Linux Kernel - read系统调用
系列目录传送门
Linux Kernel - 文件系统系列
read系统调用
文件系统作为连接用户数据和磁盘等块存储设备的中间层, 必须提供数据的读取和写入接口, 而read系统调用就是用来完成数据读取功能的. 在上一篇Linux Kernel - open系统调用中了解到, 通过open系统调用, 内核分配了文件描述符和file文件对象, 并将它们关联起来, 同时把文件描述符返回到应用层, 作为所打开文件的句柄, 方便后续的读写等操作.
多数的场景都具有数据局部性的特征, 当前读取到的数据, 后续可能还会引用到. 因此, 相比读取完就丢弃的做法, 把曾经读取的数据缓存到内存中是个不错的做法, 一旦后续再来读取这些数据的时候, 就可以直接从缓存中获取了. 由于内存的读取速度一般是磁盘的几十倍到上百倍, 因此从缓存的数据中读取将带来很大的速度提升. 因此在内核中, 对于通用文件的读取设计了PageCache模块, 用来缓存曾经读取到的数据.
来看一下读取数据的大致的流程图:

类似于CPU的cache, 当所要的数据位于缓存中时, 直接返回数据. 如果不在缓存中, 则分配Page页面并关联到文件对应的PageCache对象. 然后由具体的文件系统模块把文件内的块偏移转换成所在设备的块号, 并提交到设备的请求队列, 然后同步等待数据读取完成.
这里有个小细节, PageCache对象是和谁关联的? 在open调用中的分析中看到, file对象是每次open的时候都会分配的, 多次打开同一个文件, 则会分配多个file对象. 如果为每个文件分配一个PageCache对象, 当每个file对象都对同一文件位置进行数据读取后, 会造成同一个文件的数据可能以副本的形式存在于不同的PageCache中, 这显然是不合理的. 因此, PageCache对象并不是和每一个文件对应的, 而是和文件的inode对象对应, 对一个文件打开N次, 会分配N个file对象和N个文件描述符, 但是都是对应到一个inode, 共享这个文件的PageCache.
到代码里来看一看, 这是open中调用的一个函数:
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *),
const struct cred *cred)
{
static const struct file_operations empty_fops = {};
int error;
f->f_mode = OPEN_FMODE(f->f_flags) | FMODE_LSEEK |
FMODE_PREAD | FMODE_PWRITE;
path_get(&f->f_path);
//lqp comment: 把inode和PageCache对象关联到文件
f->f_inode = inode;
f->f_mapping = inode->i_mapping;
//lqp comment: ....没错, 其中的inode->i_mapping就是PageCache对象, 名字很奇怪, 对应的数据类型是:
struct address_space *i_mapping;记得之前在看一本介绍内核的书时, 作者也对这个命名表达了一些不满.
Linux Kernel Development 3rd Edition - Robert Love:
Like much else in the Linux kernel, address_space is misnamed.A better name is perhaps page_cache_entity or physical_pages_of_a_file .
作者的建议是叫page_cache_entity或者physical_pages_of_a_file比较好.
总之, 我们了解到这个结构是用来做PageCache的就行了, 简单看看:
struct address_space {
struct inode *host; /* owner: inode, block_device */
struct radix_tree_root page_tree; /* radix tree of all pages */
spinlock_t tree_lock; /* and lock protecting it */
atomic_t i_mmap_writable;/* count VM_SHARED mappings */
struct rb_root i_mmap; /* tree of private and shared mappings */
struct rw_semaphore i_mmap_rwsem; /* protect tree, count, list */
/* Protected by tree_lock together with the radix tree */
unsigned long nrpages; /* number of total pages */
/* number of shadow or DAX exceptional entries */
unsigned long nrexceptional;
pgoff_t writeback_index;/* writeback starts here */
const struct address_space_operations *a_ops; /* methods */
unsigned long flags; /* error bits/gfp mask */
spinlock_t private_lock; /* for use by the address_space */
struct list_head private_list; /* ditto */
void *private_data; /* ditto */
} __attribute__((aligned(sizeof(long))));核心的成员就是page_tree了, 这是一个 radix_tree_root结构, 从名字上来看这就是一个Radix Tree, 其中key是文件内的页面号, value是对应的Page数据页.
最后, 看一看总体的流程图:
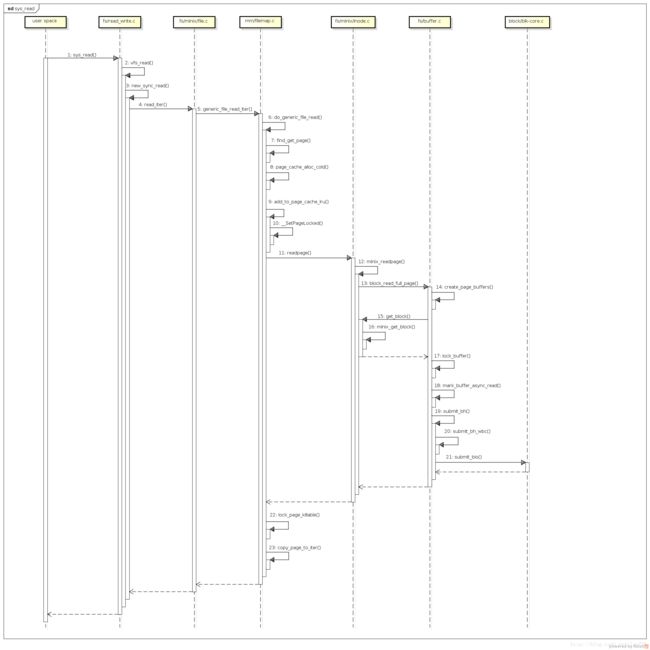
查看大图
在Step 5中, generic_file_read_iter调用的是do_generic_file_read, 从名字上来看是通用的文件读取函数, 有通用就有不通用, 不通用就是绕过PageCache的场景, 就是文件的另一种读取方式, 叫做DirectIO, 这里暂时就不做深入了解了, 有兴趣的同学可以研究一下.
总结
其实很多时候都很懒, 觉得看懂了代码就完事了, 但在这里想表达的一个想法是, 坚持很重要, 把经历过的东西记录下来很重要, 在描述的过程中会理顺并加强很多事情的理解, 不只是提升自己, 还有可能帮助到别人. 希望自己能坚持!