kafka角色模型与核心概念
kafka主要有三大作用,其中消息系统和流式处理是我们最常用的
消息系统:kafka作为消息中间件,具有MQ的系统解耦、流量削峰、缓冲、异步通信等特性
存储系统:kafka与其他消息系统不同的是,它能够把消息持久化到磁盘,有效的降低了消息丢失风险, 只要把数据保留策略设置为永久,即消息永不过期,可以作为长期的数据存储系统来使用。
流式处理:kafka支持流式处理框架(SparkStreaming、Storm、Flink等),提供了完整的流式处理类库,比如窗口、连接、变换、聚合等各类操作。
先来看一张kafka的体系结构图
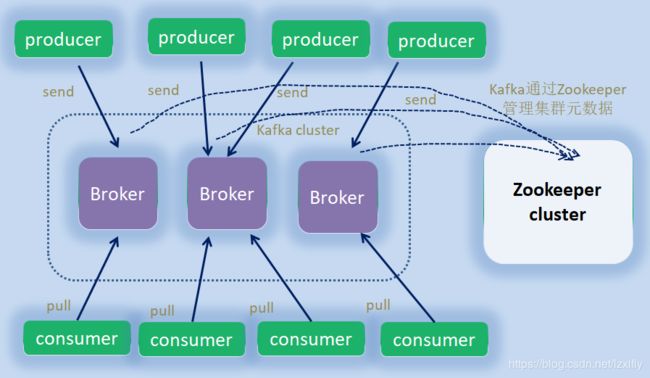
一个典型的kafka体系架构包括若干Broker、若干Producer、若干Consumer,以及一个Zookeeper集群。Zookeeper集群管理kafka集群元数据,leder的选举,消息offset的维护。Producer把消息发送到Broker,Broker负责将收到的消息存储到磁盘中,而Consumer订阅Broker并拉取消息消费。
kafka中主要包括以下角色模型及概念
一、Producer
生产者,负责创建消息,一般是本地客户端,由研发人员手动编写代码实现消息生产,把消息投递Kafka中
二、Consumer
消息者,负责接收消息,一般是本地客户端,由研发人员手动编写代码实现,连接到kafka获取消息,进行消息费
三、Consumer Group
消费者组,Kafka中存在消费者组的概念,每个消费者都属于一个对应的消费者组,可以存在多个消费者组。一个分区只能被同一个消费者组的一个消费者消费,一个消费者组内的同一个消费者可以消费多个分区。下图中有两个消费者组A和B。分区P0和P1同时由消费者组A和B的各自的消费者消费,即P0对C0和C4,P1对C1和C5。而P2和P3 分别对应C2和C3,即同一个分区只能由同一个消费者组内的一个消费者消费

四、Broker
存储消息的节点。就kafka而言,Broker可以视为一个kafka服务节点或实例。一个或多个Broker实例组成了一个kafka集群
五、Topic
主题,kafka中的消息存储以主题单位进行分类存储。生产者将消息发送到特定的主题, 消费者订阅对应的主题并进行消费消息,即每条消息都要属于某一个Topic,要落于某个Topic之上。
六、Partition
5.1、Topic与Partition关系
Partition即分区,Topic-主题只是一个逻辑上的概念,一个Topic可以分为多个Partition,一个Partition只能属于一个Topic,一个Topic下的不同Partition可以存储在多个Broker之上,但一个Partition只能存储在一个Broker之上。
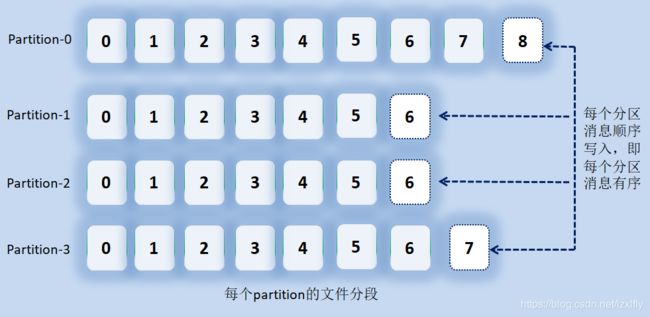
5.2、Partition的内部存储
每个Partition是通过Segment分段机制存储的,消息顺序追加到一个Partition下一个log日志文件中,同时并分配一个offset,即偏移量,offset是一个分区内的唯一标识,顺序递增,因此kafka中一个Partition下的消息是有序的
5.3、Partition的副本机制
为了保证消息的可靠性,kafka为分区引入了多副本Replica机制,通过增加副本数量提高容灾能力。一个分区中的所有副本统称为AR(Assigned Replicas),每个分区中有leader与follower两种角色副本,二者之间是主从关系,一个分区只有一个leader,通常多个follower。
下图是由3个副本组成的ISR集合,每个Partition一个leader和连个follower。

(1)分区的ISR集机制
所有与leader保持同步副本组成了ISR(In-Sync-Replicas),ISR集合是AR集合的一个子集。消息读写请求先发往leader,再同步到follower,在同步期间,follower副本较之leader往往具有一定的滞后,具体滞后标准参数可配置。与leader滞后过多的follower副本组成OSR(Out-of-Sync Replicas), 因此AR由ISR和OSR两部分组成。正常情况下,所有的follower副本都应该与leader副本保持一致,即没有滞后副本,OSR集合为空。
(2)leader对ISR的维护
leader负责维护和跟踪ISR集中所有follower副本的滞后状态,当follower滞后太多时,leader会把follower从ISR集中剔除掉,将其移入OSR集中,当滞后状态又重新追上leader时,再从OSR集中恢复到ISR集合中。当leader发生故障时,只有在ISR中集合的副本才有资格参与新leader的选举。
下图是follower副本都滞后leader,所有副本在图中中configs下的Replicas,在ISR中只剩下leader,滞后的follower副本在OSR中,不过OSR集合在Zookeeper查看时候并不展示

(3)有效消息水位-HW
HW:即High Watermark,俗称高水位,它标识了一个特定的消息偏移量(offset),在offset之前的消息才有效读取,消费者只能拉取到这个offset之前的消息。
LSO:Log Start Offset 即消息开始的Offset。
LEO:是Log End Offset的缩写,它标识当前日志文件中下一条待写入消息的offset,即当前分区中最后一条消息的offset值加1。分区中每个副本的都会维护自身的LEO,而ISR集合中副本中最小的LEO即为分区的HW。消费者只能消费HW水位之下的消息,即HW之下的消息被认为是可靠消息。
七、Kafka概念层常见面试问题
6.1、Kafka为什么要分区
如果一个Topic对应一个文件或多个文件,那消息只能分布在一个Broker之上 ,那么这个存储消息的文件(可能有多个)所对应的Broker机器的IO将成为性能瓶颈,而分区正是为了解决大量写下的单机IO瓶颈问题。每条消息被发送到Topic之前,会根据分区规则,有选择的存储在哪个分区,使消息不只是往一个Broker上写,就降低了单个Broker的IO写频率,也充分利用了多机提高了消息写入吞吐量。
6.2、Kafka的消息模式,主动pull or 被动接收push
Kafka采用的是:主动pull,即Producer将消息推送到broker,Consumer主动从broker拉取消息进行消费
原因主要有以下两点:
首先,主要是避免push模式下,当Producer推送的速率远大于Consumer消费的速率时,Consumer承受不住压力而崩溃或消息丢失而重新推送,浪费资源
再者,Push模式下,Broker不知道下游Consumer消费能力和消费策略的情况下,不知道采用立即推送单条消息还是缓存并批量推送,因此采用哪种策略可能都不合适。而Pull模式下,Consumer可以自主决定是否批量的从broker拉取数据,根据自己的消费能力去决定数据拉取策略。
6.3、Kafka为什么高效,吞吐量大
(1)Topic分区
不同分区分布在不同Broker上,解决大量写下的单机IO瓶颈问题,利用多机进行分布式存储来提高吞吐量。
(2)文件分段
(3)顺序读写
(4)缓冲并批量发送
(5)零拷贝
6.4、kafka如何保证消息不丢失
参见:https://blog.csdn.net/lzxlfly/article/details/106131162
6.5、kafka自身对幂等的支持, 如何处理幂等
为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和sequence_number。
Producer ID:生产者的唯一标识,每个新的Producer在初始化的时候会被分配一个唯一的PID,对用户隐藏。
SequenceNumbler:每个生产者,对同一个Topic下的不同分区,分别对应一个从0开始单调递增的SequenceNumber
对于Kafka来说,要解决的是生产者发送消息的幂等问题,即只要区分来自生产者的每条消息是否重复。
Kafka通过为每条消息增加一个SequenceNumbler(简称SN),一个Topic下分区的SN从0递增,SN保证了一个或多个生产者对一个Topic的同一个分区消息不重复
Broker端在缓存中保存了这SequenceNumber,对于接收的每条消息,如果其SN比Broker缓存中SN大于1,则接受它,否则将其丢弃。但是,只能保证单个Producer对于同一个