用python抓取表格数据并导出到excel文件中
代码不长,当作笔记吧,用到的库有:requests,pandas,numpy,BeautifulSoup.
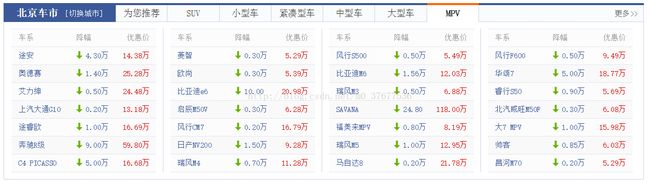
抓取汽车之家的优惠模块如图:
打开chrome的检查,ctl+shift+c找到这个表格区域:
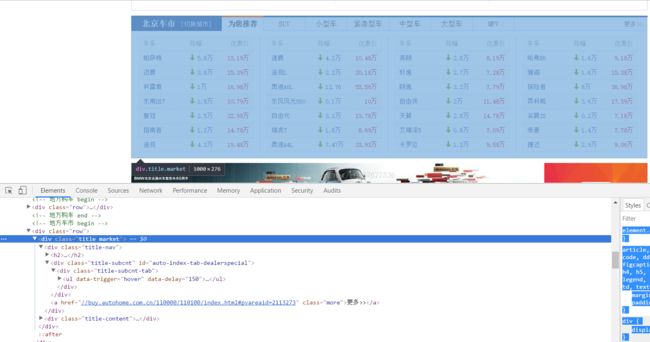
可以看到就是class="title_market" 这个div 通过python的BeautifulSoup这个解析定位到div
for i in soup.body.find_all("div", attrs={"class": "title market"}): # 定位到优惠促销区域按照此方法分别找到车型,降价金额,销售金额等对应的表中元素div 然后遍历list进行分别处理,下面是完全代码:
import requests import pandas as pd import numpy as np from bs4 import BeautifulSoup URL = 'http://www.autohome.com.cn/beijing/' def get_data(): response = requests.get(URL) if response.status_code == 200: html = response.content soup = BeautifulSoup(html, 'lxml') for i in soup.body.find_all("div", attrs={"class": "title market"}): # 定位到优惠促销区域 df = pd.DataFrame(np.empty((0, 0)))# df用于存储所有信息 初始化 row = 0 #用于下面取数组当中的值 for tempData in i.find_all("div", attrs={"class":"market-text01"}): #车型 titleArr = tempData.find_all('a') downDataArr = i.find_all("div", attrs={"class":"market-text02"}) #降价金额 priceDataArr = i.find_all("div", attrs={"class": "market-text03"}) #价格 if titleArr: #数组为空的是标题直接忽略 data = pd.DataFrame(np.empty((1, 3))) title = titleArr[0].get_text() down = downDataArr[row].get_text() price = priceDataArr[row].get_text() data.ix[0,0]=title data.ix[0,1]=down data.ix[0,2]=price df=df.append(data) #数据追加到矩阵中后面一块写入excel row = row+1 df.index = range(len(df)) df=df.drop(0) df.columns=['车型','优惠金额','价格'] df.to_csv('.\优惠表.csv',index=False) #表格保存在项目目录下 else: return None def main(): get_data() if __name__ == '__main__': main()运行结果:
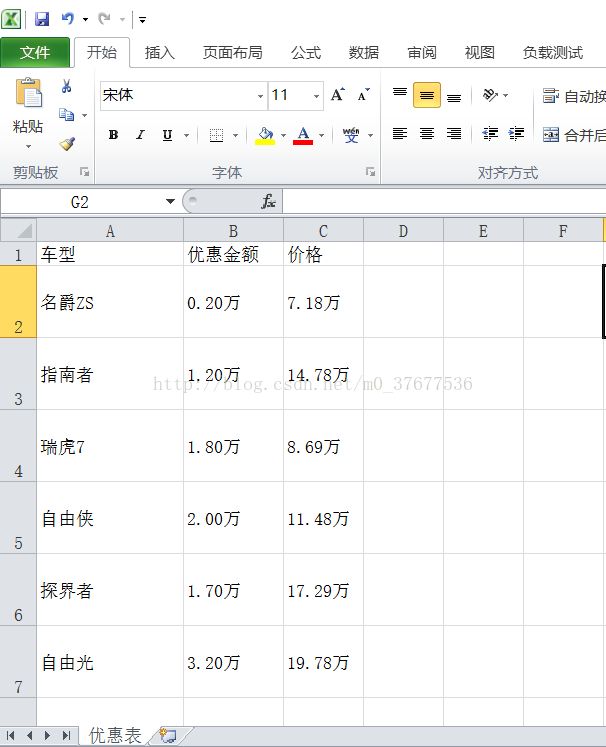
环境配好代码可以直接运行。