python实现淘宝用户行为数据分析
数据来源:阿里云天池
由于篇幅太长,数据清洗过程移至python实现淘宝用户行为分析——数据清洗
本文将分别进行流量指标分析、用户行为时间模式分析、用户流失分析、用户价值分析和商品销售分析
流量指标分析
(1)PV. UV. PV/UV
pv:访问量,这里可用用户的点击行为来衡量;uv:独立访客。
pv/uv表示单位uv带来的页面访问量,该比值可作为反映页面访问质量的一个指标。
behavior_count=data.groupby('行为类型')['用户ID'].count()
PV=behavior_count['pv']
print("PV=%d"%PV)
UV=len(data['用户ID'].unique())
print("UV=%d"%UV)
print("平均访问量 PV/UV=%d"%(PV/UV))PV=7156257
UV=78216
平均访问量 PV/UV=91
(2)跳失率
跳失率:只有点击行为的用户数/总用户数,总用户数即uv
data_pv=data.loc[data['行为类型']=='pv',['用户ID']]
data_fav=data.loc[data['行为类型']=='fav',['用户ID']]
data_cart=data.loc[data['行为类型']=='cart',['用户ID']]
data_buy=data.loc[data['行为类型']=='buy',['用户ID']]
#集合相减,获取只有点击行为的用户数
data_pv_only=set(data_pv['用户ID'])-set(data_fav['用户ID'])-set(data_cart['用户ID'])-set(data_buy['用户ID'])
pv_only=len(data_pv_only)
print('跳失率为:%.2f%%'%(pv_only/UV*100))跳失率为:5.75%
分析:跳失率为5.75%,数值看上去较小,但跳失率一定程度上反映了商品的受欢迎程度,最好还是结合行业数据和以往数据分析是否处于正常范围。
影响跳失率的相关因素有:商品吸引力、商品加载时长以及流量的质量等。
用户行为分析
(1)日PV、日UV
pv_daily=data_pv.groupby('星期')['用户ID'].count().reset_index().rename(columns={'用户ID':'日pv'})
uv_daily=data.groupby('星期')['用户ID'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'用户ID':'日uv'})
arams['font.sans-serif'] = 'Microsoft YaHei'
plt.rcParams['axes.unicode_minus'] = False
#折线图绘制
fig = plt.figure(figsize=(6,6))
plt.subplot(2,1,1)
xlabel=pv_daily['星期'].tolist()
plt.plot(range(len(xlabel)),pv_daily.日pv)
plt.xticks(np.arange(9),'')
plt.title('日点击量趋势图')
plt.ylabel('日pv')
for a,b in zip(range(len(xlabel)),pv_daily.日pv):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.subplot(2,1,2)
plt.plot(range(len(xlabel)),uv_daily.日uv)
plt.xticks(np.arange(9),('11-25 周六','11-26 周日','11-27 周一','11-28 周二','11-29 周三','11-30 周四','12-01 周五','12-02 周六','12-03 周日'),rotation=45)
plt.title('日独立访客数趋势图')
plt.ylabel('日uv')
for a,b in zip(range(len(xlabel)),uv_daily.日uv):
plt.text(a, b, b, ha='center', va='bottom', fontsize=10)
plt.show()
分析:(1)从日pv折线图可以看出: 用户点击行为的基本规律是周末的点击量高于工作日,而在工作日中,周一和周二相对而言点击量较少,周三、周四、周五的点击量则保持稳步上升的趋势。这与大部分人群的工作休息时间相符,主要原因在于人们在周末有更多的闲暇时间刷淘宝进行网购,到了周一周二工作开始忙碌分散了诸多精力或者人们在经过周末网购之后出现短暂购买力下降的现象。总体趋势是健康的。
(2)12月2日和12月3日这个周末的点击量陡增,而上周末并未出现如此情况,同时结合uv曲线图,从11月25日至12月1日,uv平稳中有些许上升,而在2、3日大幅上涨,怀疑“双十二”活动预热,核实业务部门是否在这个周末做了促销活动,这样,pv的陡增也就不难解释了。如果有更长时间的数据可以得到更准确的推测。
(2)时PV、时UV
#按小时的访问量
pv_hour=data.groupby('时间点')['用户ID'].count().reset_index().rename(columns={'用户ID':'时pv'})
uv_hour=data.groupby('时间点')['用户ID'].apply(lambda x:x.drop_duplicates().count()).reset_index().rename(columns={'用户ID':'时uv'})
fig,axes=plt.subplots(2,1,sharex=True)
pv_hour.plot(x='时间点',y='时pv',ax=axes[0])
uv_hour.plot(x='时间点',y='时uv',ax=axes[1])
plt.xticks(range(24),np.arange(24))
axes[0].set_title('按小时点击量趋势图')
axes[1].set_title('按小时独立访客数趋势图')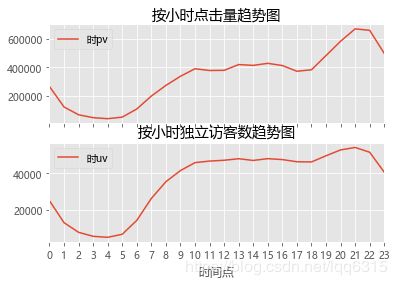
分析:由图可知,每天凌晨0点至8点是点击量最少的时间,同时也是访问用户数最少的时间;
其中在凌晨4点点击量和方可量达到最低,这段时间是人们的睡眠时间;
5点到10点访问量逐渐增加,是人们纷纷起床的时间;
从10点到18点点击量稳定,是人们白天工作或学习的时间,其中17、18点相对来说出现小幅下降,可能因为人们在吃饭或者下班通勤不能购物;
从18点开始用户数与点击量大幅上升,是人们下班在家休息的时间,21、22点是一天的黄金时段,人们上网购物的最高峰,平台商家可以抓住这个时间段进行营销,比如推送通知、优惠券活动、直播活动等,因为这个时间在线人数最多,23点开始有所下滑,人们纷纷休息。所以平台上新或者开展活动时间最好根据用户行为习惯,选择20点至23点之间的流量高峰期。
用户流失分析——AARRR漏斗模型
data_AARRR=data.groupby('行为类型')['用户ID'].count()
#点击量
pv_value=data_AARRR['pv']
#收藏量
fav_value=data_AARRR['fav']
#加购量
cart_value=data_AARRR['cart']
#购买量
buy_value=data_AARRR['buy']
##计算转化率,此处由于实际业务中用户收藏和加购没有先后顺序,所以二者合并后计算转化率
#收藏加购转化率
f_c_value=fav_value+cart_value
f_c_ratio=f_c_value/pv_value
print('收藏加购转化率为:%.2f%%'%(f_c_ratio*100))
#购买转化率
buy_ratio=buy_value/pv_value
print('购买转化率为:%.2f%%'%(buy_ratio*100))收藏加购转化率为:9.50%
购买转化率为:2.23%
#使用pyechart的funnel绘制漏斗图
m=['点击','收藏加购','购买']
n=[1,0.0950,0.0223]
funnel=(Funnel(init_opts = opts.InitOpts(width="500px",height="400px"))
.add("转化率",[list(z) for z in zip(m,n)],label_opts=opts.LabelOpts(position="inside"))
.set_global_opts(title_opts=opts.TitleOpts(title="用户转化漏斗图")) )
funnel.render_notebook()
分析:用户行为包括点击、放进购物车、收藏以及购买,在用户点击之后,收藏或放进购物车的占9.5%,最后实际购买的只占2.23%,购买转化率是有提高空间的,用户既然加入了购物车,表示他对这个商品有需求、有兴趣,可能是在货比三家或者等待促销活动,或者因为外部条件限制暂时不能购买,商家可以通过推送、直播活动等让用户更加了解商品,从而坚定购买意愿;发送优惠券、其他打折方式来吸引消费者购买;定期推送购物车中商品提醒消费者购买。
用户价值分析
(1)复购率
复购指两天以上有购买行为,一天多次购买算一次,复购率=有复购行为的用户数/有购买行为的用户总数
#计算有复购行为的用户数
user_rebuy=data[data['行为类型']=='buy'].groupby('用户ID')['日期'].apply(lambda x:len(x.unique())).rename('复购次数')
user_rebuy_count=user_rebuy[user_rebuy>=2].count()
#有购买行为的用户总数
user_buy_count=user_rebuy.count()
print('复购率为:%.2f%%'%(user_rebuy_count/user_buy_count*100))复购率为:54.96%
sns.distplot(user_rebuy-1)
plt.show()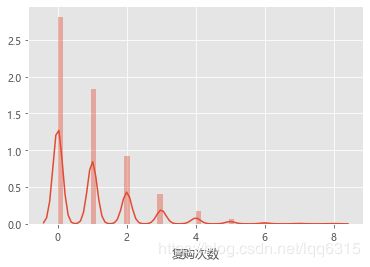
分析:上图表明多数用户复购次数为0;9天的复购率为54.96%。淘宝的市场份额一直稳居前列,用户量足够庞大,在淘宝下沉扩展获取新用户的同时,提高复购率应是更重要的事情。购买一次可能是被吸睛的标题、精美的图片或是诱人的营销活动吸引,而复购就要求产品质量过关、服务到位,消费者对第一次的购物体验很满意才会进行第二次,所以淘宝可以重点在这些方面帮助商家
(2)用户价值分层——RFM模型
依据RFM模型进行用户价值度分类,由于此数据集不包含订单金额,故只分析R、F维度
data_RFM=data.loc[data['行为类型']=='buy',['用户ID','行为类型','日期']]
#数据子集中最大的日期
max_date=data['日期'].max()
#计算消费间隔 (数据集中最大日期-消费日期)
data_RFM['日期']=pd.to_datetime(data_RFM['日期'])
data_RFM['消费间隔']=(pd.to_datetime(max_date)+datetime.timedelta(days=1)-data_RFM['日期']).dt.days
data_RFM.head()
index='消费间隔',aggfunc='count')
consum=consum.rename(columns={'用户ID':'人数'}).reset_index()
consum| 消费间隔 | 人数 | |
|---|---|---|
| 0 | 1 | 20506 |
| 1 | 2 | 20710 |
| 2 | 3 | 16726 |
| 3 | 4 | 17557 |
| 4 | 5 | 17532 |
| 5 | 6 | 16693 |
| 6 | 7 | 17737 |
| 7 | 8 | 16150 |
| 8 | 9 | 15844 |
#matplotlib库绘制垂直条形图
plt.bar(range(9),consum.人数,align='center',color='steelblue',alpha=0.8)
plt.ylabel('人数')
plt.xlabel('消费间隔天数')
plt.title('用户消费间隔天数统计')
plt.xticks(range(9),np.arange(9)+1)
plt.ylim([15000,25000])
for x,y in enumerate(consum.人数):
plt.text(x,y+100,'%s'%round(y,1),ha='center',fontsize=10)
plt.show()
分析:由结果可见,9天之中,大部分人都在当天或隔天就再次购买,可以看出淘宝已经成为人们的日常购物习惯。
#建立R、F指标 ,其中r值为数据集中最大日期-最近一次消费时间,即消费间隔的最小值
R=data_RFM.groupby(by=['用户ID'])['消费间隔'].aggregate([('R','min')])
F=data_RFM.groupby(by=['用户ID'])['用户ID'].aggregate([('F','count')])
rfm=R.join(F)
rfm.head()
#rfm.corr() #相关性分析| R | F | |
|---|---|---|
| 用户ID | ||
| 100 | 6 | 8 |
| 1000001 | 1 | 1 |
| 1000011 | 9 | 2 |
| 100002 | 4 | 1 |
| 1000027 | 1 | 2 |
下一步对指标进行分级,一般对R、F分别使用五分位(也可以分成其他分位)法做数据分区,需要注意的是,对于R来讲需要倒过来划分,离截止时间越近的值划分越大。
#计算R_score
bins=rfm.R.quantile(q=np.linspace(0,1,num=6),interpolation='nearest')
bins[0]=0
R_score=pd.cut(rfm.R,bins,labels=[5,4,3,2,1])
rfm['R_score']=R_score
#计算F_score
bins=rfm.F.quantile(q=np.linspace(0,1,num=6),interpolation='nearest')
bins[0]=0
F_score=pd.cut(rfm.F,bins,labels=[5,4,3,2,1])
rfm['F_score']=F_score
rfm.head()
#根据实际业务情况衡量R和F的重要性,这里我采用加权方式计算最终RFM得分,R:F=2:3
rfm['RF_score'] =0.4*R_score.astype(int) + 0.6*F_score.astype(int)
#按照最终RF得分画箱线图观察分布
plt.boxplot(x=rfm.RF_score)
plt.show()
根据图示,按照RF得分的四分位数将用户划分为四类——‘易流失用户’,‘挽留用户’,‘发展用户’,‘忠诚用户’
bins=rfm.RF_score.quantile(q=np.linspace(0,1,num=5),interpolation='nearest')
bins[0]=0
customer_label=pd.cut(rfm.RF_score,bins,labels=['易流失用户','挽留用户','发展用户','忠诚用户'])
rfm['用户标签']=customer_label
rfm.head()| R | F | R_score | F_score | RF_score | 用户标签 | |
|---|---|---|---|---|---|---|
| 用户ID | ||||||
| 100 | 6 | 8 | 2 | 1 | 1.4 | 易流失用户 |
| 1000001 | 1 | 1 | 5 | 5 | 5.0 | 忠诚用户 |
| 1000011 | 9 | 2 | 1 | 4 | 2.8 | 挽留用户 |
| 100002 | 4 | 1 | 3 | 5 | 4.2 | 忠诚用户 |
| 1000027 | 1 | 2 | 5 | 4 | 4.4 | 忠诚用户 |
#数据透视表
label_count=rfm.reset_index()
label_count=label_count.pivot_table('用户ID',index='用户标签',aggfunc='count')
label_count=label_count.rename(columns={'用户ID':'人数'}).reset_index()
#绘图
plt.bar(range(4),label_count.人数,align='center',color='steelblue',alpha=0.8) plt.ylabel('人数')
plt.xlabel('用户标签')
plt.title('RFM用户价值分层人数统计')
plt.xticks(range(4),['易流失用户','挽留用户','发展用户','忠诚用户'])
plt.ylim([10000,18000])
for x,y in enumerate(label_count.人数):
plt.text(x,y+100,'%s'%round(y,1),ha='center',fontsize=10)
plt.show()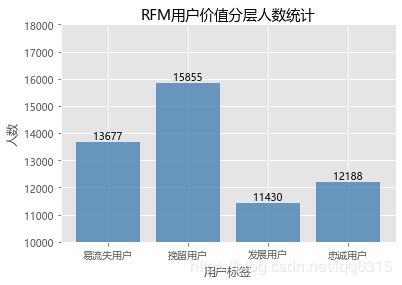
分析:重点挽留用户的比例最高,而且这部分客户给平台带来的潜在价值也很大,应该对这部分用户发送提醒或促销活动邮件、促进其购买频次;易流失用户占比也相当高,这部分客户可能已经找到替代品或对该公司产品不感兴趣了,可适当进行价格激励进行流失召回;其次是忠诚用户,这部分用户也是高价值用户,无需特别激励措施;最后是重点发展用户,对这部分用户进行定期上新提醒、价格激励、订单搭配推荐等措施重点提高其消费频次。
商品销售分析
关于“受欢迎”的产品,有的人理解是点击量高,有的人理解是销量高,但有的点击量高的产品可能是因为被页面或广告等吸引而来,或者只是感兴趣,用户并不一定会购买;而销量高的产品有可能是用户真正需要的,搜索和点击购买的目标也比较明确。衡量商品的市场情况,最好同时分析点击量和购买量。再者,按商品类目分析各环节转化率;最后,验证电商环境中的长尾理论。
(1)销售排行榜前十
#购买产品类目计数
product_buy=data.loc[data['行为类型']=='buy',['用户ID','商品类目ID']]
product_buy_count=product_buy.groupby('商品类目ID')['用户ID'].count().rename('销售次数')
#转换为数据框,按列排序
product_buy_count=pd.DataFrame(product_buy_count)
#按照销售次数降序排序
product_buy_count=product_buy_count.sort_values(by='销售次数',axis=0,ascending = False)
#购买产品类目前10名
product_buy_count=product_buy_count.iloc[:10,:]
product_buy_count| 销售次数 | |
|---|---|
| 商品类目ID | |
| 2735466 | 2888 |
| 1464116 | 2873 |
| 4145813 | 2686 |
| 2885642 | 2484 |
| 4756105 | 2389 |
| 4801426 | 2133 |
| 982926 | 1979 |
| 2640118 | 1418 |
| 3002561 | 1376 |
| 4357323 | 1372 |
(2)点击排行榜前十
#点击产品计数
product_pv=data.loc[data['行为类型']=='pv',['用户ID','商品类目ID']]
product_pv_count=product_pv.groupby('商品类目ID')['用户ID'].count().rename('点击次数')
product_pv_count=pd.DataFrame(product_pv_count)
product_pv_count=product_pv_count.sort_values(by='点击次数',axis=0,ascending = False)
product_pv_count=product_pv_count.iloc[:10,:]
product_pv_count| 点击次数 | |
|---|---|
| 商品类目ID | |
| 4756105 | 389260 |
| 4145813 | 261650 |
| 2355072 | 254362 |
| 3607361 | 235621 |
| 982926 | 229527 |
| 2520377 | 160544 |
| 4801426 | 151448 |
| 1320293 | 141739 |
| 2465336 | 125108 |
| 3002561 | 115695 |
#将点击量前十和购买量前十商品类目连接
top=pd.concat([product_buy_count,product_pv_count],axis=1,sort=False)
top| 销售次数 | 点击次数 | |
|---|---|---|
| 2735466 | 2888.0 | NaN |
| 1464116 | 2873.0 | NaN |
| 4145813 | 2686.0 | 261650.0 |
| 2885642 | 2484.0 | NaN |
| 4756105 | 2389.0 | 389260.0 |
| 4801426 | 2133.0 | 151448.0 |
| 982926 | 1979.0 | 229527.0 |
| 2640118 | 1418.0 | NaN |
| 3002561 | 1376.0 | 115695.0 |
| 4357323 | 1372.0 | NaN |
| 2355072 | NaN | 254362.0 |
| 3607361 | NaN | 235621.0 |
| 2520377 | NaN | 160544.0 |
| 1320293 | NaN | 141739.0 |
| 2465336 | NaN | 125108.0 |
分析:上表是点击量前十和购买量前十商品类目分别对应的点击量和购买量,并将两个结果连接,发现有五类商品点击量和购买量都是前十,其他类商品只是一方面突出,我们可以将所有商品按照此种性质分为三类。
A类:包括五个类目,点击量和购买量都是前十,说明是很受用户欢迎的商品种类。电商平台应该重点推送A类中的商品,因为这类商品有市场,并且可以多做活动,吸引更多的潜在客户变成购买客户。
B类:包括五个类目,这类商品购买量较高,但点击量不突出。这类商品也许是特定群体非常需要的,他们可能搜索和点击的目标比较明确。电商平台可以收集用户信息,分析用户画像,结合商品特点,核实是否如此。如果是某类特征明显的用户群体购买更多,可以集中向该类用户多推送。如果没有明显的群体需求,建议对这类商品多做推广,因为原有的购买量比较高,若是能够提高点击量,可能购买量也会再上一个台阶。
C类:包括五个类目,这类商品虽然点击量很高,但购买量偏低。对这类商品,应该先从商品本身分析,是否是用户真正需要的?为什么大部分用户点击,但购买较少,是因为价格太高?还是其他原因?调查清楚原因之后再对症下药。
(3)按商品类目的转化率分析
#商品购买次数和种类统计图
item_behavior=data.groupby(['商品类目ID','行为类型'])['用户ID'].count().unstack(1).rename(columns={'pv':'点击量','fav':'收藏量','cart':'加购量','buy':'购买量'}).fillna(0)
item_behavior.head()
item_behavior['转化率']=item_behavior['购买量']/item_behavior['点击量']
item_behavior.head()| 行为类型 | 购买量 | 加购量 | 收藏量 | 点击量 | 转化率 |
|---|---|---|---|---|---|
| 商品类目ID | |||||
| 1000858 | 1.0 | 2.0 | 0.0 | 10.0 | 0.1 |
| 1000959 | 0.0 | 3.0 | 1.0 | 109.0 | 0.0 |
| 1001152 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1002057 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 1003418 | 0.0 | 0.0 | 1.0 | 5.0 | 0.0 |
#异常值处理
item_behavior=item_behavior.fillna(0)
item_behavior=item_behavior[item_behavior['转化率']<=1]
sns.distplot(item_behavior[item_behavior['转化率']>0]['转化率'],kde=False)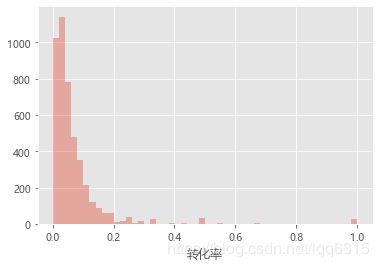
分析:图表显示,基本上各类商品大部分用户转化率在0.1以内,绝大多数用户都没有购买情况,需要重点关注出现该现象的原因进行分析改进。
下面分析用户加购的比率,用户既然进行加购行为,说明用户对商品还是感兴趣的,我们也可以将其定义为感兴趣比率,通过分析用户是否感兴趣进一步探讨购买转化率如此低的原因。
item_behavior['感兴趣比率']=item_behavior['加购量']/item_behavior['点击量']
item_behavior.head()| 行为类型 | 购买量 | 加购量 | 收藏量 | 点击量 | 转化率 | 感兴趣比率 |
|---|---|---|---|---|---|---|
| 商品类目ID | ||||||
| 1000858 | 1.0 | 2.0 | 0.0 | 10.0 | 0.1 | 0.200000 |
| 1000959 | 0.0 | 3.0 | 1.0 | 109.0 | 0.0 | 0.027523 |
| 1001152 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.000000 |
| 1002057 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.000000 |
| 1003418 | 0.0 | 0.0 | 1.0 | 5.0 | 0.0 | 0.000000 |
#异常值处理,感兴趣比率绘图
item_behavior=item_behavior[item_behavior['感兴趣比率']<=1]
sns.distplot(item_behavior[item_behavior['感兴趣比率']>0]['感兴趣比率'],kde=False)
分析:感兴趣率和转化率类似,基本也是0.1以内,说明用户点击的绝大多数商品并非感兴趣,建议平台需要重视推荐系统的调整。
(4)长尾理论or二八定律
item_behavior=item_behavior[item_behavior['购买量']>0]
up=item_behavior['购买量'].sum()*0.8
item_behavior=item_behavior.sort_values(by='购买量',ascending=False)
item_behavior['累计购买量']=item_behavior['购买量'].cumsum()
item_behavior['分类']=item_behavior['累计购买量'].map(lambda x:'前80%' if x<=up else '后20%')
item_behavior.head()| 行为类型 | 购买量 | 加购量 | 收藏量 | 点击量 | 转化率 | 感兴趣比率 | 累计购买量 | 分类 |
|---|---|---|---|---|---|---|---|---|
| 商品类目ID | ||||||||
| 2735466 | 2888.0 | 7913.0 | 3011.0 | 91963.0 | 0.031404 | 0.086045 | 2888.0 | 前80% |
| 1464116 | 2873.0 | 5063.0 | 2219.0 | 57084.0 | 0.050329 | 0.088694 | 5761.0 | 前80% |
| 4145813 | 2686.0 | 14551.0 | 9124.0 | 261650.0 | 0.010266 | 0.055612 | 8447.0 | 前80% |
| 2885642 | 2484.0 | 4614.0 | 2587.0 | 76569.0 | 0.032441 | 0.060259 | 10931.0 | 前80% |
| 4756105 | 2389.0 | 18918.0 | 12046.0 | 389260.0 | 0.006137 | 0.048600 | 13320.0 | 前80% |
item_behavior.groupby('分类')['分类'].count()/item_behavior['分类'].count()分类
前80% 0.142382
后20% 0.857618
Name: 分类, dtype: float64
由此可见,前80%销量有14%左右的商品品类提供,后20%的销量由85%左右的商品品类提供,接近二八原则。