大众点评数据交换工具Wormhole设计与实现
如果要查看架构请查看大众点评ELT平台整体架构分析http://blog.csdn.net/lvzhuyiyi/article/details/51842923,
下面给其中两张wormhole的图

图 4.3 Wormhole架构图

图 4.4 Wormhole的Splitter组件
1.1.1 数据交换工具Wormhole设计与实现
1.1.1.1 Wormhole整体设计
Wormhole是框架加插件的设计,各模块的设计思路:
1) 框架分为读管理器、双端缓冲队列和写管理器。读写管理器分别持有读写线程池,双端缓冲队列负责读写线程的数据交换。
2) 每种数据存储的插件分为或读写两种类型,每种类型又具体分为读或写、预和后处理、分片三种类型的插件。用不同接口来标识每种插件。扩展一种数据存储类型的方式是实现这些插件。
3) 插件的类型信息存在任务的配置文件中,以便解耦合,任务配置从数据库中获取。
4) 读管理器类持有读线程池,负责管理所有读线程、获取结果或者监控。
5) 写管理器类持有多个目的地的写线程池,负责管理所有读线程、获取结果或者监控。
6) 监控管理器持有所有读写线程的监控对象。
7) 有专门的读写线程,具体的读和写要调用Reader和Writer具体的实现类。每个线程传入监控对象负责过程统计。
8) Reader和Writer线程与双端缓冲队列交换数据引入缓冲避免交换次数。
9) 每个写目的地用一个双端缓冲队列,双端缓冲队列数据交换单位是行。
10) 必须有个引擎类,负责启动所有的读、写、交换和监控过程。
1.1.1.2 Wormhole引擎设计
Wormhole的启动运行过程涉及了所有组件的逻辑关系,是Wormhole实现的核心。整个过程设计分为四步:任务配置读取,启动读机制、启动写机制和启动循环监控。
任务配置读取过程是根据任务id从任务的数据库中读取配置的详细信息,生成配置类,然后同时运行读的过程和写的过程。
启动读机制的过程分为预处理阶段,分片阶段,和线程池启动阶段:
1) 预处理阶段。在准备读取数据之前我们要做一些预处理工作,放在一个Callable中。这些预处理工作是保证数据源能够连接,并且有数据以及统计本次传输要读取的行数。这些预处理工作不是强制的。超过一段时间还未完成我们就会跳过这步。
2) 分片阶段。我们要调用Splitter来对数据源进行分段,分段的逻辑与具体的数据源的Splitter类有关。如果是Hive,则与表在Hdfs的根目录下的非目录文件有关。如果是Mysql则和数据库行数有关。一个分片对应一个Reader线程,各有一个配置文件。
3) 线程池启动阶段。创建分片个数的Reader线程,由于是同一个任务,这里的Reader线程共用一个线程池,Reader线程里用对应的数据库的Reader插件(如MysqlReader)读取该分片数据,以行为单位发往缓冲区,缓冲区满了再一次发往多个目的地的双端缓冲队列(Storage),注意这里是复制分发,因为多个数据目的地都需要同样的数据。
启动写机制的过程类似,也分为预处理阶段,分片阶段,和线程池启动阶段。唯一不同的是对每个数据传输目的地要逐一重复上述三个阶段。
1) 预处理阶段。逐一遍历数据传输目的地,每个目的地会关联一份配置文件和一个双端缓冲队列,对每个目的地都要做同样的搞工作,首先是做一些预处理工作,比如清理目标表数据:如果是全量传输则清空目标表,增量则清空目标表增量。
2) 分片阶段。对每个目的地的写进行分片,这里的分片和你预设的并发数有关,每个分片的配置文件是相同的(因为目的地相同),数据来源都是共享对应的那个双端缓冲队列的数据,最后,启动分片数个数的写线程。可以看出,写的过程中传输目的地Writer线程池也是一对一的关系。
3) 线程池启动阶段。在读和写的过程中,每个读线程,写线程和每个双端缓冲队列都有基于行为单位的数据读写监控,统计自己成功写和读的数据个数,最后在主线程中进行统计。
启动监控过程,这是一个循环,不断的用Future的get(time,unit)方法来尝试获取Reader和Writer线程的结果,如果未运行结束就会抛出timeout异常,这种情况是正常的,捕捉然后忽略这个异常。如果出现了异常、失败或完成状态,则关闭线程池,并统计出错的行数,为0则成功。在不考虑强写一致性的情况下,如果没有超过一个预设的阀值仍然认为是成功的。没出现失败情况,线程池又有线程未完成,则返回正在运行。
1.1.1.3 Wormhole具体设计与实现
Wormhole是Framework+Plugin架构,Plugin的设计是由各种Reader、Writer以及Splitter(读写分片器)和Periphery(预处理和后处理)类组成。而Framework的核心组件有:
1) Engine类。这是Wormhole组件的核心引擎类,是Wormhole入口,有main()函数,解析参数后负责启动Reader线程池和Writer线程池。
2) StorageManger类。这是双端缓冲队列(IStorage)管理类,负责管理本次传输所以要使用的双端缓冲队列。要启动的双端缓冲队列的个数取决于数据库中该任务配置中传输目的地的个数,队列的一些参数也要从既定配置中获取。双端缓冲队列和数据传输目的地是一一对应的,而且对应关系在Wormhole启动时就设置好了。
3) ReaderManager类。这是读的过程的管理类。如上所述,读的过程分为预处理阶段,分片阶段,和线程池启动阶段。预处理阶段的Callable不是强制要求运行完成的,设置了一定的超时时间。然后是分片,这个Callable必须获取到结果,然后生成每个分片的包含分片信息配置文件。最后启动ReaderThread线程池,该线程会调用Reader插件进行读取。Reader插件把读取的行送到所有启动的双端缓冲队列中。等待Writer的读取。
4) WriterManager类。本类是写过程的管理类。如上所说,每一个数据传输目的地的写过程也包括预处理阶段,分片阶段,和线程池启动阶段。预处理阶段类似,不过这里的预处理是为了清空目标数据库可能会与本次传输重复的数据(全量清空或增量部分清空)。分片阶段的分片是取决于配置文件中的并发,最后写线程池的启动,开始写过程。
5) MonitorManager类。这个类是管理本次传输全局统计的对象。本身所有读线程和写线程的监控对象。负责在传输结束时调用,获取本次传输成功和失败读取的行数,每个传输目的地成功和失败写的行数以及每个双端缓冲队列收到和发送的行数,字节数等。
6) BufferdLineExchanger类。这个类是对Reader和Writer线程从双端缓冲区队列读写做缓存的,只有写的时候缓存区满了或者读的时候缓存区空了才会向双端缓冲队列写入数据。
7) RAMStorage类。这个类算是双端缓冲队列的代理类。是用内存来存储双端缓冲队列的交换区,以及在单纯的双端缓冲队列上增加接收和发送数据各项指标的统计。还有关闭双端缓冲队列写功能等。
8) DoubleQueue类。真正的双端缓冲队列类。读用一个队列,写用一个队列。读用读锁,写和交换队列用写锁。只有读队列为空且写队列不为空才进行交换。
下面我们详细介绍各组件的实现。
Engine类是Wormhole传输工具的入口类(如图5.7),Wormhole镜像对应的Docker容器的启动命令里java -jar后面的参数比如任务id等,就是在这里解析。Engine类的成员变量有:
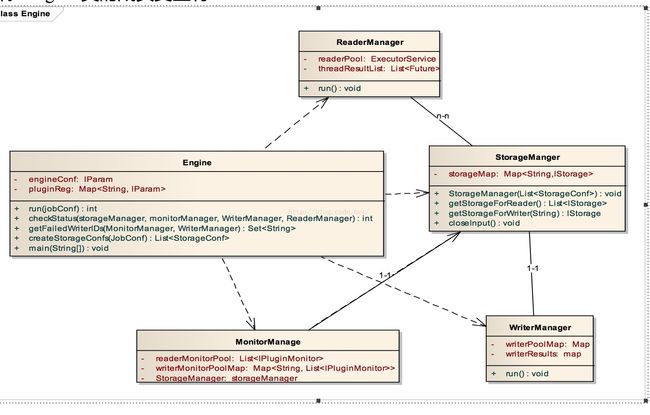
图5.7 Engine类的设计
1) IParam类的engineConf实例:这个成员变量是存储Wormhole的监测机制参数和数据交换机制(双端缓冲队列)的一些参数。如每次Reader和Writer线程池检查之间的间隔时间、打印检查报告的频率(并不是每次状态检查都会打印监测报告)、RAMStorage的读写缓冲队列的初始大小,允许出错的行数等。
2) Map
接下来是Engine类的成员方法:
1) run(JobConf jobConf):int方法。这是Engine类的核心方法。在这个方法中依次实现Wormhole的启动和监控。回忆上一小节,这个方法的代码分为四步:任务配置读取,启动读机制(一个线程池)、启动写机制(每个目的地一个线程池)和启动循环监控。当所有线程都结束以后,返回整个任务的运行结果,成功或失败,失败的行数等。当然失败的原因还得查看任务的日志(日志的输出由log4j负责)。
2) checkStatus(ReaderManager readerManager,WriterManager writerManager,MonitorManagermonitorManager,StorageManager storageManager):int方法。这个方法是监控当前Wormhole运行状态的核心方法,每过一个时间段都会调用此方法来获取集群各线程的状态。主要步骤是Reader线程的检查过程和Writer线程的检查过程。这两项工作分别由ReaderManager和WriterManager完成。它们分别持有读写线程的线程池和Future对象列表。具体检查过程就是以线程池为单位进行检查,对每个线程的Future对象调用get方法,阻塞一段时间,抛出timeoutE-xception或InterruptException表示正在运行,返回运行状态。其他非成功情况会引起线程池的关闭(shutdownNow),成功情况线程池已经关闭,这两种情况返回关闭状态。最后根据Reader线程和Writer线程池的是否处于关闭状态以及是否写入的行数和要读取的行数的差异来判断任务是成功、失败或者部分失败等。由于Writer线程有多个线程池,每次检查时都要从把关闭的线程池从Writer线程池队列中删除。
3) getFailedWriterIds(ReaderManager ReaderManager,MonitorManagermonit-orManager):Set
4) createStorageConf(JobConf jobConf):List
下面介绍StorageManager,在开始介绍StorageManager之前,我们先看一下以StorageManager(具体来说是它管理的若干个双端缓冲队列)为核心的Wormhole众多关键类的类图。有助于我们了解整个Wormhole组件的耦合方式。详见下图(图5.8)。
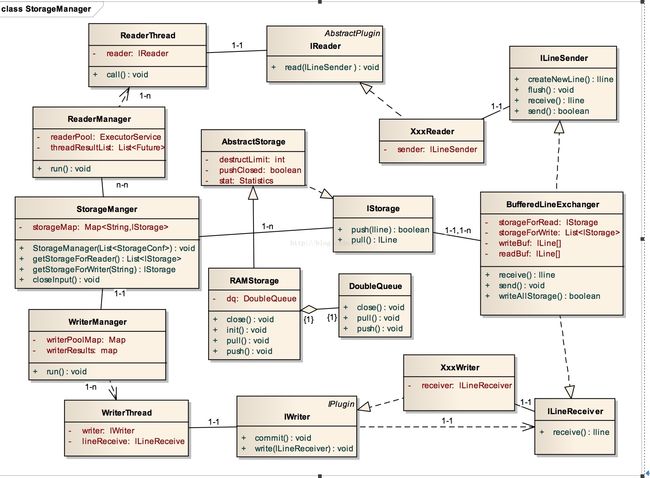
图5.8 以StorageManger为核心的Wormhole整体类图结构设计
可以看出,整个Wormhole类图架构(如图5.8)有以下特点:
1) 是以StorageManger、IStorage和BufferedLineExchanger为代表的数据交换的核心类为中轴,两边读和写过程的类相互对称的整体架构。这个架构与我们前面描述的Wormhole机制相符。这里要说明的是实际使用的双端缓冲队列是RAMStorage类。而BufferedLineExchanger类在读写两边分别有两个实例。StorageManager持有了所有的双端缓冲队列。
2) 组件之间耦合一般都是以接口的形式。这大大提高了组件之间的耦合的灵活性,实际上正式因为接口的存在,我们才能不断的针对不同数据源开发不同的插件来增加Wormhole的功能。举例说明:StorageManager管理的是IStorage类的实例而不是具体的RAMStorage类;ReaderThread耦合的是IReader接口,而不是它的具体实现类XxxReader;WriterThread耦合的是IWriter接口,而不是它的具体实现类XxxWriter。Reader和Writer插件类用来与双端缓冲队列交换数据的类是ILineSender、ILineReceiver而不是BufferedLineger类。
3) ReaderManager和WriterManager都采用了专有线程和线程池技术来运行和管理读写过程。读的专门线程是ReaderThread,写的专门线程是WriterThread。这里的线程实现的都是Callable接口。ReaderManager和WriterManager都分别持有所有读写线程的Future列表,用来实时获取任务的状态和运行结果。
介绍完整个Wormhole类图和StorageManager的核心作用后,我们来详细分析StorageManager类。
StorageManager类的成员变量只有一个:Map
StorageManager类的成员方法列表如下:
1) StorageManager(List
2) getStorageForReader():List
3) getStorageForWriter(String id):IStorage方法。这个方法为每个数据传输目的地的id提供对应读取的双端缓冲队列。这里只有一个数据源。
4) closeInput():void方法。这个方法是为了关闭所有的双端缓冲队列。主要是对每一个双端队列做到两点工作:一是关闭写入。二是禁止读写队列交换。
接下来我们介绍ReaderManager(如图5.9)。ReaderManager是读过程启动和管理类,主要是ReaderThread线程池的启动、管理和监控。ReaderManager的成员变量如下:
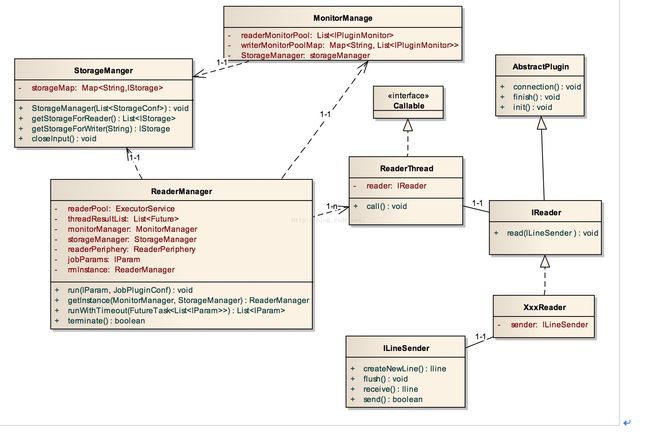
图5.9 以ReaderManager为核心的读过程类图结构设计
1) ExecutorService类的ReaderPool实例。这个成员变量就是ReaderThread线程池分管理类。
2) List
3) MonitorManager类的monitorManager实例。这个成员变量是监控管理器,用来为每个ReaderThread线程创建一个监控对象。并把这个监控对象加入到自己的监控列表中。
4) StorageManager类的storageManager实例。这个成员变量是为每个ReaderThread线程提供写的目标双端缓冲队列列表。
5) ReadePeriphery类的readerPeriphery实例。这个成员变量是根据插件配置文件中的具体预、后处理类反射生成。主要是为了做一些读取数据库的预处理工作和线程异常结束后的后处理工作。
6) IParam类jobParams实例。这个成员变量就是保存任务的配置信息。
7) ReaderManager类的rmInstance实例。这个成员变量是ReaderManager类的单例实例。
ReaderManager类的成员方法介绍如下:
1) run(IParam pluginParam,JobPluginConf jobPluginConf):void方法。此方法是ReaderManager的核心方法,用来启动整个读机制。正如前面所述,包括三个阶段:XxxReaderPeriphery的预处理、XxxReaderSplitter的分片和ReaderPool的提交各个分片的线程任务。最后调用ReaderPool的shutdown方法,等待线程结束。
2) getInstance(MonitorManager monitorManager,StorageManager storageMan-ager)方法。这个方法是ReaderManager的单例实例的工厂方法。
3) runWithTimeout(FutureTask future)方法。此方法用来运行预处理和分片的future实例,在指定时间内获取结果。
4) terminate():boolean方法。此方法是ReaderManager的监控Reader线程池的核心方法。该方法首先检查所有线程是否成功或正在运行,不是则关闭该线程池。然后根据线程池是终止状态(成功完成后者异常被关闭)还是运行状态来返回true或者false。
WriterManager是写过程管理类(如图5.10)。WriterManager主要的成员变量有:
1) MonitorManager类的monitorManager实例。这个成员变量是监控管理器,用来为每个WriterThread线程创建一个监控对象。并把它加入到对应传输目的地的队列中。
2) StorageManager类的storageManager实例。这个成员变量是为每个WriterThread线程提供读的目标双端缓冲队列。
3) Map
4) Map
5) Map
6) Map
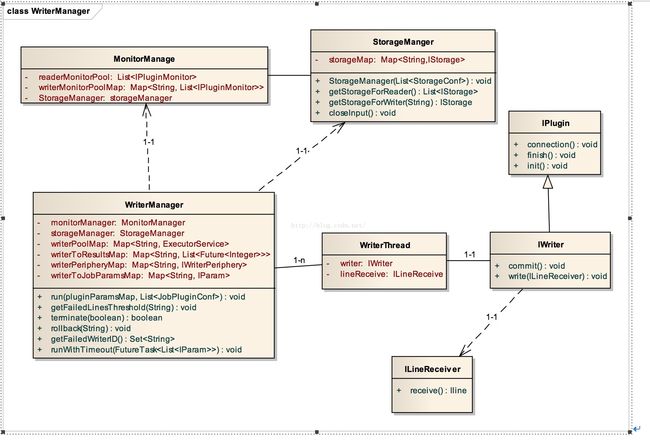
图5.10 以WriterManager为核心的写过程类图结构设计
WriterManager的主要成员方法有:
1) run(List
2) getFailedWriterID()。这个方法其实是监控当前在写的多个线程池的状态,并把失败的线程池对应的传输目的地id列表返回。具体的监控办法和上文监控过程原理描述一致。
3) rollback(String WriterId)。这个方法是后处理方法,当某个线程池的线程写入出错,就需要回滚写入的数据。具体是通过回滚的sql来执行的。
下面我们来看监控类MonitorManager(如图5.11)。这是Wormhole类的监控核心类。持有所有读写线程的监控对象。MonitorManaager的主要成员变量有:
图5.11 以MonitorManager类为核心的监控过程类图结构设计
1) List
2) Map
3) long基本类型的sourceLines。这是存储的本次数据传输所要读取的行数,一般是在读预处理过程进行。
4) Map
MonitorManager类的成员方法有:
1) newReaderMonitor():IPluginMonitor方法。此方法是监控读线程对象的工厂方法,创建监控对象并把它加入到读监控对象列表。
2) newWriterMonitor():IPluginMonitor方法。此方法是监控写线程对象的工厂方法,创建写监控对象并把它加入对应目的地的监控对象列表。
3) getCompletedMonitorInfo():CompleteMonitorInfo方法。此方法主要包括三部分的统计信息:一是读过程统计信息,这个只要统计读监控对象即可。二是所有双端缓冲队列的统计信息。这个只要调用storageManager的方法获得所有双端缓冲队列,根据每个队列的统计成员变量就可以获得相应信息。三是每个传输目的地写过程统计信息,这个只要统计相应写监控对象即可。
4) getRealTimeMonitorInfo():RealTimeMonitorInfo方法。这个方法主要是统计当前所有双端缓冲队列的信息。
最后,我们来介绍Wormhole数据交换的核心类DoubleQueue类(如图5.12)。这个类是双端缓冲队列机制的核心。DoubleQueue的成员变量有:

图5.12 DoubleQueue类的设计
1) ILine[]类的实例writeArray和readArray实例。这两个成员变量分别是双端缓冲队列的读队列和写队列,在构造函数中进行初始化。
2) int基本类型readCount和writeCount。这两个变量分别是读队列的元素个数和写队列的元素个数。
3) int基本类型readPosition和writePosition。第一个变量是读队列元素未读取的第一个元素的索引。第二个变量是写队列中空位的第一个元素的索引,它们初始值都是0。
4) ReentrantLock类的readLock和writeLock实例。前者是读锁后者是写锁。写锁同时还能用来交换队列。
5) Condition类的notFull和awake实例。两者都是writeLock锁上的对象。notFull信号量用来处理写入时写队列已满时的情况,此时必须等待读写队列交换成功。awake信号量用来处理,读队列为空,要交换但写队列也为空的情况。此时必须等待写队列不为空。
6) boolean类型的closed变量。这个变量是用来禁止队列交换和数据写入的。因为数据队列已关闭。
7) int基本类型的spillSize变量。这个变量是读队列为空请求数据交换时,写队列允许交换的阀值。
下面看看DoubleQueue的成员方法:
1) push(ILine line, longtimeout,TimeUnit unit):boolean方法。此方法向写队列插入一行,如果是写队列第一行,则调用awake.siginalAll()。因为很可能读线程正在等待队列交换(此时读队列为空)。如果写队列已满,则调用notFull.awa-it()等待读队列为空时交换队列。此方法效率不高现实中较少用。
2) push(ILine[] lines, intsize,longtimeout, TimeUnitunit):boolean方法。此方法向写队列插入多行,写入的行数大于spillSize,则调用awake.signalALL()。因为很可能读线程正在等待交换队列。如果写队列已满,则调用notFull.await()等待读队列为空时交换队列。
3) pull(longtimeout,TimeUnit unit):boolean方法。此方法从读队列中读取一行,首先判断读队列是否为空,否则读取,是则进行获取写锁进行队列交换。
4) push(ILine[] lines, intsize,longtimeout, TimeUnitunit):boolean方法。此方法从读队列中读取size和readcount两者中较小值的行数,如果读队列不为空则读取,读队列为空则进行获取写锁进行队列交换。
5) queueSwitch(longtimeout,booleanisInfInite):long方法。此方法在读数据发现读队列为空时尝试进行交换。先检查写队列是否为空,不为空则交换,交换成功后调用notFull.signalALL(),为空则调用awake.await()进行等待。被唤醒后检查是否超时或者队列关闭(closed标志位),没超时再检查写队列是否为空,不空再交换。
6) close():void方法。此方法将双端队列的closed标志设为true。不允许再发起队列交换请求。同时调用await.signalAll()以唤醒正在等待队列交换的线程,它们也不能交换,直接退出。