kylin简介
Kylin最大卖点是快,

传统大数据工具
并行计算
列式存储
索引
kylin采用了预计算
 source指的是数据仓库,Cube 指的是预先计算的值,target一般是Hbase,rowkey是各种聚合的参数,比如group by a。。
source指的是数据仓库,Cube 指的是预先计算的值,target一般是Hbase,rowkey是各种聚合的参数,比如group by a。。
用官方网站上下载的一张图来说明下

Kylin系统架构
kylin由以下几部分组成:
· REST Server:提供一些restful接口,例如创建cube、构建cube、刷新cube、合并cube等cube的操作,project、table、cube等元数据管理、用户访问权限、系统配置动态修改等。除此之外还可以通过该接口实现SQL的查询,这些接口一方面可以通过第三方程序的调用,另一方也被kylin的web界面使用。
· jdbc/odbc接口:kylin提供了jdbc的驱动,驱动的classname为org.apache.kylin.jdbc.Driver,使用的url的前缀jdbc:kylin:,使用jdbc接口的查询走的流程和使用RESTFul接口查询走的内部流程是相同的。这类接口也使得kylin很好的兼容tebleau甚至mondrian。
· Query引擎:kylin使用一个开源的Calcite框架实现SQL的解析,相当于SQL引擎层。
· Routing:该模块负责将解析SQL生成的执行计划转换成cube缓存的查询,cube是通过预计算缓存在hbase中,这部分查询是可以再秒级甚至毫秒级完成,而还有一些操作使用过查询原始数据(存储在hadoop上通过hive上查询),这部分查询的延迟比较高。
· Metadata:kylin中有大量的元数据信息,包括cube的定义,星状模型的定义、job的信息、job的输出信息、维度的directory信息等等,元数据和cube都存储在hbase中,存储的格式是json字符串,除此之外,还可以选择将元数据存储在本地文件系统。
· Cube构建引擎:这个模块是所有模块的基础,它负责预计算创建cube,创建的过程是通过hive读取原始数据然后通过一些mapreduce计算生成Htable然后load到hbase中。
--------------------------------
维度和度量简介:
简单来讲,维度就是观察数据的角度。比如电商的销售数据,可以从
时间的维度来观察(如图1-2的左侧所示),也可以进一步细化,从时间和
地区的维度来观察(如图1-2的右侧所示)。维度一般是一组离散的值,比
如时间维度上的每一个独立的日期,或者商品维度上的每一件独立的商
品。因此统计时可以把维度值相同的记录聚合在一起,然后应用聚合函
数做累加、平均、去重复计数等聚合计算。
度量就是被聚合的统计值,也是聚合运算的结果,它一般是连续的
值,如图1-2中的销售额,抑或是销售商品的总件数。通过比较和测算度
量,分析师可以对数据进行评估,比如今年的销售额相比去年有多大的
增长,增长的速度是否达到预期,不同商品类别的增长比例是否合理等

-------------------
星形模型
星型模型是数据挖掘种常用的几种多维度数据模型之一。他的特点是只有一张事实表,以及零到多个维度表,事实表和维度表通过主表外键相关联,维度表之间没有关联。
(注意在kylin中,维度表的主键是唯一的,并且事实表中,除了join的关联字段,不允许和维度表中的字段相同,并且维度表和维表之间字段也不能相同。并且事实表和维度表join关联的字段类型必须相同。这在构建cube的时候是经常会遇到错误。)
------------------
给定一个数据模型,我们找到所有可能的维度组合,对于N个维度来说,组合的可能性就有2^N种。对于每一种维度进行度量的聚合运算,将运算结果保存为一个物化视图,称之为:Cuboid。所有维度组合的Cuboid作为一个整体,我们称之为:Cube。所以一个Cube就是多种维度聚合度量的物化视图集。
假定有一些数据,维度有电话,时间和地址,那么cube就是如下图
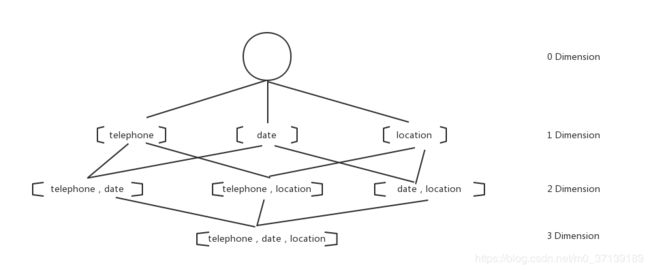
0维度和3维度的共有2个,1维度3个,2维度3个。共2^3 = 8个维度组合。
总结Kylin的工作流程:
1) 指定数据模型,定义维度和度量。
2) 预计算Cube,得到所有Cuboid并保存为物化视图。
3) 执行查询,读取Cuboid并计算,返回查询结果。
即,Kylin在查询时,不再去扫描原始数据集,万亿级数据的查询也可以提升到压秒级别。
但存储Cube所消耗的空间一般是原始数据集大小的20~100倍,即原始数据100GB,那么构建出的物化视图大概为20 * 100GB = 2TB。
那么显而易见,Kylin的使命就是OLAP(Online Analytical Processing),即,使得大数据分析快速而简洁。
------------------
增强构建和全量构建:

全量构建可以看作增量构建的一种特例:在全量构建中,Cube中只存在唯一的一个segment,该segment没有时间的概念,因此也就没有起始和结束时间。
Hive中有分区表的概念,kylin可以根据这一点进行增量构建。
增量构建需要进行segmeng合并
-------------
运维一些基础知识
元数据是Kylin中最重要的数据之一,备份元数据是运维工作中至关重要的环节。
本篇主要介绍如何备份Kylin元数据,方便数据恢复和迁移。
Kylin元数据介绍
Kylin组织所有的元数据(cube、cube_desc、model_desc、project、table等)作为一份层次的问加你系统,然而Kylin默认使用HBase来进行存储的,而不是普通的文件系统。
可以从Kylin的配置文件conf/kylin.properties中查看到:
## The metadata store in hbase
#kylin.metadata.url=kylin_metadata@hbase
kylin.metadata.url选项的指标是kylin的元数据被保存在HBase的kylin_metadata表中。
Kylin的元数据的相关操作
[root@hadoop2 bin]# ./metastore.sh
usage: metastore.sh backup
metastore.sh fetch DATA
metastore.sh reset
metastore.sh refresh-cube-signature
metastore.sh restore PATH_TO_LOCAL_META
metastore.sh list RESOURCE_PATH
metastore.sh cat RESOURCE_PATH
metastore.sh remove RESOURCE_PATH
metastore.sh clean [--delete true]
[root@hadoop2 bin]# ./metastore.sh backup
1.3 备份元数据
[root@hadoop2 bin]# ./metastore.sh backup
Starting backup to /usr/local/apps/kylin/meta_backups/meta_2018_05_25_15_11_32
Retrieving hadoop conf dir...
KYLIN_HOME is set to /usr/local/apps/kylin
Retrieving hive dependency...
Retrieving hbase dependency...
Retrieving hadoop conf dir...
Retrieving kafka dependency...
Retrieving Spark dependency...
Java HotSpot(TM) 64-Bit Server VM warning: Using incremental CMS is deprecated and will likely be removed in a future release
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/apps/apache-kylin-2.3.1-bin/tool/kylin-tool-2.3.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.13.3-1.cdh5.13.3.p0.2/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/apps/apache-kylin-2.3.1-bin/spark/jars/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
通过日志发现,备份元数据到本地目录和目录的命名格式:
/usr/local/apps/kylin/meta_backups/meta_2018_05_25_15_11_32
查看备份目录内容
[root@hadoop2 meta_2018_05_25_15_11_32]# ll
total 8
drwxr-xr-x 2 root root 50 May 25 15:11 acl
drwxr-xr-x 2 root root 29 May 25 15:11 cube
drwxr-xr-x 2 root root 29 May 25 15:11 cube_desc
drwxr-xr-x 3 root root 24 May 25 15:11 cube_statistics
drwxr-xr-x 3 root root 47 May 25 15:11 dict
drwxr-xr-x 2 root root 314 May 25 15:11 execute
drwxr-xr-x 2 root root 4096 May 25 15:11 execute_output
drwxr-xr-x 2 root root 39 May 25 15:11 model_desc
drwxr-xr-x 2 root root 33 May 25 15:11 project
drwxr-xr-x 2 root root 19 May 25 15:11 query
drwxr-xr-x 2 root root 172 May 25 15:11 table
drwxr-xr-x 2 root root 172 May 25 15:11 table_exd
drwxr-xr-x 4 root root 68 May 25 15:11 table_snapshot
drwxr-xr-x 2 root root 19 May 25 15:11 user
-rw-r--r-- 1 root root 38 Jan 1 1970 UUID
| 目录名 | 备份目录的内容 |
|---|---|
| project | 包含了项目的基本信息,项目所包含其他元数据类型的声明 |
| model_desc | 包含了描述数据模型基本信息,结构的定义 |
| cube_desc | 包含了描述Cuge模型基本信息,结构的定义 |
| cube | 包含了Cube实例的基本信息,以及下属Cube Segment的信息 |
| cube_statistics | 包含了Cuge实例的统计信息 |
| table | 包含了表的基本信息,如Hive信息 |
| table_exd | 包含了表的扩展信息,如维度 |
| table_snapshot | 包含了Lookup表的镜像 |
| dict | 包含了使用字典列的字典 |
| execute | 包含了Cube构建任务的步骤信息 |
| execute_output | 包含了Cube构建任务的步骤信息 |
恢复元数据
[root@hadoop2 bin]# ./metastore.sh reset
等恢复操作完成,可以在“Web UI”的“System”页面单击“Reload Metadata”按钮对元数据缓存进行刷新,即可看到最新的元数据。
垃圾清理:
Kylin在构建cube期间会在HDFS上生成中间文件;除此之外,当清理/删除/合并cube时,一些HBase表可能被遗留在HBase却以后再也不会被查询;虽然Kylin已经开始做自动化的垃圾回收,但不一定能覆盖到所有的情况;你可以定期做离线的存储清理:
步骤:
1. 检查哪些资源可以清理,这一步不会删除任何东西:
export KYLIN_HOME=/path/to/kylin_home
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete false请将这里的 (version) 替换为你安装的Kylin jar版本。
2. 你可以抽查一两个资源来检查它们是否已经没有被引用了;然后加上“–delete true”选项进行清理。
${KYLIN_HOME}/bin/kylin.sh org.apache.kylin.tool.StorageCleanupJob --delete true完成后,中间HDFS上的中间文件和HTable会被移除