编译原理实验一之词法分析程序设计与实现实验
实验内容
对一个简单语言的子集编制一个一遍扫描的词法分析程序。
实验目的
(1)理解词法分析在编译程序中的作用
(2)加深对有穷自动机模型的理解
(3)掌握词法分析程序的实现方法和技术
实验要求
(1)待分析的简单语言的词法
-
关键字
begin if then while do end -
运算符和界符
:= + - * / < <= > >= <> = ; ( ) # -
其他单词是标识符(ID)和整形常数(NUM),通过以下正规式定义:
ID=letter(letter|digit)*
NUM=digitdigit* -
空格由空白、制表符和换行符组成。空格一般用来分隔ID、NUM、运算符、界符和关键字,词法分析阶段通常被忽略。
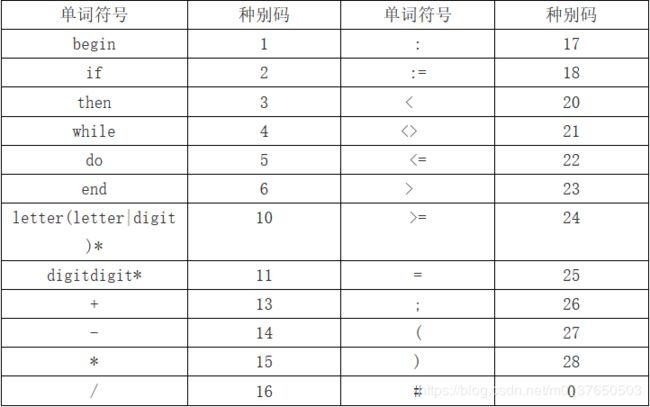
(2)各种单词符号对应的种别编码
(3)词法分析程序的功能
输入:所给文法的源程序字符串
输出:二元组(syn,token或sum)构成的序列。
syn为单词种别码;
token为存放的单词自身字符串;
sum为整形常数。
例如:对源程序begin x:=9;if x>0 then x:=2*x+1/3;end# 经词法分析后输出如下序列:(1,begin)(10,’x’) (18,:=) (11,9) (26, ; ) (2,if)……
#include如果遇到const char转char*的错误可以点击
如果遇到scanf不安全的问题可以点击
运行结果:

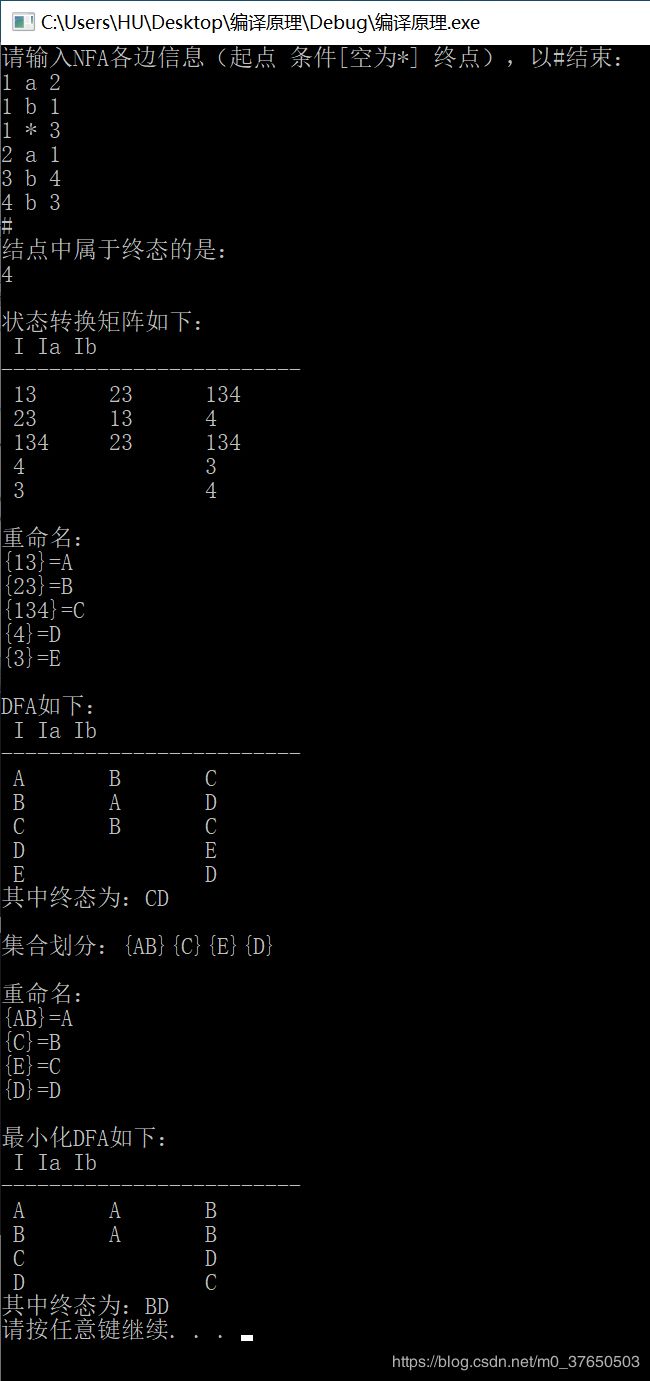
题目3: 把 NFA 确定化为 DFA 的算法 实现
设计内容及要求:构造一程序,实现:将给定的NFA M( 其状态转换矩阵及初态、终态信息保存在指定文件中)确定化为 DFA M,输出 DFA M 其状态转换 矩阵及初 态、终态信息保存在指定文件中 。
#include
for (i = 0; i < N; i++)
{
if (NODE.find(b[i].first) > NODE.length())
NODE += b[i].first;
if (NODE.find(b[i].last) > NODE.length())
NODE += b[i].last;
if ((CHANGE.find(b[i].change) > CHANGE.length()) && (b[i].change != "*"))
CHANGE += b[i].change;
}
len = CHANGE.length();
cout << "结点中属于终态的是:" << endl;
cin >> endnode;
for (i = 0; i < endnode.length(); i++)
if (NODE.find(endnode[i]) > NODE.length())
{
cout << "所输终态不在集合中,错误!" << endl;
return;
}
//cout<<"endnode="<
chan *t = new chan[MAXS];
t[0].ltab = b[0].first;
h = 1;
eclouse(b[0].first[0], t[0].ltab, b);//求e-clouse
//cout<
for (i = 0; i < h; i++)
{
for (j = 0; j < t[i].ltab.length(); j++)
for (m = 0; m < len; m++)
eclouse(t[i].ltab[j], t[i].jihe[m], b);//求e-clouse
for (k = 0; k < len; k++)
{
//cout<";
move(t[i], k, b);//求move(I,a)
//cout<
for (j = 0; j < t[i].jihe[k].length(); j++)
eclouse(t[i].jihe[k][j], t[i].jihe[k], b);//求e-clouse
}
for (j = 0; j < len; j++)
{
paixu(t[i].jihe[j]);//对集合排序以便比较
for (k = 0; k < h; k++)
{
flag = operator==(t[k].ltab, t[i].jihe[j]);
if (flag)
break;
}
if (!flag&&t[i].jihe[j].length())
t[h++].ltab = t[i].jihe[j];
}
}
cout << endl << "状态转换矩阵如下:" << endl;
outputfa(len, h, t);//输出状态转换矩阵
//状态重新命名
string *d = new string[h];
NODE.erase();
cout << endl << "重命名:" << endl;
for (i = 0; i < h; i++)
{
sta = t[i].ltab;
t[i].ltab.erase();
t[i].ltab = 'A' + i;
NODE += t[i].ltab;
cout << '{' << sta << "}=" << t[i].ltab << endl;
for (j = 0; j < endnode.length(); j++) {
if (sta.find(endnode[j]) < sta.length())
d[1] = ednode += t[i].ltab;
}
for (k = 0; k < h; k++) {
for (m = 0; m < len; m++) {
if (sta == t[k].jihe[m])
t[k].jihe[m] = t[i].ltab;
}
}
}
for (i = 0; i < NODE.length(); i++) {
if (ednode.find(NODE[i]) > ednode.length())
d[0] += NODE[i];
}
endnode = ednode;
cout << endl << "DFA如下:" << endl;
outputfa(len, h, t);
//输出DFA
cout << "其中终态为:" << endnode << endl;//DFA最小化
m = 2;
sta.erase();
flag = 0;
for (i = 0; i < m; i++)
{
//cout<<"d["<
for (k = 0; k < len; k++)
{
//cout<<"I"<
y = m;
for (j = 0; j < d[i].length(); j++)
{
for (n = 0; n < y; n++)
{
if (d[n].find(t[NODE.find(d[i][j])].jihe[k]) < d[n].length() || t[NODE.find(d[i][j])].jihe[k].length() == 0)
{
if (t[NODE.find(d[i][j])].jihe[k].length() == 0)
x = m;
else
x = n;
if (!sta.length())
{
sta += x + 48;
}
else
if (sta[0] != x + 48)
{
d[m] += d[i][j];
flag = 1;
d[i].erase(j, 1);
//cout<
j--;
}
break;
//跳出n
}
}//n
}//j
if (flag)
{
m++; flag = 0;
}
//cout<<"sta="<
sta.erase();
}//k
}//i
cout << endl << "集合划分:";
for (i = 0; i < m; i++)
cout << "{" << d[i] << "}";
cout << endl;
//状态重新命名
chan *md = new chan[m];
NODE.erase();
cout << endl << "重命名:" << endl;
for (i = 0; i < m; i++)
{
md[i].ltab = 'A' + i;
NODE += md[i].ltab;
cout << "{" << d[i] << "}=" << md[i].ltab << endl;
}
for (i = 0; i < m; i++)
for (k = 0; k < len; k++)
for (j = 0; j < h; j++)
{
if (d[i][0] == t[j].ltab[0])
{
for (n = 0; n < m; n++)
{
if (!t[j].jihe[k].length())
break;
else if (d[n].find(t[j].jihe[k]) < d[n].length())
{
md[i].jihe[k] = md[n].ltab;
break;
}
}
break;
}
}
ednode.erase();
for (i = 0; i < m; i++)
for (j = 0; j < endnode.length(); j++)
if (d[i].find(endnode[j]) < d[i].length() && ednode.find(md[i].ltab))
ednode += md[i].ltab;
endnode = ednode;
cout << endl << "最小化DFA如下:" << endl;
outputfa(len, m, md);
cout << "其中终态为:" << endnode << endl;
system("pause");
}
运行结果: