Python学习笔记:面向对象编程
Python学习笔记:面向对象编程
学自廖雪峰巨佬的Python3教程:https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000/0014318645694388f1f10473d7f416e9291616be8367ab5000
1.在Python中,所有数据类型都可以视为对象,自定义的对象数据类型就是面向对象中的类(class)的概念,对象有属性和方法。定义类是通过class关键字,class后面紧跟类名,即Student,类名通常是大写开头的单词,紧接着是(object),表示是从哪个类继承下来的,如果没有合适的继承类,就使用object万类之王。定义好了Student类,就可以实例化对象。
class Student(object):
pass
>>> bart = Student()
>>> bart
<__main__.Student object at 0x10a67a590>
>>> Student
可以看到at后面跟的是内存地址
可以自由的给一个实例变量绑定属性,也可以在创建实例的时候,通过__init__把一些我们认为必须绑定的属性强制填写进去(类似于java里的构造方法),注意__init__方法的第一个参数永远是self,表示创建的实例本身,因此在__init__方法内部,就可以把各种属性绑定到self,因为self指向实例本身
>>> bart.name = 'Bart Simpson'
>>> bart.name
'Bart Simpson'
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
>>> bart = Student('Bart Simpson', 59)
>>> bart.name
'Bart Simpson'
>>> bart.score
59面向对象编程的一个重要特点就是数据封装,可以把属性和方法封装在类的内部,如访问数据的函数。封装是为了易于调用,同时隐藏内部实现细节,还有另一个好处就是
class Student(object):
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))2.如果要让内部属性不被外部访问,可以把属性的名称前加上两个下划线,在Python中,实例的变量名如果以__开头,就变成了一个私有变量,只有内部可以访问,外部不能访问
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def print_score(self):
print('%s: %s' % (self.__name, self.__score))现在已经无法使用实例变量.__name的方式来访问name属性了,这样就确保了外部代码不能随意修改对象内部的状态,这样通过访问限制的保护,代码更加健壮。
如果外部代码要获取和设置这name属性,可以加上getter和setter方法,而且在这两个方法中还可以对参数做检查,避免传入无效的参数:
class Student(object):
...
def set_score(self, score):
if 0 <= score <= 100:
self.__score = score
else:
raise ValueError('bad score')双下划线开头、双下划线结尾的变量是Python的特殊变量,是可以直接访问的,不是private变量,因此不能使用这样的变量名。
本质上也不是没有办法从外部访问内部私有变量,可以用_类名__私有变量名的方式来访问,但是,别做坏事好吧
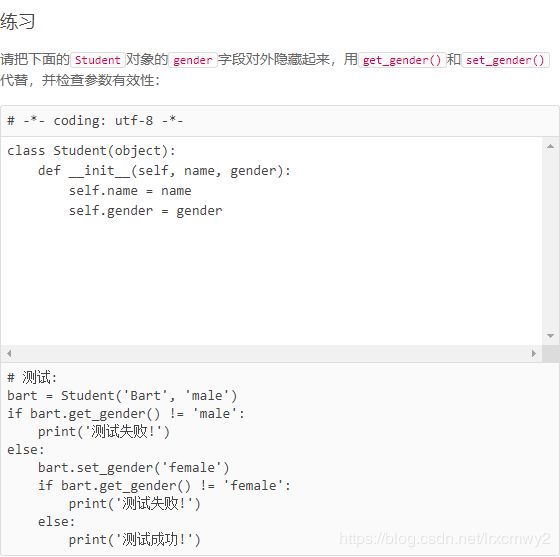
代码如下:
class Student(object):
def __init__(self, name, gender):
self.__name = name
self.__gender = gender
def get_gender(self):
return self.__gender
def set_gender(self, gender):
self.__gender = gender3.当定义一个class的时候,可以从某个现有的class继承,新的class称为子类,而被继承的class称为基类、父类或超类。子类会获得父类的全部方法,可以对子类增加方法,可以override父类的方法(实现多态)。
在继承关系中,如果一个实例的数据类型是某个子类,那它的数据类型也可以被看做是父类,但是反过来就不行
要理解多态的好处,可以看这么个例子
def run_twice(animal):
animal.run()
animal.run()
>>> run_twice(Animal())
Animal is running...
Animal is running...
>>> run_twice(Dog())
Dog is running...
Dog is running...
>>> run_twice(Cat())
Cat is running...
Cat is running...会发现,新增一个Animal的子类,不必对run_twice()做任何修改,实际上,任何依赖父类Animal作为参数的函数或方法都可以不加修改的正常运行,当传入Dog、Cat、Tortoise时,只需要接收Animal类型就可以了,由于Animal类型有run()方法,因此传入的任意类型只要是Animal类或子类,就会自动调用实际类型的run()方法
开闭原则:对扩展开放,允许新增Animal子类;对修改封闭:不需要修改依赖Animal类型的run_twice等函数
对于静态语言(例如Java)来说,如果需要传入Animal类型,则传入的对象必须是Animal类型或者它的子类,否则将无法调用run()方法;但对于Python这样的动态语言来说,则不一定需要传入Animal类型,我们只需要保证传入的对象有一个run()方法就可以了,这就是动态语言的鸭子类型,它并不要求严格的继承体系,一个对象只要“看起来像鸭子,走起路来像鸭子”,那它就可以被看做是鸭子。
Python的“file-like object“就是一种鸭子类型。对真正的文件对象,它有一个read()方法,返回其内容。但是,许多对象,只要有read()方法,都被视为“file-like object“。许多函数接收的参数就是“file-like object“,你不一定要传入真正的文件对象,完全可以传入任何实现了read()方法的对象。
4.一般来说,可以使用type()函数来判断基本类型,还可以判断指向函数或类的变量,但如果要判断一个对象是否是函数,则需要使用types模块中定义的常量
>>> import types
>>> def fn():
... pass
...
>>> type(fn)==types.FunctionType
True
>>> type(abs)==types.BuiltinFunctionType
True
>>> type(lambda x: x)==types.LambdaType
True
>>> type((x for x in range(10)))==types.GeneratorType
True对于class的继承关系来说,使用type()就很不方便,因此可以使用isinstance()函数,参数为isinstance(var_name,calss_name),能用type()判断的基本类型也可以用isinstance()判断,因此优先使用后者
使用dir()函数可以获得一个对象的所有属性和方法,它返回一个包含字符串的list,如果我们自己写的类也想用len()方法的话,就在类里写一个__len__方法就可以了,getattr(obj,property)用于获取对象属性和方法,还可以把获取到的熟悉感和方法赋值给变量;setattr(obj,property,value)用于设置对象属性;hasattr(obj,property)用于判断对象是否拥有某个属性或方法
>>> hasattr(obj, 'x') # 有属性'x'吗?
True
>>> obj.x
9
>>> hasattr(obj, 'y') # 有属性'y'吗?
False
>>> setattr(obj, 'y', 19) # 设置一个属性'y'
>>> hasattr(obj, 'y') # 有属性'y'吗?
True
>>> getattr(obj, 'y') # 获取属性'y'
19
>>> obj.y # 获取属性'y'
195.由于Python是动态语言,根据类创建你的实例可以任意绑定属性。如果Student类本身需要绑定一个属性呢?可以直接在class中定义属性,这种属性是类属性,归Student类所有,但类的所有实例都可以访问到。
>>> class Student(object):
... name = 'Student'
...
>>> s = Student() # 创建实例s
>>> print(s.name) # 打印name属性,因为实例并没有name属性,所以会继续查找class的name属性
Student
>>> print(Student.name) # 打印类的name属性
Student
>>> s.name = 'Michael' # 给实例绑定name属性
>>> print(s.name) # 由于实例属性优先级比类属性高,因此,它会屏蔽掉类的name属性
Michael
>>> print(Student.name) # 但是类属性并未消失,用Student.name仍然可以访问
Student
>>> del s.name # 如果删除实例的name属性
>>> print(s.name) # 再次调用s.name,由于实例的name属性没有找到,类的name属性就显示出来了
Student从上面的例子可以看出,在编写程序的时候,千万不要对实例属性和类属性使用相同的名字,因为相同名称的实例属性将屏蔽掉类属性,但是当你删除实例属性后,再使用相同的名称,访问到的将是类属性。
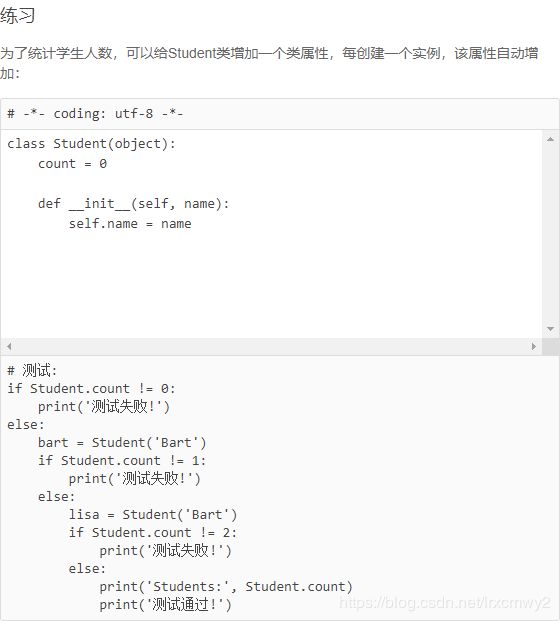
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
class Student(object):
count = 0
def __init__(self, name):
self.__name = name
Student.count += 1
# 测试:
if Student.count != 0:
print('测试失败!')
else:
bart = Student('Bart')
if Student.count != 1:
print('测试失败!')
else:
lisa = Student('Bart')
if Student.count != 2:
print('测试失败!')
else:
print('Students:', Student.count)
print('测试通过!')