前言
最近在看sentinel的一些资料和代码,github请参见这个网址,看过代码之后感觉sentinel在限流熔断上相较于Hystrix可能会更好一点,一方面是他没有用多余的线程池,通过滚动数组来记录了当前流量来完成限流逻辑,比Hystrix完全通过并发线程数来限流功能更好一点,另外一方面是他没有用RxJava来完成自己的逻辑,从代码阅读上门槛低了不少,并且通过类似于责任链模式形成了一个slot的chain,即提升了代码的可读性也增强了可扩展性。示意图如下(转自github):

本文作为Sentinel学习系列第一篇文章需要分析的代码针对的是流量统计相关,对应于上图是存在于StatisticSlot中。
流量统计
本来第一篇文章应该从TreeNode这个Slot开始,但是确实我目前现在对于Sentinel中Context和Node的具体关系没有特别理清,所以就先直接跳过直接到了流量统计这一块来了。对于这一块需要知道的背景知识的话可能就是一个Node代表的就是请求的一个资源,在StatisticSlot中针对某一个Node通过滚动数组算法来计算他的流量。这也跟前言中的图一致。
代码结构
首先得称赞一句阿里的代码组织非常好,这是通过github clone下来的项目截图,红框中就是我们需要关注的流量统计相关代码的所在了:

StatisticSlot 入口
StatisticSlot 代码如下:
/**
*
* A processor slot that dedicates to real time statistics.
* When entering this slot, we need to separately count the following
* information:
*
* - {@link ClusterNode}: total statistics of a cluster node of the resource id
* - origin node: statistics of a cluster node from different callers/origins.
* - {@link DefaultNode}: statistics for specific resource name in the specific context.
*
- Finally, the sum statistics of all entrances.
*
*
*
* @author jialiang.linjl
* @author Eric Zhao
*/
public class StatisticSlot extends AbstractLinkedProcessorSlot {
/**
* StatisticSlot在责任链中的调用入口
* 在demo中调用SphO.entry进入获取token逻辑
* 通过前面的Slot后到达这里
* @param context current {@link Context}
* @param resourceWrapper current resource
* @param node resource node
* @param count tokens needed
* @param args parameters of the original call
* @throws Throwable
*/
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, DefaultNode node, int count, Object... args)
throws Throwable {
try {
// 直接出发下游的slot entry操作
fireEntry(context, resourceWrapper, node, count, args);
// 如果到达这里说明获取token成功,可以继续操作
// 首先增加访问资源的并发线程数
node.increaseThreadNum();
// 在增加当前秒钟pass的请求数
node.addPassRequest();
// 如果在调用entry之前指定了调用的origin,即调用方
if (context.getCurEntry().getOriginNode() != null) {
// 则会有一个originNode,我们也需要做上面两个增加操作
// 方便针对调用方的统计,为后续的限流做准备
context.getCurEntry().getOriginNode().increaseThreadNum();
context.getCurEntry().getOriginNode().addPassRequest();
}
// 这里应该是一个全局的统计吧
if (resourceWrapper.getType() == EntryType.IN) {
Constants.ENTRY_NODE.increaseThreadNum();
Constants.ENTRY_NODE.addPassRequest();
}
// 这里我没过多关注了
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onPass(context, resourceWrapper, node, count, args);
}
} catch (BlockException e) {
context.getCurEntry().setError(e);
// 如果触发了BlockException,则说明获取token失败,被限流
// 因此增加当前秒Block的请求数
// Add block count.
node.increaseBlockQps();
//这里是针对调用方origin的统计
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseBlockQps();
}
if (resourceWrapper.getType() == EntryType.IN) {
Constants.ENTRY_NODE.increaseBlockQps();
}
for (ProcessorSlotEntryCallback handler : StatisticSlotCallbackRegistry.getEntryCallbacks()) {
handler.onBlocked(e, context, resourceWrapper, node, count, args);
}
throw e;
} catch (Throwable e) {
context.getCurEntry().setError(e);
// 如果触发了exception
// 增加这个请求当前秒Exception的数目
// Should not happen
node.increaseExceptionQps();
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().increaseExceptionQps();
}
if (resourceWrapper.getType() == EntryType.IN) {
Constants.ENTRY_NODE.increaseExceptionQps();
}
throw e;
}
}
/**
* 在demo中调用SphO.exit进入获取token逻辑
* 通过前面的Slot后到达这里
* @param context current {@link Context}
* @param resourceWrapper current resource
* @param count tokens needed
* @param args parameters of the original call
*/
@Override
public void exit(Context context, ResourceWrapper resourceWrapper, int count, Object... args) {
DefaultNode node = (DefaultNode)context.getCurNode();
if (context.getCurEntry().getError() == null) {
long rt = TimeUtil.currentTimeMillis() - context.getCurEntry().getCreateTime();
if (rt > Constants.TIME_DROP_VALVE) {
rt = Constants.TIME_DROP_VALVE;
}
// 记录当前请求的round trip time,即调用时间
node.rt(rt);
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().rt(rt);
}
// 减少当前资源的并发线程数
node.decreaseThreadNum();
// 按调用方减少资源的并发线程数
if (context.getCurEntry().getOriginNode() != null) {
context.getCurEntry().getOriginNode().decreaseThreadNum();
}
// 记录全局的round trip time
if (resourceWrapper.getType() == EntryType.IN) {
Constants.ENTRY_NODE.rt(rt);
Constants.ENTRY_NODE.decreaseThreadNum();
}
} else {
// Error may happen.
}
Collection exitCallbacks = StatisticSlotCallbackRegistry.getExitCallbacks();
for (ProcessorSlotExitCallback handler : exitCallbacks) {
handler.onExit(context, resourceWrapper, count, args);
}
// 调用下游的slot exit方法
fireExit(context, resourceWrapper, count);
}
}
我在上面的代码中增加了一些注释,我们可以知道,StaticticSlot只是责任链中的一环,他通过调用DefaultNode的统计相关方法来完成流量的统计。我们接下来看看DefaultNode是怎么做的。
DefaultNode
/**
*
* A {@link Node} use to hold statistics for specific resource name in the specific context.
* Each distinct resource in each distinct {@link Context} will corresponding to a {@link DefaultNode}.
*
*
* This class may have a list of sub {@link DefaultNode}s. sub-node will be created when
* call {@link SphU}#entry() or {@link SphO}@entry() multi times in the same {@link Context}.
*
*
* @author qinan.qn
* @see NodeSelectorSlot
*/
public class DefaultNode extends StatisticNode {
private ResourceWrapper id;
private volatile HashSet childList = new HashSet();
private ClusterNode clusterNode;
public DefaultNode(ResourceWrapper id, ClusterNode clusterNode) {
this.id = id;
this.clusterNode = clusterNode;
}
public ResourceWrapper getId() {
return id;
}
public ClusterNode getClusterNode() {
return clusterNode;
}
public void setClusterNode(ClusterNode clusterNode) {
this.clusterNode = clusterNode;
}
public void addChild(Node node) {
if (!childList.contains(node)) {
synchronized (this) {
if (!childList.contains(node)) {
HashSet newSet = new HashSet(childList.size() + 1);
newSet.addAll(childList);
newSet.add(node);
childList = newSet;
}
}
RecordLog.info(String.format("Add child %s to %s", ((DefaultNode)node).id.getName(), id.getName()));
}
}
public void removeChildList() {
this.childList = new HashSet();
}
public Set getChildList() {
return childList;
}
@Override
public void increaseBlockQps() {
super.increaseBlockQps();
this.clusterNode.increaseBlockQps();
}
@Override
public void increaseExceptionQps() {
super.increaseExceptionQps();
this.clusterNode.increaseExceptionQps();
}
@Override
public void rt(long rt) {
super.rt(rt);
this.clusterNode.rt(rt);
}
...
我们看到DefaultNode实际上在统计相关的调用中使用了super的对应方法,我们继续看他的父类StatisticNode
/**
* @author qinan.qn
* @author jialiang.linjl
*/
public class StatisticNode implements Node {
private transient volatile Metric rollingCounterInSecond = new ArrayMetric(1000 / SampleCountProperty.SAMPLE_COUNT,
IntervalProperty.INTERVAL);
/**
* Holds statistics of the recent 60 seconds. The windowLengthInMs is deliberately set to 1000 milliseconds,
* meaning each bucket per second, in this way we can get accurate statistics of each second.
*/
private transient Metric rollingCounterInMinute = new ArrayMetric(1000, 60);
private AtomicInteger curThreadNum = new AtomicInteger(0);
private long lastFetchTime = -1;
...
@Override
public long maxSuccessQps() {
return rollingCounterInSecond.maxSuccess() * SampleCountProperty.SAMPLE_COUNT;
}
@Override
public long avgRt() {
long successCount = rollingCounterInSecond.success();
if (successCount == 0) {
return 0;
}
return rollingCounterInSecond.rt() / successCount;
}
@Override
public long minRt() {
return rollingCounterInSecond.minRt();
}
@Override
public int curThreadNum() {
return curThreadNum.get();
}
@Override
public void addPassRequest() {
rollingCounterInSecond.addPass();
rollingCounterInMinute.addPass();
}
...
这里我们看到在他的内部使用了两个ArrayMetric来做最终的统计,一个是基于以一秒为单位统计(即QPS),一个以一分钟为单位统计(total开头的),这个从两个变量的名字就能感受出来:
private transient volatile Metric rollingCounterInSecond ...
private transient Metric rollingCounterInMinute ...
接着就去看ArrayMetric的代码
ArrayMetric
/**
* The basic metric class in Sentinel using a {@link MetricsLeapArray} internal.
*
* @author jialiang.linjl
* @author Eric Zhao
*/
public class ArrayMetric implements Metric {
private final MetricsLeapArray data;
/**
* Constructor
*
* @param windowLengthInMs a single window bucket's time length in milliseconds.
* @param intervalInSec the total time span of this {@link ArrayMetric} in seconds.
*/
public ArrayMetric(int windowLengthInMs, int intervalInSec) {
this.data = new MetricsLeapArray(windowLengthInMs, intervalInSec);
}
/**
* For unit test.
*/
public ArrayMetric(MetricsLeapArray array) {
this.data = array;
}
@Override
public long success() {
data.currentWindow();
long success = 0;
List list = data.values();
for (MetricBucket window : list) {
success += window.success();
}
return success;
}
....
@Override
public void addBlock() {
WindowWrap wrap = data.currentWindow();
wrap.value().addBlock();
}
@Override
public void addSuccess() {
WindowWrap wrap = data.currentWindow();
wrap.value().addSuccess();
}
...
上面的代码中有两点需要我们注意:
- ArrayMetric将真正的信息放在了MetricsLeapArray中。创建MetricsLeapArray需要两个参数。
- windowLengthInMs代表的是滚动窗口的大小,以毫秒为单位
- intervalInSec代表的是整个统计的时长,以秒为单位。
- 每个方法调用的第一个操作都是data.currentWindow(),这个操作是什么意义呢?
带着这些疑问,我们来到了MetricsLeapArray
MetricsLeapArray
/**
* The fundamental data structure for metric statistics in a time window.
*
* @see LeapArray
* @author jialiang.linjl
* @author Eric Zhao
*/
public class MetricsLeapArray extends LeapArray {
/**
* Constructor
*
* @param windowLengthInMs a single window bucket's time length in milliseconds.
* @param intervalInSec the total time span of this {@link MetricsLeapArray} in seconds.
*/
public MetricsLeapArray(int windowLengthInMs, int intervalInSec) {
super(windowLengthInMs, intervalInSec);
}
@Override
public MetricBucket newEmptyBucket() {
return new MetricBucket();
}
@Override
protected WindowWrap resetWindowTo(WindowWrap w, long startTime) {
w.resetTo(startTime);
w.value().reset();
return w;
}
}
MetricsLeapArray继承了LeapArray
- newEmptyBucket 创建一个新的空的Bucket(统计桶)
- resetWindowTo 通过传入的时间戳来重置滚动窗口和它所包含的统计桶
这几个方法和变量命名都非常易懂,这里也不多展开,我们终于来到了最终的统计所在LeapArray
LeapArray
首先我们看LeapArray的成员变量和构造函数:
public abstract class LeapArray {
protected int windowLengthInMs;
protected int sampleCount;
protected int intervalInMs;
protected final AtomicReferenceArray> array;
private final ReentrantLock updateLock = new ReentrantLock();
/**
* The total bucket count is: {@link #sampleCount} = intervalInSec * 1000 / windowLengthInMs.
* @param windowLengthInMs a single window bucket's time length in milliseconds.
* @param intervalInSec the total time span of this {@link LeapArray} in seconds.
*/
public LeapArray(int windowLengthInMs, int intervalInSec) {
this.windowLengthInMs = windowLengthInMs;
this.intervalInMs = intervalInSec * 1000;
this.sampleCount = intervalInMs / windowLengthInMs;
this.array = new AtomicReferenceArray>(sampleCount);
}
从这些代码我们可以知道:
- windowLengthInMs 跟之前说的一样,是滚动窗口中每个窗口的长度,以毫秒为单位
- invervalInMs 即整个统计时长,以毫秒为单位
- sampleCount 即在整个统计时长中需要有多少个采样窗口
- array 通过AtomicReferenceArray来存储一个WindowWrap的原子数组,是存放滚动窗口的物理实现
接着我们来看刚刚提到的currentWindow:
/**
* Get the window at current timestamp.
*
* @return the window at current timestamp
*/
public WindowWrap currentWindow() {
return currentWindow(TimeUtil.currentTimeMillis());
}
/**
* Get window at provided timestamp.
*
* @param time a valid timestamp
* @return the window at provided timestamp
*/
public WindowWrap currentWindow(long time) {
// 获取当前毫秒对应到window length的一个id
long timeId = time / windowLengthInMs;
// Calculate current index.
// 获取这个id对应到滚动数组中的具体index
// 通过mod操作完成了数组的滚动
int idx = (int)(timeId % array.length());
// Cut the time to current window start.
// 计算出这个window对应的开始时间戳
time = time - time % windowLengthInMs;
// 自旋循环开始
while (true) {
// 获取index对应的窗口
WindowWrap old = array.get(idx);
if (old == null) {
// 如果是null, 说明出于滚动窗口初始化阶段
// 创建一个新的窗口,通过调用newEmptyBucket来获取新的统计桶
WindowWrap window = new WindowWrap(windowLengthInMs, time, newEmptyBucket());
// CAS 设置 AtomicReferenceArray里面对应的元素
if (array.compareAndSet(idx, null, window)) {
// 如果设置成功就返回当前的window
return window;
} else {
// 如果不成功调用 线程让步(这里不太明白)
// 进入下一次自旋循环
Thread.yield();
}
} else if (time == old.windowStart()) {
// 如果开始时间与现存的窗口的开始时间一致
// 表明请求时间戳与现存的窗口匹配,因此直接返回
return old;
} else if (time > old.windowStart()) {
// 如果请求的时间戳大于现存的窗口的开始时间
// 说明当前的窗口已经是陈旧的,也就是属于已经过去的一个统计时长之外的数据
// 因此需要重置窗口的数据
if (updateLock.tryLock()) {
try {
// 尝试获取update锁成功
// 调用resetWindowTo方法重置
// if (old is deprecated) then [LOCK] resetTo currentTime.
return resetWindowTo(old, time);
} finally {
updateLock.unlock();
}
} else {
// 如果获取锁失败,说明已经有其他线程获取锁并进行更新
// 因此调用线程让步 并进入下一次自旋循环
Thread.yield();
}
} else if (time < old.windowStart()) {
// 如果请求的时间比现存的还小,直接返回一个空的,说明这次请求的时间戳已经陈旧了
// Cannot go through here.
return new WindowWrap(windowLengthInMs, time, newEmptyBucket());
}
}
}
关于这段代码的讲解我已经写在了注释里面,需要注意的可能有几点:
- 通过while(true) 的自旋运算尽可能的减少了锁的使用,增强了线程的吞吐量
- 在一些冲突的情况下使用了thread yield方法,我查资料得到这个方法类似于让线程让步,但是调度器可以不理会,所以有可能不会有任何影响,这里是处于怎样的考虑可能需要大家提示一下,我理解的话可能是在冲突的时候尽可能留出时间给winner做好它该做的,然后loser在让步结束之后能够完成它该做的
另外,值得注意的一点是这里获取当前时间戳使用了一个TimeUtil,而不是System.currentTimeMillis,我们看看这个TimeUtil的实现:
/**
* Provides millisecond-level time of OS.
*
* @author qinan.qn
*/
public final class TimeUtil {
private static volatile long currentTimeMillis;
static {
currentTimeMillis = System.currentTimeMillis();
Thread daemon = new Thread(new Runnable() {
@Override
public void run() {
while (true) {
currentTimeMillis = System.currentTimeMillis();
try {
TimeUnit.MILLISECONDS.sleep(1);
} catch (Throwable e) {
}
}
}
});
daemon.setDaemon(true);
daemon.setName("sentinel-time-tick-thread");
daemon.start();
}
public static long currentTimeMillis() {
return currentTimeMillis;
}
}
这段代码就很简单了,相当于启动了一个线程每sleep 1ms唤醒并且调用System.currentTimeMillis记录当前时间戳到volatile变量中。这段代码我理解是通过这个线程来更新时间戳,这样每秒调用System.currentTimeMillis的次数稳定为1000次,如果不通过这个Util的话调用的次数无法估计,有可能远大于1000次,是否是有耗时等性能上的考虑?这个也欢迎大家提出意见。
通过上面的代码我们就可以知道,每次操作调用currentWindow相当于是一次对齐操作,无论是增加计数还是统计,调用currentWindow之后保证了我们底层存储的AtomicReferenceArray中对应index存放的肯定是当前时间戳对应的window,而绝不可能是陈旧的信息。
接下来我们再回过头看看增加计数的代码(ArrayMetric中):
@Override
public void addSuccess() {
WindowWrap wrap = data.currentWindow();
wrap.value().addSuccess();
}
其实就很好理解了,首先获取当前时间戳对应的window信息,然后通过addSuccess来做到原子增。这里内部使用了阿里自己开发的一个LongAddr,由于时间有限,我没有对这个进行深入分析了,可以看做是一个AtomicLong,应该性能会提高不少。
然后我们再看看一个统计代码(ArrayMetric中):
public long success() {
data.currentWindow();
long success = 0;
List list = data.values();
for (MetricBucket window : list) {
success += window.success();
}
return success;
}
这里可以理解的是通过调用底层LeapArray的values方法获取到了滚动数组中所有的“有效”窗口,然后通过累加这些窗口的success的数量得到整个统计时长的总success数,并返回,完成了统计功能。这里有个问题,什么叫有效窗口?我们接着看LeapArray中的values方法:
public List values() {
// 结果容器
List result = new ArrayList();
for (int i = 0; i < array.length(); i++) {
// 遍历底层AtomicReferenceArray的元素
WindowWrap windowWrap = array.get(i);
// 如果当前时间窗为空或者已经无效则无视之
if (windowWrap == null || isWindowDeprecated(windowWrap)) {
continue;
}
// 否则添加到结果中
result.add(windowWrap.value());
}
return result;
}
private boolean isWindowDeprecated(WindowWrap windowWrap) {
// 如果当前时间与对应时间窗开始时间的差值大于整个统计时长
// 说明这个时间窗已经陈旧,无需纳入统计中
return TimeUtil.currentTimeMillis() - windowWrap.windowStart() >= intervalInMs;
}
通过上述代码我添加的注释就已经很清楚了,isWindowDeprecated方法用来判断时间窗的有效性,values通过遍历底层滚动数组中每个时间窗元素,并判断其有效性,最后返回在统计时长内有效的统计数。
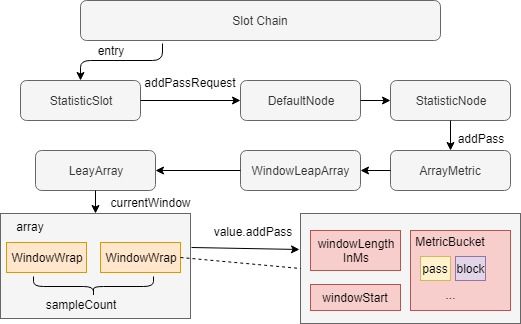
为了更加清晰的说明整个流程,大家可以参考下图来理解:
结语
至此,我已经完成了对Sentinel中流量统计部分代码的分析,希望大吉能够喜欢,对于文中讲的不清楚或者不正确的地方希望大家指正,共同进步!