连接层,并将其应用于特征矩阵的转置。这个全连接作为功能的内核,并输出所需数量的结点。这个模块在训练过程中耿欣非常好。由于使用了自适应图卷积,池化过程不会将图分成碎片。