双向匹配分词算法 Java
本文并非原创算法,但是经过我的改进已将原创改为Java实现,现在附上原创链接:
http://my.oschina.net/u/1270374/blog/164042
目前比较流行的几大分词算法有:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。本文采用的是基于字符串匹配法。
正向最大匹配分词:
该算法是基于分词词典实现,从字符串左侧进行分割匹配,如果词典存在则返回分割出来的词语并将该词从之前的字符串中切除,循环进行切割直到字符串大小为0。
例如:str = "我们都是西北农林科技大学信息工程学院的学生。",(假设我们定义最大切割长度max = 8,也就是八个汉字)
1.定义分词长度len = max,从左边取出len个字符word = "我们都是西北农林",并在字典中匹配word;
2.字典中没有该词,那么去掉最后一个字符赋值给word,len值减1;
3.重复步骤2,直到在字典中找到该词或是len = 1,退出循环;
4.从str中切除掉已分割的词语,重复进行1、2、3步骤,直到str被分解完。
逆向最大匹配分词:
和正向分词算法一样,只是从字符串的右边开始切分词语,直到字符串长度为0,。这里不再赘述。
双向匹配分词:
该方法是在正向分词和逆向分词的基础上,对于分割有歧义的语句进行歧义分词。提出“贪吃蛇算法”实现。要进行分词的字符串,就是食物。有2个贪吃蛇,一个从左向右吃;另一个从右向左吃。只要左右分词结果有歧义,2条蛇就咬下一口。贪吃蛇吃下去的字符串,就变成分词。 如果左右分词一直有歧义,两条蛇就一直吃。两条蛇吃到字符串中间交汇时,就肯定不会有歧义了。这时候,左边贪吃蛇肚子里的分词,中间没有歧义的分词,右边贪吃蛇肚子里的分词,3个一拼,就是最终的分词结果。
本文是对整段话进行分词,首先将这段话根据标点符号断句,然后将每句话再进行分词输出。
package cn.nwsuaf.spilt;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Scanner;
/**
* 基于正逆双向最大匹配分词算法实现
* @author 刘永浪
*
*/
public class WordSpilt {
/**
* 存储分词词典
*/
private Map map = new HashMap();
/**
* 最大切词长度,即为五个汉字
*/
private int MAX_LENGTH = 5;
/**
* 构造方法中读取分词词典,并存储到map中
*
* @throws IOException
*/
public WordSpilt() throws IOException {
BufferedReader br = new BufferedReader(new FileReader("src/dict.txt"));
String line = null;
while ((line = br.readLine()) != null) {
line = line.trim();
map.put(line, 0);
}
br.close();
}
/**
* 设置最大切词长度
*
* @param max
* 最大切词长度
*/
public void setMaxLength(int max) {
this.MAX_LENGTH = max;
}
/**
* 获取当前最大切词长度,默认为5(5个汉字)
*
* @return 当前最大切词长度
*/
public int getMaxLength() {
return this.MAX_LENGTH;
}
/**
* 最大匹配分词算法
*
* @param spiltStr
* 待切分的字符串
* @param leftToRight
* 切分方向,true为从左向右,false为从右向左
* @return 切分的字符串
*/
public List spilt(String spiltStr, boolean leftToRight) {
// 如果带切分字符串为空则返回空
if (spiltStr.isEmpty())
return null;
// 储存正向匹配分割字符串
List leftWords = new ArrayList();
// 储存负向匹配分割字符串
List rightWords = new ArrayList();
// 用于取切分的字串
String word = null;
// 取词的长度,初始化设置为最大值
int wordLength = MAX_LENGTH;
// 分词操作中处于字串当前位置
int position = 0;
// 已经处理字符串的长度
int length = 0;
// 去掉字符串中多余的空格
spiltStr = spiltStr.trim().replaceAll("\\s+", "");
// 当待切分字符串没有被切分完时循环切分
while (length < spiltStr.length()) {
// 如果还没切分的字符串长度小于最大值,让取词词长等于该词本身长度
if (spiltStr.length() - length < MAX_LENGTH)
wordLength = spiltStr.length() - length;
// 否则取默认值
else
wordLength = MAX_LENGTH;
// 如果是正向最大匹配,从spiltStr的position处开始切割
if (leftToRight) {
position = length;
word = spiltStr.substring(position, position + wordLength);
}
// 如果是逆向最大匹配,从spiltStr末尾开始切割
else {
position = spiltStr.length() - length;
word = spiltStr.substring(position - wordLength, position);
}
// 从当前位置开始切割指定长度的字符串
// word = spiltStr.substring(position, position + wordLength);
// 如果分词词典里面没有切割出来的字符串,舍去一个字符
while (!map.containsKey(word)) {
// 如果是单字,退出循环
if (word.length() == 1) {
// 如果是字母或是数字要将连续的字母或者数字分在一起
if (word.matches("[a-zA-z0-9]")) {
// 如果是正向匹配直接循环将后续连续字符加起来
if (leftToRight) {
for (int i = spiltStr.indexOf(word, position) + 1; i < spiltStr
.length(); i++) {
if ((spiltStr.charAt(i) >= '0' && spiltStr
.charAt(i) <= '9')
|| (spiltStr.charAt(i) >= 'A' && spiltStr
.charAt(i) <= 'Z')
|| (spiltStr.charAt(i) >= 'a' && spiltStr
.charAt(i) <= 'z')) {
word += spiltStr.charAt(i);
} else
break;
}
} else {
// 如果是逆向匹配,从当前位置之前的连续数字、字母字符加起来并翻转
for (int i = spiltStr.indexOf(word, position - 1) - 1; i >= 0; i--) {
if ((spiltStr.charAt(i) >= '0' && spiltStr
.charAt(i) <= '9')
|| (spiltStr.charAt(i) >= 'A' && spiltStr
.charAt(i) <= 'Z')
|| (spiltStr.charAt(i) >= 'a' && spiltStr
.charAt(i) <= 'z')) {
word += spiltStr.charAt(i);
if (i == 0) {
StringBuffer sb = new StringBuffer(word);
word = sb.reverse().toString();
}
} else {
// 翻转操作
StringBuffer sb = new StringBuffer(word);
word = sb.reverse().toString();
break;
}
}
}
}
break;
}
// 如果是正向最大匹配,舍去最后一个字符
if (leftToRight)
word = word.substring(0, word.length() - 1);
// 否则舍去第一个字符
else
word = word.substring(1);
}
// 将切分出来的字符串存到指定的表中
if (leftToRight)
leftWords.add(word);
else
rightWords.add(word);
// 已处理字符串增加
length += word.length();
}
// 如果是逆向最大匹配,要把表中的字符串调整为正向
if (!leftToRight) {
for (int i = rightWords.size() - 1; i >= 0; i--) {
leftWords.add(rightWords.get(i));
}
}
// 返回切分结果
return leftWords;
}
/**
* 判断两个集合是否相等
*
* @param list1
* 集合1
* @param list2
* 集合2
* @return 如果相等则返回true,否则为false
*/
public boolean isEqual(List list1, List list2) {
if (list1.isEmpty() && list2.isEmpty())
return false;
if (list1.size() != list2.size())
return false;
for (int i = 0; i < list1.size(); i++) {
if (!list1.get(i).equals(list2.get(i)))
return false;
}
return true;
}
/**
* 判别分词歧义函数
*
* @param inputStr
* 待切分字符串
* @return 分词结果
*/
public List resultWord(String inputStr) {
// 分词结果
List result = new ArrayList();
// “左贪吃蛇”分词结果
List resultLeft = new ArrayList();
// “中贪吃蛇”(分歧部分)分词结果
List resultMiddle = new ArrayList();
// “右贪吃蛇”分词结果
List resultRight = new ArrayList();
// 正向最大匹配分词结果
List left = new ArrayList();
// 逆向最大匹配分词结果
List right = new ArrayList();
left = spilt(inputStr, true);
/*System.out.println("正向分词结果:");
for (String string : left) {
System.out.print(string + "/");
}
System.out.println("\n逆向分词结果:");*/
right = spilt(inputStr, false);
/*for (String string : right) {
System.out.print(string + "/");
}
System.out.println("\n双向分词结果:");*/
// 判断两头的分词拼接,是否已经在输入字符串的中间交汇,只要没有交汇,就不停循环
while (left.get(0).length() + right.get(right.size() - 1).length() < inputStr
.length()) {
// 如果正逆向分词结果相等,那么取正向结果跳出循环
if (isEqual(left, right)) {
resultMiddle = left;
break;
}
// 如果正反向分词结果不同,则取分词数量较少的那个,不用再循环
if (left.size() != right.size()) {
resultMiddle = left.size() < right.size() ? left : right;
break;
}
// 如果以上条件都不符合,那么实行“贪吃蛇”算法
// 让“左贪吃蛇”吃下正向分词结果的第一个词
resultLeft.add(left.get(0));
// 让“右贪吃蛇”吃下逆向分词结果的最后一个词
resultRight.add(right.get(right.size() - 1));
// 去掉被“贪吃蛇”吃掉的词语
inputStr = inputStr.substring(left.get(0).length());
inputStr = inputStr.substring(0,
inputStr.length() - right.get(right.size() - 1).length());
// 清理之前正逆向分词结果,防止造成干扰
left.clear();
right.clear();
// 对没被吃掉的字符串重新开始分词
left = spilt(inputStr, true);
right = spilt(inputStr, false);
}
// 循环结束,说明要么分词没有歧义了,要么"贪吃蛇"从两头吃到中间交汇了
// 如果是在中间交汇,交汇时的分词结果,还要进行以下判断:
// 如果中间交汇有重叠了:
// 正向第一个分词的长度 + 反向最后一个分词的长度 > 输入字符串总长度,就直接取正向的
if (left.get(0).length() + right.get(right.size() - 1).length() > inputStr
.length())
resultMiddle = left;
// 如果中间交汇,刚好吃完,没有重叠:
// 正向第一个分词 + 反向最后一个分词的长度 = 输入字符串总长度,那么正反向一拼即可
if (left.get(0).length() + right.get(right.size() - 1).length() == inputStr
.length()) {
resultMiddle.add(left.get(0));
resultMiddle.add(right.get(right.size() - 1));
}
// 将没有歧义的分词结果添加到最终结果result中
for (String string : resultLeft) {
result.add(string);
}
for (String string : resultMiddle) {
result.add(string);
}
// “右贪吃蛇”存储的分词要调整为正向
for (int i = resultRight.size() - 1; i >= 0; i--) {
result.add(resultRight.get(i));
}
return result;
}
/**
* 将一段话分割成若干句话,分别进行分词
*
* @param inputStr
* 待分割的一段话
* @return 这段话的分词结果
*/
public List resultSpilt(String inputStr) {
// 用于存储最终分词结果
List result = new ArrayList();
// 如果遇到标点就分割成若干句话
String regex = "[,。;!?]";
String[] st = inputStr.split(regex);
// 将每一句话的分词结果添加到最终分词结果中
for (String stri : st) {
List list = resultWord(stri);
result.addAll(list);
}
return result;
}
public static void main(String[] args) {
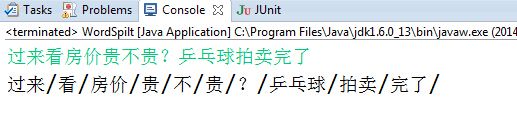
// example:过来看房价贵不贵?乒乓球拍卖完了
Scanner input = new Scanner(System.in);
String str = input.nextLine();
WordSpilt wordSpilt = null;
try {
wordSpilt = new WordSpilt();
} catch (IOException e) {
e.printStackTrace();
}
List list = wordSpilt.resultWord(str);
for (String string : list) {
System.out.print(string + "/");
}
}
}
运行结果如下:
发送源代码文件请与我联系。