Efficient Object Instance Search Using Fuzzy Objects Matching
这篇文章《Efficient Object Instance Search Using Fuzzy Objects Matching》2017年发在AAAI上。
作者提出了一种有效的目标实例检索方法----Fuzzy Objects Matching (FOM)。
一般来说,实例检索将query图像与数据集图像产生的众多proposals进行一一匹配。但这种方法很明显时间复杂度很高。而且同一张图像的proposals常常有重叠,所以可以通过减少这种冗余计算来提高匹配准确率和效率。
Fuzzy Objects 的编码和匹配
1. 编码
对于数据集中的某一张图像 I,通过Edgeboxes方法得到n个proposals,记为pi (1<=i<=n)。
将proposals调整为同样大小,输入到CNN网络。
提取到某一层的feature map。实验中用的是VGG-16网络,提取conv5_3层的feature map。
假设feature map的维度是W*H*d,对每个卷积核产生的W*H大小进行pooling或者聚合。(类似R-MAC)。
pooling或聚合的方法共有四种:maxpooling、sumpooling、bilinearpooling、VLAD。
至此,每个proposal可以得到局部卷积特征Pi,维度为d*1。来自于同一张图像的n个proposals得到的所有特征记为P,维度为d*n。
记待查询图像的特征为q。则利用点积计算待查询和P的相似性得分:
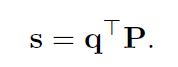
s是一个1*n的矩阵,其中每一个数可以看做是query object分别和每一个proposal的相似性得分。
(所以以上过程可以看做是穷举式的object proposals匹配方法)
为了更高效地获得与proposals的相似性,在本文中,作者将属于同张图像的n个proposals的特征通过k-mediods聚类于 t 个聚类中心。
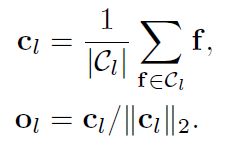
由公式可以看出,首先将属于某个聚类中心的所有proposals的特征进行加和,然后取平均,形成这个聚类中心的特征。对该特征进行L2-normalization,就可以得到fuzzy object 的特征表示:o。
一个聚类中心产生一个fuzzy object,将所有fuzzy object的特征集合记为O,维度是d*t。
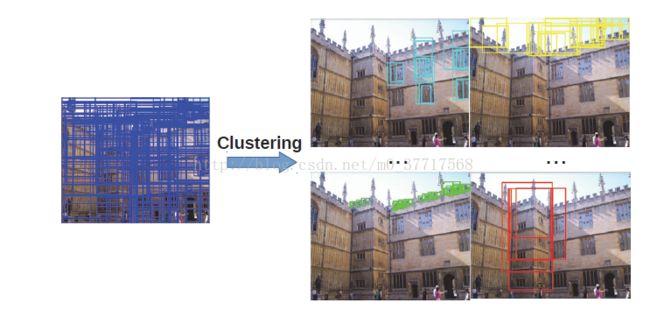
为何要聚类?论文给出了聚类的效果,可以将比较相似的proposals归为一种:
通过之前求得的proposals特征集合P,求一个矩阵H,使其满足以下公式:
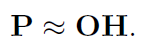
proposal的特征 = 几个fuzzy object的特征 * 稀疏的线性码。
左边的proposals特征矩阵P:每一列代表了一个proposal的特征
右边的fuzzy objects特征矩阵O:每一列代表了一个fuzzy object的特征
矩阵H中第i列代表了第i个proposal与所有fuzzyobject的线性关系。

用图的形式可以表示为:

2. 匹配
引入fuzzy object概念之后,待查询object和proposal之间的相似性计算可以改写为:
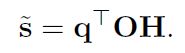
query object和proposal的相似性得分 = query object和fuzzy objects的相似性得分 * 相应稀疏的线性码。
从而,计算query object和某个proposal的相似性得分,只需计算和所有fuzzy object的相似性得分,再根据邻近关系确定query object和这个proposal的相似性得分。比如在论文中,proposal的数量是300,而fuzzy object的数量是20,计算相似性的点积计算量可以明显减少。
待查询object与图像 I 的相似性得分为:属于该图像的n个proposals中,与待查询object相似性得分最高的:
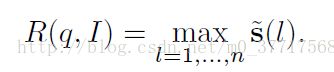
数据集中的所有图像根据得分R进行排序(论文中貌似没有提及这个排序的作用)。
Fuzzy Objects Refinement
1. intra-image fuzzy object
即以上过程产生的fuzzy object。其融合的是属于同一张图像的proposals。
2. inter-image fuzzy object
为了让fuzzy object加入局部约束,进一步提高检索准确率,将每一个fuzzy object:o作为伪查询,检索数据集中和它最相似的m个fuzzy object,接着进行加和取平均,表示为新的fuzzy object:
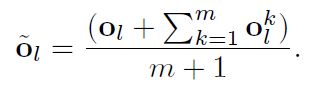
该法比average query expansion(AQE)好的地方在于,不需要query参与计算,是一个线下计算过程,不会消耗多余的检索时间。而且还可以与query共同作用。
注意与o最相似的m个fuzzy object可以来自数据集中不同的图像。
此时,query和proposals的相似性计算公式为:
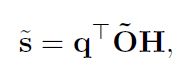
其中只调整了o,H与之前保持一致。
实验
proposals的大小调整为448*448输入到VGG-16网络
提取conv5_3特征,feature map大小为28*28*512
比较四种pooling方式:maxpooling、sumpooling、bilinearpooling、VLAD。
其中VLAD的聚类中心数目为64。四种聚合的特征经过PCA、白化、L2-normalization固定为512维。
1. 与Exhaustive Object Proposals Matching(EOPM)的比较

对于Fuzzy Objects Matching(FOM)方法,提出300个proposals再进行不同数量的fuzzy objects比较。
由实验结果可以看出,FOM方法在mAP上优于EFOM方法。
FOM方法的mAP随着fuzzy objects数量的增加而增加。
2. 与其他加快匹配速度方法的比较
主要与Representative Object Matching(ROM)和Sparse Coding Matching (SCM)两种方法进行了比较。
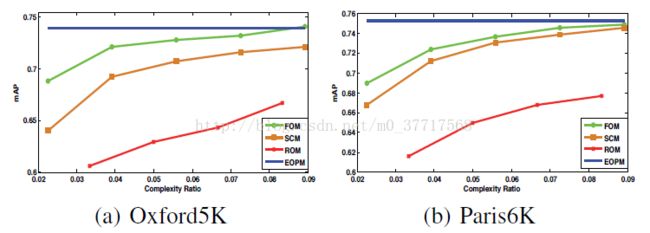
其中横轴Complexity Ratio代表计算复杂度。每个方法的定义稍有不同,详见paper。
实验结果说明,在相同的计算复杂度情况下,FOM的mAP优于其它方法。其原因是FOM的方法有其它方法不具有的局部约束性质。
3. Intra-imagefuzzy objects和Inter-imagefuzzy objects 方法比较
实验设置:每张图像提取300个proposals;聚类为20个fuzzy objects;neighborhood的数量m取20。
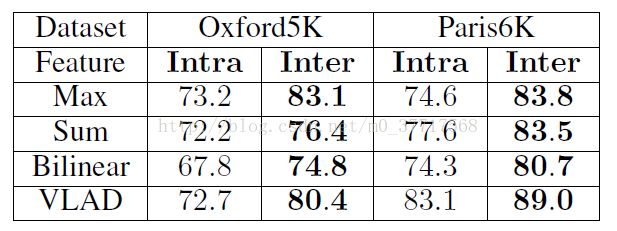
由实验结果可以看出,Inter-image fuzzy objects的方法在两个数据集上、四种聚合方法中表现的都优于Intra-image fuzzy objects方法。
4. 查询扩展 - Average Query Expansion(AQE)
将查询图像和与其最相似的s个fuzzy objects的特征进行取平均,作为新的查询。
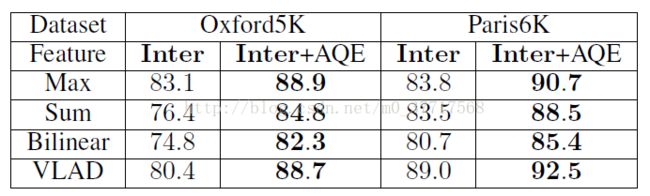
和预想中的一致,AQE可以在一定程度上提高mAP。
5. 与其它方法的对比
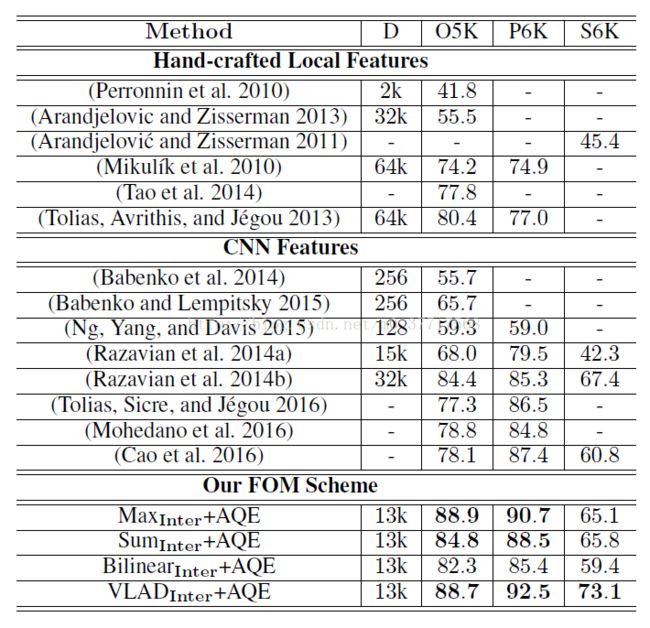
由实验结果可以看出,本文提出的FOM方法在mAP方面优于其它方法。