基于豆瓣爬取的电影数据所做的分析(练习)
数据来源是知乎乎友做完数据分析展示,分享提供的。我们来学习一下。
数据项有:豆瓣评论数,豆瓣评分,上映日期,主演,制片国家或者地区,别名,导演,片长,类型,编剧,语言。一共大概有两千多条数据。不是特别的多。
我们首先来根据评分判断一下,是否服从正太分布。
fig = plt.figure(figsize = (10,6))
plt.subplots_adjust(hspace=0.2)
ax1 = fig.add_subplot(2,1,1)
df['豆瓣评分'].plot.hist(stacked=True,bins=50,color = 'green',alpha=0.5,grid=True)
plt.ylim([0,150])
plt.title('豆瓣评分数据分布-直方图')
ax2 = fig.add_subplot(2,1,2)
color = dict(boxes='DarkGreen', whiskers='DarkOrange', medians='DarkBlue', caps='Gray')
df['豆瓣评分'].plot.box(vert=False, grid = True,color = color)
plt.title('豆瓣评分数据分布-箱型图')
df['豆瓣评分'].describe()
u = df['豆瓣评分'].mean()
std = df['豆瓣评分'].std()
stats.kstest(df['豆瓣评分'], 'norm', (u, std))这里得到的p值大于0.05,说明是符合正态分布的。
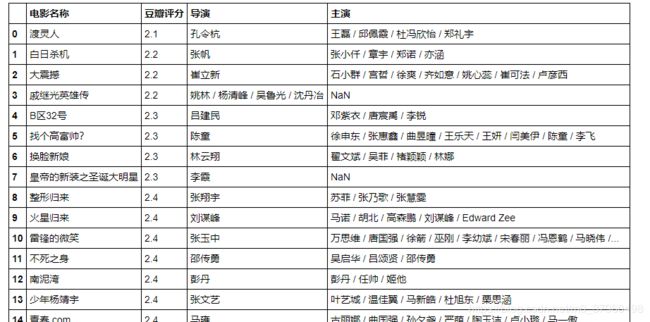
来看看烂片有哪些,判断的标准是评分<4
data_lp = df[df['豆瓣评分']<4].reset_index()
print('数据整理后,得到烂片数据量为%i条' % len(data_lp))
# 筛选烂片数据
lp_top20 = data_lp[['电影名称','豆瓣评分','导演','主演']].sort_values(by = '豆瓣评分').iloc[:20].reset_index()
del lp_top20['index']
得到的结果如下。还好,基本都没有看过。。。。
继续探究,什么的题材比较拍烂片。这是个有趣的问题,看看大部分的烂片是什么类型的,那国产这一列的电影在感看的时候就要小心 了,因为一不小心就有可能碰到烂片。
typelst = []
for i in df[df['类型'].notnull()]['类型'].str.replace(' ','').str.split('/'):
typelst.extend(i)
typelst = list(set(typelst))
print(typelst)
lst_type_lp = []
df_type = df[df['类型'].notnull()][['电影名称','豆瓣评分','类型']]
def f1(data,typei):
dic_type_lp = {}
datai = data[data['类型'].str.contains(typei)]
lp_pre_i = len(datai[datai['豆瓣评分']<4.3])/len(datai)
dic_type_lp['typename'] = typei
dic_type_lp['typecount'] = len(datai)
dic_type_lp['type_lp_pre'] = lp_pre_i
return(dic_type_lp)
for i in typelst:
dici = f1(df_type,i)
lst_type_lp.append(dici)
df_type_lp = pd.DataFrame(lst_type_lp)
type_lp_top20 = df_type_lp.sort_values(by = 'type_lp_pre',ascending = False).iloc[:20]
#得到top20结果如下
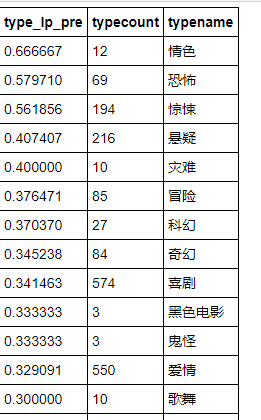
这个结果比较尴尬,,,,看来某岛国在这方面要领先我们很多,我们的进步空间很大~-~
然后我们再来调查一个问题,烂片的主演有哪些?? 顺便也做一个top20看看。
lst_role_lp = []
for i in leadrolelst:
datai = df_role2[df_role2['主演'].str.contains(i)]
if len(datai) >2:
dic_role_lp = {}
lp_pre_i = len(datai[datai['豆瓣评分']<4])/len(datai)
dic_role_lp['role'] = i
dic_role_lp['rolecount'] = len(datai)
dic_role_lp['role_lp_pre'] = lp_pre_i
lst_role_lp.append(dic_role_lp)
df_role_lp = pd.DataFrame(lst_role_lp)
role_lp_top20 = df_role_lp.sort_values(by = 'role_lp_pre',ascending = False).iloc[:20]
得到的结果如下
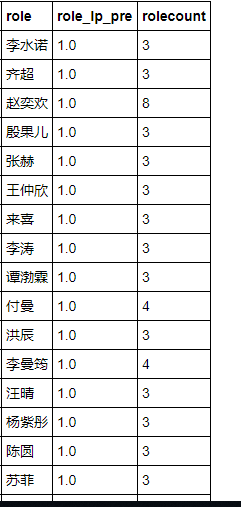
结果也有些意外,基本上全都没有听说过。看来群众的眼睛果然是锃亮的,哈哈哈哈哈。
#以上,供大家参考。