因为 In Opencv 3 API version the cv2.findCoutours() returns 3 object
- image
- contours
- hierarchy
我的论文方向目前是使用单目摄像头实现机器人对人的跟随,首先单目摄像头与kinect等深度摄像头最大的区别是无法有效获取深度信息,那就首先从这方面入手,尝试通过图像获取摄像头与人的距离。
在网上看了几天关于摄像头标定和摄像头焦距等原理的文章,然后通过这篇文章真正启发了我:用python和opencv来测量目标到相机的距离 主要的测距的原理是利用相似三角形计算物体到相机的距离。
在这里我的环境为: Ubuntu14.04 + Opencv2.4.9
我们将使用相似三角形来计算相机到一个已知的物体或者目标的距离。
相似三角形就是这么一回事:假设我们有一个宽度为 W 的目标或者物体。然后我们将这个目标放在距离我们的相机为 D 的位置。我们用相机对物体进行拍照并且测量物体的像素宽度 P 。这样我们就得出了相机焦距的公式:
F = (P x D) / W
举个例子,假设我在离相机距离 D = 24 英寸的地方放一张标准的 8.5 x 11 英寸的 A4 纸(横着放;W = 11)并且拍下一张照片。我测量出照片中 A4 纸的像素宽度为 P = 249 像素。
因此我的焦距 F 是:
F = (248px x 24in) / 11in = 543.45
当我继续将我的相机移动靠近或者离远物体或者目标时,我可以用相似三角形来计算出物体离相机的距离:
D’ = (W x F) / P
为了更具体,我们再举个例子,假设我将相机移到距离目标 3 英尺(或者说 36 英寸)的地方并且拍下上述的 A4 纸。通过自动的图形处理我可以获得图片中 A4 纸的像素距离为 170 像素。将这个代入公式得:
D’ = (11in x 543.45) / 170 = 35 英寸
或者约 36 英寸,合 3 英尺。
从以上的解释中,我们可以看到,要想得到距离,我们就要知道摄像头的焦距和目标物体的尺寸大小,这两个已知条件根据公式:
D’ = (W x F) / P
得出目标到摄像机的距离D,其中P是指像素距离,W是A4纸的宽度,F是摄像机焦距。
在原文中,是通过预先拍照,根据第一张照片算出摄像头的焦距,在根据已知的焦距算出接下来的照片中白纸到摄像机的距离,这样不太直观,而且需要预先拍照,我将源程序改为实时测距,简单来说就是将原来的读入照片变为读摄像头,这样的效果看起来比较直观.源程序如下:
#!usr/bin/python
# -*- coding: utf-8 -*-
#定义编码,中文注释
#import the necessary packages
import numpy as np
import cv2
# 找到目标函数
def find_marker(image):
# convert the image to grayscale, blur it, and detect edges
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (5, 5), 0)
edged = cv2.Canny(gray, 35, 125)
# find the contours in the edged image and keep the largest one;
# we'll assume that this is our piece of paper in the image
(cnts, _) = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)
# 求最大面积
c = max(cnts, key = cv2.contourArea)
# compute the bounding box of the of the paper region and return it
# cv2.minAreaRect() c代表点集,返回rect[0]是最小外接矩形中心点坐标,
# rect[1][0]是width,rect[1][1]是height,rect[2]是角度
return cv2.minAreaRect(c)
# 距离计算函数
def distance_to_camera(knownWidth, focalLength, perWidth):
# compute and return the distance from the maker to the camera
return (knownWidth * focalLength) / perWidth
# initialize the known distance from the camera to the object, which
# in this case is 24 inches
KNOWN_DISTANCE = 24.0
# initialize the known object width, which in this case, the piece of
# paper is 11 inches wide
# A4纸的长和宽(单位:inches)
KNOWN_WIDTH = 11.69
KNOWN_HEIGHT = 8.27
# initialize the list of images that we'll be using
IMAGE_PATHS = ["Picture1.jpg", "Picture2.jpg", "Picture3.jpg"]
# load the furst image that contains an object that is KNOWN TO BE 2 feet
# from our camera, then find the paper marker in the image, and initialize
# the focal length
#读入第一张图,通过已知距离计算相机焦距
image = cv2.imread(IMAGE_PATHS[0])
marker = find_marker(image)
focalLength = (marker[1][0] * KNOWN_DISTANCE) / KNOWN_WIDTH
#通过摄像头标定获取的像素焦距
#focalLength = 811.82
print('focalLength = ',focalLength)
#打开摄像头
camera = cv2.VideoCapture(0)
while camera.isOpened():
# get a frame
(grabbed, frame) = camera.read()
marker = find_marker(frame)
if marker == 0:
print(marker)
continue
inches = distance_to_camera(KNOWN_WIDTH, focalLength, marker[1][0])
# draw a bounding box around the image and display it
box = np.int0(cv2.cv.BoxPoints(marker))
cv2.drawContours(frame, [box], -1, (0, 255, 0), 2)
# inches 转换为 cm
cv2.putText(frame, "%.2fcm" % (inches *30.48/ 12),
(frame.shape[1] - 200, frame.shape[0] - 20), cv2.FONT_HERSHEY_SIMPLEX,
2.0, (0, 255, 0), 3)
# show a frame
cv2.imshow("capture", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
camera.release()
cv2.destroyAllWindows()
程序效果图如下:
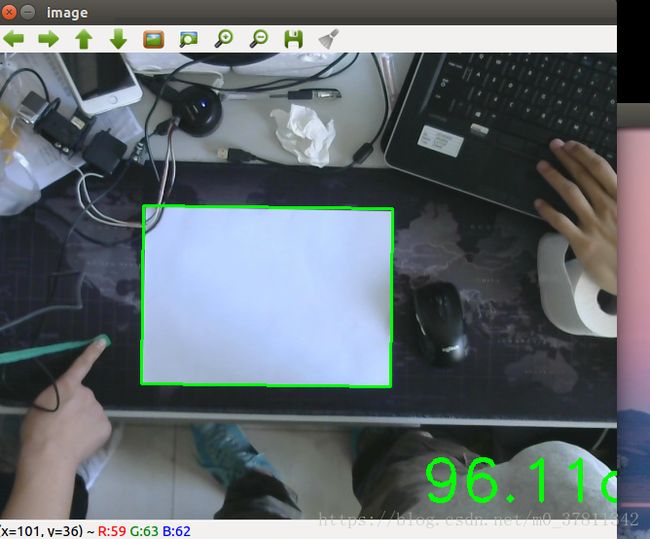
在这张图里我摄像头距离桌面大概100cm,可以看到图中距离为96cm,可以看到精度还可以。
需要注意的是, 如果使用的是opencv3的版本,
1. 需要将find_marker函数中
(cnts, _) = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)改为:
(_, cnts, _) = cv2.findContours(edged.copy(), cv2.RETR_LIST, cv2.CHAIN_APPROX_SIMPLE)因为 In Opencv 3 API version the cv2.findCoutours() returns 3 object
2. 需要将:
box = np.int0(cv2.cv.BoxPoints(marker))改为:
box = cv2.boxPoints(marker)
box = np.int0(box)存在的问题:
1. 程序在运行时在未检测到A4纸时有时候会报错:
Traceback (most recent call last):ValueError: max() arg is an empty sequence
目前关于这个错误,我还没有解决,猜测主要是由于没有检测到目标造成max()函数为空的原因,不过没有深究。
2. 程序是通过第一张图已知目标到相机的距离来计算摄像头焦距,然后再通过焦距计算接下来目标到摄像头的距离,在这里焦距是一个关键的参数,所以我准备尝试通过对摄像头的标定直接获取相机的像素焦距,我是通过ros的一个包实现了对相机的标定,不过通过相机标定得出的像素焦距计算出来的距离并没有通过第一张图片计算出的焦距计算出来的距离准确,这个具体原因也没有搞明白,可能是我标定的结果不够准确?
3. 在通过摄像头测距时, 得出的距离也是准确且随着摄像头距离桌面远近而线性变化的,但距离偶尔会出现突变,目前也没找到是什么原因造成的.
ros相机标定主要参考的是这篇博客,博主是白巧克力亦唯心,ROS大神:
这里主要记录的是,通过摄像机标定,得到的3*3的内参数矩阵,其中M[1][1]和M[2][2]分别为我们要求的相机的x,y轴的像素焦距。
在第一部分中我们已经计算出了A4纸距离相机的距离,在具体应用中,我需要计算的是人距离相机的距离,来实现机器人对目标人距离的判断,应用与对目标人的跟随。在这里主要的思路是先通过opencv中的HOG方法检测到人,再根据人的预估身高和摄像头焦距计算人到摄像机的距离。在这里选择身高的原因在于人的身高在不同方向上变化较小,而且我们的摄像头高度是固定的,所以选择身高。
1.首先要使用opencv进行行人检测:
#!usr/bin/python
# -*- coding: utf-8 -*-
# import the necessary packages
from __future__ import print_function
from imutils.object_detection import non_max_suppression
from imutils import paths
import numpy as np
import argparse
import imutils
import cv2
cap = cv2.VideoCapture(0)
# initialize the HOG descriptor/person detector
hog = cv2.HOGDescriptor()
# 使用opencv默认的SVM分类器
hog.setSVMDetector(cv2.HOGDescriptor_getDefaultPeopleDetector())
while(1):
# get a frame
ret, frame = cap.read()
frame = imutils.resize(frame, width=min(400, frame.shape[1]))
# detect people in the image
(rects, weights) = hog.detectMultiScale(frame, winStride=(4, 4),
padding=(8, 8), scale=1.05)
rects = np.array([[x, y, x + w, y + h] for (x, y, w, h) in rects])
# 非极大抑制 消除多余的框 找到最佳人体
pick = non_max_suppression(rects, probs=None, overlapThresh=0.65)
# 画出边框
for (xA, yA, xB, yB) in pick:
cv2.rectangle(frame, (xA, yA), (xB, yB), (0, 255, 0), 2)
# show a frame
cv2.imshow("capture", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows() 2.将行人检测与测距代码结合:
while camera.isOpened():
# get a frame
(grabbed, frame) = camera.read()
# 如果不能抓取到一帧,说明我们到了视频的结尾
if not grabbed:
break
frame = imutils.resize(frame, width=min(400, frame.shape[1]))
#marker = find_marker(frame)
marker = find_person(frame)
#inches = distance_to_camera(KNOWN_WIDTH, focalLength, marker[1][0])
for (xA, yA, xB, yB) in marker:
cv2.rectangle(frame, (xA, yA), (xB, yB), (0, 255, 0), 2)
ya_max = yA
yb_max = yB
pix_person_height = yb_max - ya_max
if pix_person_height == 0:
#pix_person_height = 1
continue
print (pix_person_height)
#print (pix_person_height)
inches = distance_to_camera(KNOW_PERSON_HEIGHT, focalLength, pix_person_height)
print("%.2fcm" % (inches *30.48/ 12))
# draw a bounding box around the image and display it
#box = np.int0(cv2.cv.BoxPoints(marker))
#cv2.drawContours(frame, [box], -1, (0, 255, 0), 2)
cv2.putText(frame, "%.2fcm" % (inches *30.48/ 12),
(frame.shape[1] - 200, frame.shape[0] - 20), cv2.FONT_HERSHEY_SIMPLEX,
2.0, (0, 255, 0), 3)
# show a frame
cv2.imshow("capture", frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break3.存在的问题:
目前使用HOG检测行人的效果不是很好,会把类似人体形状的物体都框出来,比如实验室的三脚架等物体,受背景干扰较大。程序中存在一个bug就是在没有检测到人时,pix_person_height会为0,这样分母为0时无法计算,在接下来我也要通过3个方面改进,首先要想办法进一步改进人体检测,使用YOLO的方法目前是比较好的,但在CPU下速度较慢。然后要改进的是精度,这里需要主要的是选择摄像头要选择固定焦距的摄像头,自动变焦摄像头焦距会变化,测量的距离也会变。最后就是尽可能完善程序,减少bug。
4 . 将要进行的工作
通过程序可以看到使用单目摄像头检测人到摄像头的距离,其中一个影响较大的因素是对人体的准确检测,如果想要使测量的距离准确(完全准确是不可能的,但要达到可以用于机器人跟随人的功能的程度),那就要尽可能的准确的检测出人,通过我的测试,在准确知道目标人的身高前提下,在离摄像头固定距离上对人拍照,然后手动对人进行画框,标定出目标人的在画面中的高度,通过计算,得到的距离比较准确,其精度完全是可以接受的,所以接下来的工作主要是如何通过程序来准确的框出目标人来获取其在图像中的高度。
程序的源码已经上面已经贴出,也可以到下载页面下载。