python爬虫之使用BeautifulSoup爬取博客标题以及读写数据(txt、csv文件格式)操作
1.内容爬取
首先上代码:
import requests
from bs4 import BeautifulSoup
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
for i in range(1,8):
link='https://blog.csdn.net/lws123253/article/list/'+str(i)+'?'
r=requests.get(link,headers=headers)
soup=BeautifulSoup(r.text,"html.parser")
title_list=soup.find_all('div',class_="article-item-box csdn-tracking-statistics")
for title in title_list:
print(title.a.contents[2].strip())#注意这里的写法代码中其它地方没什么好说的,这里主要讲一下最后一行代码:
print(title.a.contents[2].strip())
我们先观察下我们需要爬取的内容的网页代码:
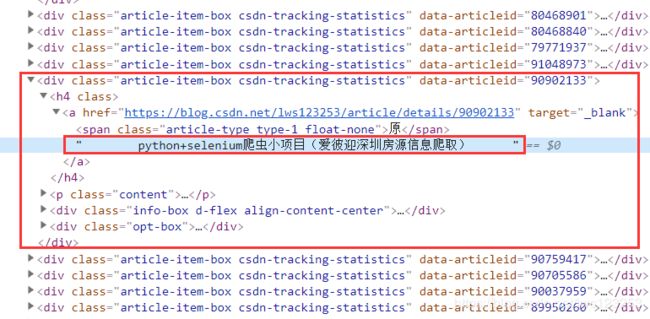
我可以发现,我们需要的信息被包含在"a"标签中, 但是由于我们没有办法通过“a”标签直接定位我们的需要信息,所以我们找它的上级,可以通过一些所有标题通用“class”等来标识,然后一步步往下走。比如我们可以通过“div”->"a"->"信息",但是注意a标签里还包含文章标题前面的“原创”或者“转载”标记,即“原”或者“转”。所以这时候我们得另想其它办法,我们可以通过a.contnets[2].strip()获取。如果这里不清楚contens的下标应该是多少,可以先打印a.contents,然后找到我们需要的内容的位置,就可以判断下标了。
2.存储
2.1 存储至txt文件
上面的代码,稍微调整后:
import requests
from bs4 import BeautifulSoup
with open(r'C:\Users\AdenLee\Desktop\blog.txt','a+') as f:
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
for i in range(1,8):
link='https://blog.csdn.net/lws123253/article/list/'+str(i)+'?'
r=requests.get(link,headers=headers)
soup=BeautifulSoup(r.text,"html.parser")
title_list=soup.find_all('div',class_="article-item-box csdn-tracking-statistics")
for title in title_list:
#print(title.a.contents[2].strip())#直接输出,注意这里的写法
f.write(title.a.contents[2].strip()+'\n')#存入文件
f.close()2.2 存储至csv文件
import requests
from bs4 import BeautifulSoup
import csv
with open(r'C:\Users\AdenLee\Desktop\blog.csv','a+',encoding='UTF-8',newline='') as f:#newline=''的作用是每一行之间没有间隙,否则会有空行
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
for i in range(1,8):
link='https://blog.csdn.net/lws123253/article/list/'+str(i)+'?'
r=requests.get(link,headers=headers)
soup=BeautifulSoup(r.text,"html.parser")
title_list=soup.find_all('div',class_="article-item-box csdn-tracking-statistics")
for title in title_list:
#print(title.a.contents[2].strip())#直接输出,注意这里的写法
#f.write(title.a.contents[2].strip()+'\n')#存入文件
w=csv.writer(f)
#w.writerow(title.a.contents[2].strip())
#注意下面的写法,如果不把保存的内容加上[],由于writerow将一个列表写入文件,则一个字符串中每一个字符则会被当做一个元素
w.writerow([title.a.contents[2].strip()])
f.close()这里强调一下写入的时候的写法: w.writerow([title.a.contents[2].strip()]),注意观察里面是有一个中括号的。
3.读取
3.1 从txt文件读取
import requests
from bs4 import BeautifulSoup
with open(r'C:\Users\AdenLee\Desktop\blog.txt','r') as f:
result=f.read()
print(result)
f.close()3.2从csv文件读取
import requests
from bs4 import BeautifulSoup
import csv
#注意下面要添加:encoding='UTF-8',否则会报如下错误
# 'gbk' codec can't decode byte 0xac in position 14: illegal multibyte sequence
with open(r'C:\Users\AdenLee\Desktop\blog.csv','r',encoding='UTF-8') as f:
csv_reader=csv.reader(f)
for row in csv_reader:
print(row)
f.close()注意读取时要添加:encoding='UTF-8',否则会报如下错误
'gbk' codec can't decode byte 0xac in position 14: illegal multibyte sequence