牛客网各类面经总结
为什么在重写 equals方法的同时必须重写 hashcode方法
这样如果我们对一个对象重写了euqals,意思是只要对象的成员变量值都相等那么euqals就等于true,但不重写hashcode,那么我们再new一个新的对象,当原对象.equals(新对象)等于true时,两者的hashcode却是不一样的,由此将产生了理解的不一致,如在存储散列集合时(如Set类),将会存储了两个值一样的对象(hash是先根据hashcode值进行存储地址的查找,因此有可能将两个equals相等的方法放在一起),导致混淆,因此,就也需要重写hashcode()mybatis相对于Hibernate来说的优点
mybatis门槛较低更容易掌握
mybatis可以进行sql优化,自己编写sql可以指定查询字段
hibernate优势:
hibernate的dao层开发比mybatis简单,mybatis需要维护sql和结果映射
hibernate对对象的维护和缓存要比mybatis好,对增删改查的对象维护要方便
hibernate数据库移植性好,mybatis不同的数据库要写不同的sql,移植性差
垃圾回收算法
cms四部曲
一、初始标记:此时标记需要用户线程停下来;
二、并发标记:此时标记可以和用户线程一起运行;
三、重新标记:此时标记需要用户线程停下来,主要母的是为了对并发标记的垃圾进行审核;
四、并发清除:与用户线程一起与运行进行垃圾清除;
缺点:
1、CMS收集器对cpu资源非常敏感;
2、CMS收集器无法清除浮动垃圾
3、CMS基于标记清除的算法实现的,所以内存碎片会产生过多。
G1收集器的四部曲:
1、初始标记:标记GC Root能直接关联的对象,并且修改TAMS的值,让下一阶段的用户进行并发运行是,能够正确运用Region创建新对象,这阶段需要停顿,但停顿时间很短
2、并发标记:从GC Root开始对堆进行可达性分析,找出存活的对象,这段耗时较长,但可以与用户线程并发执行。
3、最终标记:是为了修正在并发标记阶段因用户程序继续运作导致标记产生变动的那一部分的标记记录,虚拟机将这部分标记记录在线程Remembered Set中,这阶段需要停顿线程,但是可并行执行。
4、筛选回收:首先对各个Region的回收价值和成本进行排序,根据用户所期待的GC停顿时间来制定回收计划,这个阶段也可以与用户线程并行执行,但由于只回收一部分的Region,时间是用户可控制的,而且停顿用户线程将大幅度提高收集效率。
Session和Cookie的底层原理
用户会提供个人信息并且提交至服务器;
服务器在向客户端回传相应的超文本的同时也会发回这些个人信息,存放于HTTP响应头(Response Header);
当客户端浏览器接收到来自服务器的响应之后,浏览器会将这些信息存放在一个统一的位置
客户端再向服务器发送请求的时候,都会把相应的Cookie再次发回至服务器。Cookie信息则存放在HTTP请求头(Request Header)了。
服务器端程序运行的过程中创建Session,在Java中是通过调用HttpServletRequest的getSession方法(使用true作为参数)创建的。
服务器会为该Session生成唯一的Session id,而这个Session id在随后的请求中会被用来重新获得已经创建的Session;
在Session被创建之后,就可以调用Session相关的方法往Session中增加内容了,而这些内容只会保存在服务器中,发到客户端的只有Session id;
当客户端再次发送请求的时候,会将这个Session id带上,服务器接受到请求之后就会依据Session id找到相应的Session,从而再次使用之。正式这样一个过程,用户的状态也就得以保持了
比较 GET 与 POST
| GET | POST | |
|---|---|---|
| 后退按钮/刷新 | 无害 | 数据会被重新提交(浏览器应该告知用户数据会被重新提交)。 |
| 书签 | 可收藏为书签 | 不可收藏为书签 |
| 缓存 | 能被缓存 | 不能缓存 |
| 编码类型 | application/x-www-form-urlencoded | application/x-www-form-urlencoded 或 multipart/form-data。为二进制数据使用多重编码。 |
| 历史 | 参数保留在浏览器历史中。 | 参数不会保存在浏览器历史中。 |
| 对数据长度的限制 | 是的。当发送数据时,GET 方法向 URL 添加数据;URL 的长度是受限制的(URL 的最大长度是 2048 个字符)。 | 无限制。 |
| 对数据类型的限制 | 只允许 ASCII 字符。 | 没有限制。也允许二进制数据。 |
| 安全性 | 与 POST 相比,GET 的安全性较差,因为所发送的数据是 URL 的一部分。 在发送密码或其他敏感信息时绝不要使用 GET ! |
POST 比 GET 更安全,因为参数不会被保存在浏览器历史或 web 服务器日志中。 |
| 可见性 | 数据在 URL 中对所有人都是可见的。 | 数据不会显示在 URL 中。 |
数据库优化
1、选取最适用的字段属性
2、使用连接(JOIN)来代替子查询(Sub-Queries)
3、使用联合(UNION)来代替手动创建的临时表
4、事务 事物以BEGIN关键字开始,COMMIT关键字结束。在这之间的一条SQL操作失败,那么,ROLLBACK命令就可以把数据库恢复到BEGIN开始之前的状态。
BEGIN; INSERT INTO salesinfo SET CustomerID=14; UPDATE inventory SET Quantity=11 WHERE item='book'; COMMIT;
6、使用外键
7、使用索引
8、优化的查询语句,尽量不在where语句中使用!=,>,<,null,会导致数据库采用全局搜索,放弃索引
MySQL的多表查询(笛卡尔积原理)
先简单解释一下笛卡尔积。
1,两个集合相乘,不满足交换率,既 A×B ≠ B×A;
2,A集合和B集合相乘,包含了集合A中元素和集合B中元素相结合的所有的可能性。既两个集合相乘得到的新集合的元素个数是 A集合的元素个数 × B集合的元素个数;
- 先确定数据要用到哪些表。
- 将多个表先通过笛卡尔积变成一个表。
- 然后去除不符合逻辑的数据(根据两个表的关系去掉)。
- 最后当做是一个虚拟表一样来加上条件即可。
集合
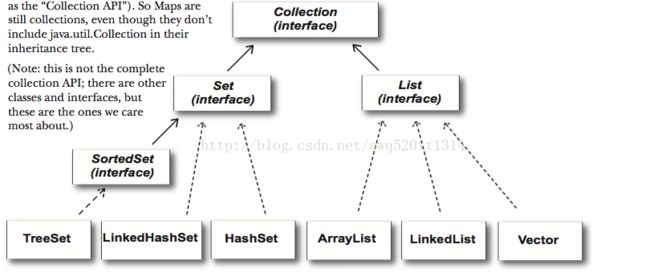
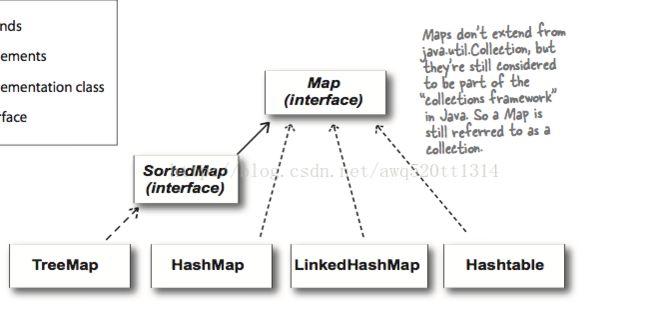
LinkedHashMap继承了HashMap
HashMap put与get方法调用过程
get方法调用
1.当调用get方法时会调用hash函数,这个hash函数会将key的hashCode值返回,返回的hashCode与Entry数组长度-1进行逻辑与运算得到一个index值,用这个index值来确定数据存储在Entry数组当中的位置
2.通过循环来遍历索引位置对应的链表,初始值为数据存储在Entry数组当中的位置,循环条件为Entry对象不为null,改变循环条件为Entry对象的下一个节点
3.如果hash函数得到的hash值与Entry对象当中key的hash值相等,并且Entry对象当中的key值与get方法传进来的key值equals相同则返回该Entry对象的value值,否则返回null
put方法调用
1.调用hash函数得到key的HashCode值
2.通过HashCode值与数组长度-1逻辑与运算得到一个index值
3.遍历索引位置对应的链表,如果Entry对象的hash值与hash函数得到的hash值相等,并且该Entry对象的key值与put方法传过来的key值相等则,将该Entry对象的value值赋给一个变量,将该Entry对象的value值重新设置为put方法传过来的value值。将旧的value返回。
4.添加Entry对象到相应的索引位置
2、什么是”ABA”问题?
比如说一个线程one从内存位置V中取出A,这时候另一个线程two也从内存中取出A,并且two进行了一些操作变成了B,然后two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后one操作成功。
尽管线程one的CAS操作成功,但是不代表这个过程就是没有问题的。
对于ABA问题其解决方案是加上版本号,即在每个变量都加上一个版本号,每次改变时加1,即A —> B —> A,变成1A —> 2B —> 3A。
如何解决呢?
Java提供了AtomicStampedReference这个类来解决。
AtomicStampedReference通过版本号stamp,从而避免ABA问题。
compareAndSet有四个参数,分别表示:预期引用、更新后的引用、预期标志、更新后的标志
git merge 和 git rebase 区别
marge 特点:自动创建一个新的commit
如果合并的时候遇到冲突,仅需要修改后重新commit
优点:记录了真实的commit情况,包括每个分支的详情
缺点:因为每次merge会自动产生一个merge commit,所以在使用一些git 的GUI tools,特别是commit比较频繁时,看到分支很杂乱。
rebase 特点:会合并之前的commit历史
优点:得到更简洁的项目历史,去掉了merge commit
缺点:如果合并出现代码问题不容易定位,因为re-write了history
git面试知识点
- git容易混淆的两个概念
- 一些常用的git命令
- git的两种工作流
git容易混淆的两个概念
- 工作区(project就是一个工作区)
- .gitignore(配置不想上传到版本库的文件)
一些常用git命令
- git init(创建仓库)
- git status(查看仓库的状态)
- git diff 文件名 (这次相较上次修改了哪些内容)
- git add 文件名 (将添加的文件放到暂存区中)
- git commit (将栈存区内容提交到代码区中)
- git clone git地址(将远程仓库的代码克隆到本地)
- git branch 查看当前分支
- git checkout 切换分支
git的两种工作流
- fork/clone
- clone
用户态与内核态的切换与区别
内核态与用户态是操作系统的两种运行级别
,intel cpu提供Ring0-Ring3三种级别
运行模式,Ring0级别最高,Ring3级别最低。
Linux使用了Ring3级别运行用户态。Ring0作为内核态,没有使用 Ring1和Ring2.
Ring3不能访问Ring0的地址空间,包括代码和数量。Linux进程的4GB空间,3G-4G部分大家是共享
的,是内核态的地址空间,这里存放在整个内核代码和所有的内核模块,以及内核所维护的数据。用户运行一程
序,该程序所创建的进程开始是运行在用户态的,如果要执行文件操作,网络数据发送等操作,必须通过write,
send等系统调用,这些系统会调用内核中的代码来完成操作,这时,必须切换到Ring0,然后进入3GB-4GB中的
内核地址空间去执行这些代码完成操作,完成后,切换Ring3,回到用户态。这样,用户态的程序就不能随意操
作1内核地址空间,具有一定的安全保护作用。
用户态和内核态的转换
(1)用户态切换到内核态的3种方式
a.系统调用
这是用户进程主动要求切换到内核态的一种方式,用户进程通过系统调用申请操作系统提供的服务程序完成工作。
而系统调用的机制其核心还是使用了操作系统为用户特别开放的一个中断来实现,例如Linux的ine 80h中断。
b.异常
当CPU在执行运行在用户态的程序时,发现了某些事件不可知的异常,这是会触发由当前运行进程切换到处理此
异常的内核相关程序中,也就到了内核态,比如缺页异常。
c.外围设备的中断
当外围设备完成用户请求的操作之后,会向CPU发出相应的中断信号,这时CPU会暂停执行下一条将要执行的指令
转而去执行中断信号的处理程序,如果先执行的指令是用户态下的程序,那么这个转换的过程自然也就发生了有
用户态到内核态的切换。比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作等。
具体的切换操作
从出发方式看,可以在认为存在前述3种不同的类型,但是从最终实际完成由用户态到内核态的切换操作上来说,
涉及的关键步骤是完全一样的,没有任何区别,都相当于执行了一个中断响应的过程,因为系统调用实际上最
终是中断机制实现的,而异常和中断处理机制基本上是一样的,用户态切换到内核态的步骤主要包括:
(1)从当前进程的描述符中提取其内核栈的ss0及esp0信息。
(2)使用ss0和esp0指向的内核栈将当前进程的cs,eip,eflags,ss,esp信息保存起来,这个过程也完成了由用
户栈找到内核栈的切换过程,同时保存了被暂停执行的程序的下一条指令。
(3)将先前由中断向量检索得到的中断处理程序的cs,eip信息装入相应的寄存器,开始执行中断处理程序,这
时就转到了内核态的程序执行了。
红黑树
(1)每个节点或者是黑色,或者是红色。
(2)根节点是黑色。
(3)每个叶子节点(NIL)是黑色。 [注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点!]
(4)如果一个节点是红色的,则它的子节点必须是黑色的。
(5)从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑节点。
在Java 8 中,如果一个桶中的元素个数超过 TREEIFY_THRESHOLD(默认是 8 ),就使用红黑树来替换链表,从而提高速度。
这个替换的方法叫 treeifyBin() 即树形化
双亲委派模型
双亲委派模型过程
某个特定的类加载器在接到加载类的请求时,首先将加载任务委托给父类加载器,依次递归,如果父类加载器可以完成类加载任务,就成功返回;只有父类加载器无法完成此加载任务时,才自己去加载。
使用双亲委派模型的好处在于Java类随着它的类加载器一起具备了一种带有优先级的层次关系。例如类java.lang.Object,它存在在rt.jar中,无论哪一个类加载器要加载这个类,最终都是委派给处于模型最顶端的Bootstrap ClassLoader进行加载,因此Object类在程序的各种类加载器环境中都是同一个类。相反,如果没有双亲委派模型而是由各个类加载器自行加载的话,如果用户编写了一个java.lang.Object的同名类并放在ClassPath中,那系统中将会出现多个不同的Object类,程序将混乱。因此,如果开发者尝试编写一个与rt.jar类库中重名的Java类,可以正常编译,但是永远无法被加载运行。在JAVA中的同一个类,如果用不同的类加载器加载,则生成的class对象认为是不同的。委派的好处就是避免有些类被重复加载。
什么是CopyOnWrite容器?CopyOnWriteArrayList的实现原理?
CopyOnWrite容器即写时复制的容器。通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
CopyOnWrite并发容器用于读多写少的并发场景
CopyOnWrite的缺点
内存占用问题 因为CopyOnWrite的写时复制机制,所以在进行写操作的时候,内存里会同时驻扎两个对象的内存,旧的对象和新写入的对象(注意:在复制的时候只是复制容器里的引用,只是在写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存)。如果这些对象占用的内存比较大,比如说200M左右,那么再写入100M数据进去,内存就会占用300M,那么这个时候很有可能造成频繁的Yong GC和Full GC。
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
CopyOnWriteArrayList的整个add操作都是在锁的保护下进行的。
这样做是为了避免在多线程并发add的时候,复制出多个副本出来,把数据搞乱了,导致最终的数组数据不是我们期望的。
1、如果写操作未完成,那么直接读取原数组的数据;
2、如果写操作完成,但是引用还未指向新数组,那么也是读取原数组数据;
3、如果写操作完成,并且引用已经指向了新的数组,那么直接从新数组中读取数据。
可见,CopyOnWriteArrayList的读操作是可以不用加锁的。
java之clone方法的使用
通过实现Cloneable接口,特别要注意深度克隆和浅度克隆的区别
synchronized实现原理:
涉及两条指令:
(1)monitorenter
每个对象有一个监视器锁(monitor)。当monitor被占用时就会处于锁定状态,线程执行monitorenter指令时尝试获取monitor的所有权,过程如下:
1、如果monitor的进入数为0,则该线程进入monitor,然后将进入数设置为1,该线程即为monitor的所有者。
2、如果线程已经占有该monitor,只是重新进入,则进入monitor的进入数加1。
3、如果其他线程已经占用了monitor,则该线程进入阻塞状态,直到monitor的进入数为0,再重新尝试获取monitor的所有权。
(2)monitorexit
执行monitorexit的线程必须是objectref所对应的monitor的所有者。
指令执行时,monitor的进入数减1,如果减1后进入数为0,那线程退出monitor,不再是这个monitor的所有者。其他被这个monitor阻塞的线程可以尝试去获取这个 monitor 的所有权。
自旋锁和互斥锁区别
两种锁的加锁原理
互斥锁:线程会从sleep(加锁)——>running(解锁),过程中有上下文的切换,cpu的抢占,信号的发送等开销。
自旋锁:线程一直是running(加锁——>解锁),死循环检测锁的标志位,机制不复杂。
互斥锁属于sleep-waiting类型的锁。例如在一个双核的机器上有两个线程(线程A和线程B),它们分别运行在Core0和 Core1上。假设线程A想要通过pthread_mutex_lock操作去得到一个临界区的锁,而此时这个锁正被线程B所持有,那么线程A就会被阻塞 (blocking),Core0 会在此时进行上下文切换(Context Switch)将线程A置于等待队列中,此时Core0就可以运行其他的任务(例如另一个线程C)而不必进行忙等待。而自旋锁则不然,它属于busy-waiting类型的锁,如果线程A是使用pthread_spin_lock操作去请求锁,那么线程A就会一直在 Core0上进行忙等待并不停的进行锁请求,直到得到这个锁为止。
两种锁的区别
互斥锁的起始原始开销要高于自旋锁,但是基本是一劳永逸,临界区持锁时间的大小并不会对互斥锁的开销造成影响,而自旋锁是死循环检测,加锁全程消耗cpu,起始开销虽然低于互斥锁,但是随着持锁时间,加锁的开销是线性增长。
两种锁的应用
互斥锁用于临界区持锁时间比较长的操作,比如下面这些情况都可以考虑
1 临界区有IO操作
2 临界区代码复杂或者循环量大
3 临界区竞争非常激烈
4 单核处理器
至于自旋锁就主要用在临界区持锁时间非常短且CPU资源不紧张的情况下,自旋锁一般用于多核的服务器。
lock free的理解
物理内存与虚拟内存区别与联系
首先我从最基本的概念说起,什么是物理内存的概念,虚拟内存的概念?
物理内存,在应用中,自然是顾名思义,物理上,真实的插在板子上的内存是多大就是多大了。而在CPU中的概念,物理内存就是CPU的地址线可以直接进行寻址的内存空间大小。比如8086只有20根地址线,那么它的寻址空间就是1MB,我们就说8086能支持1MB的物理内存,及时我们安装了128M的内存条在板子上,我们也只能说8086拥有1MB的物理内存空间。同理我们现在大部分使用的是32位的机子,32位的386以上CPU就可以支持最大4GB的物理内存空间了。
先说说为什么会有虚拟内存和物理内存的区别。正在运行的一个进程,他所需的内存是有可能大于内存条容量之和的,比如你的内存条是256M,你的程序却要创建一个2G的数据区,那么不是所有数据都能一起加载到内存(物理内存)中,势必有一部分数据要放到其他介质中(比如硬盘),待进程需要访问那部分数据时,在通过调度进入物理内存。所以,虚拟内存是进程运行时所有内存空间的总和,并且可能有一部分不在物理内存中,而物理内存就是我们平时所了解的内存条。有的地方呢,也叫这个虚拟内存为内存交换区。关键的是不要把虚拟内存跟真实的插在主板上的内存条相挂钩,虚拟内存它是“虚拟的”不存在,假的啦,它只是内存管理的一种抽象!
那么,什么是虚拟内存地址和物理内存地址呢。假设你的计算机是32位,那么它的地址总线是32位的,也就是它可以寻址0~0xFFFFFFFF(4G)的地址空间,但如果你的计算机只有256M的物理内存0x~0x0FFFFFFF(256M),同时你的进程产生了一个不在这256M地址空间中的地址,那么计算机该如何处理呢?回答这个问题前,先说明计算机的内存分页机制。
计算机会对虚拟内存地址空间(32位为4G)分页产生页(page),对物理内存地址空间(假设256M)分页产生页帧(page frame),这个页和页帧的大小是一样大的,所以呢,在这里,虚拟内存页的个数势必要大于物理内存页帧的个数。在计算机上有一个页表(page table),就是映射虚拟内存页到物理内存页的,更确切的说是页号到页帧号的映射,而且是一对一的映射。但是问题来了,虚拟内存页的个数 > 物理内存页帧的个数,岂不是有些虚拟内存页的地址永远没有对应的物理内存地址空间?不是的,操作系统是这样处理的。操作系统有个页面失效(page fault)功能。操作系统找到一个最少使用的页帧,让他失效,并把它写入磁盘,随后把需要访问的页放到页帧中,并修改页表中的映射,这样就保证所有的页都有被调度的可能了。这就是处理虚拟内存地址到物理内存的步骤。
虚拟内存地址由页号(与页表中的页号关联)和偏移量组成。页号就不必解释了,上面已经说了,页号对应的映射到一个页帧。那么,说说偏移量。偏移量就是我上面说的页(或者页帧)的大小,即这个页(或者页帧)到底能存多少数据。举个例子,有一个虚拟地址它的页号是4,偏移量是20,那么他的寻址过程是这样的:首先到页表中找到页号4对应的页帧号(比如为8),如果页不在内存中,则用失效机制调入页,否则把页帧号和偏移量传给MMU(CPU的内存管理单元)组成一个物理上真正存在的地址,接着就是访问物理内存中的数据了。总结起来说,虚拟内存地址的大小是与地址总线位数相关,物理内存地址的大小跟物理内存条的容量相关。
CountDownLatch实现原理
实现原理:让需要的暂时阻塞的线程,进入一个死循环里面,得到某个条件后再退出循环,以此实现阻塞当前线程的效果。
是当你调用了countDownLatch.await()方法后,你当前线程就会进入了一个死循环当中,在这个死循环里面,会不断的进行判断,通过调用tryAcquireShared方法,不断判断我们上面说的那个计数器,看看它的值是否为0了(为0的时候,其实就是我们调用了足够多次数的countDownLatch.countDown()方法的时候),如果是为0的话,tryAcquireShared就会返回1,代码也会进入到图中的红框部分,然后跳出了循环,也就不再“阻塞”当前线程了。需要注意的是,说是在不停的循环,其实也并非在不停的执行for循环里面的内容,因为在后面调用parkAndCheckInterrupt()方法时,在这个方法里面是会调用 LockSupport.park(this);,来禁用当前线程的。
Java实现缓存(LRU,FIFO)
LRU缓存的思想
- 固定缓存大小,需要给缓存分配一个固定的大小。
- 每次读取缓存都会改变缓存的使用时间,将缓存的存在时间重新刷新。
- 需要在缓存满了后,将最近最久未使用的缓存删除,再添加最新的缓存。
按照如上思想,可以使用LinkedHashMap来实现LRU缓存。
FIFO (First Input First Output) 一种先进先出的数据缓存器,先进入的数据先从FIFO缓存器中读出,与RAM相比没有外部读写地址线,使用比较简单,但只能顺序写入数据,顺序的读出数据,不能像普通存储器那样可以由地址线决定读取或写入某个指定的地址。
Java原子变量类
原子变量类相当于一种泛化得volatile变量,能够支持原子的和有条件的读-改-写操作。AtomicInteger表示一个int类型的值,并提供了get和set方法,这些Volatile类型的int变量在读取和写入上有着相同的内存语义。它还提供了一个原子的compareAndSet方法
AtomicInteger 通过CAS实现
2 SpringMVC五大组件
DispatcherServlet (前端控制器)
HanlderMapping
Controller (处理器)
ModelAndView
ViewResolver (视图解析器)
动态注入Bean到Spring容器
1 .常规方法:
一、基于标注的方式注入实例
1.1 @Autowired 应用范围: 变量, setter方法和构造函数之上。
1.2 @Inject 应用范围: 变量、setter方法,构造函数
@Resource 应用范围:可以应用到变量和setter方法之上
二、动态注入的方式
基于ApplicationContextAware来获取ApplicationContext的引用,然后基于ApplicationContext进行对象的动态获取。
Spring自动切换环境参数的两种实现方式
Spring Boot使用了一个全局的配置文件application.xml
通过启动时指定spring.profiles.active参数即可轻松切换配置文件
分布式和集群的区别
分布式:一个任务分给多台机器去做,减少单个任务的执行时间。
集群:提高单位时间内执行任务数。
例如:一个任务由10个子任务组成,每个子任务单独执行需要1个小时,则在一台服务器上执行该任务需要10个小时。
分布式方案:提供10台服务器,每台服务器只处理一个子任务,不考虑任务间的依赖关系,执行完这个任务只需要一个小时。
集群方案:同样提供10台服务器,每台服务器都能独立处理这个任务。假设有10个任务同时到达,10个服务器将同时工作,10小时后,10个任务同时完成,同样是一个小时完成一个任务。
TCP/IP分为几层?各层的作用是什么?
答:1. 应用层 2.传输层 3.网络层 4.网络接口层
自旋锁,偏向锁,轻量级锁,重量级锁的区别
偏向锁、轻量级锁、重量级锁适用于不同的并发场景:
- 偏向锁:无实际竞争,且将来只有第一个申请锁的线程会使用锁。
- 轻量级锁:无实际竞争,多个线程交替使用锁;允许短时间的锁竞争。
- 重量级锁:有实际竞争,且锁竞争时间长。
重量级锁
内置锁在Java中被抽象为监视器锁(monitor)。在JDK 1.6之前,监视器锁可以认为直接对应底层操作系统中的互斥量(mutex)。这种同步方式的成本非常高,包括系统调用引起的内核态与用户态切换、线程阻塞造成的线程切换等。因此,后来称这种锁为“重量级锁”。
自旋锁
首先,内核态与用户态的切换上不容易优化。但通过自旋锁,可以减少线程阻塞造成的线程切换(包括挂起线程和恢复线程)。
如果锁的粒度小,那么锁的持有时间比较短(尽管具体的持有时间无法得知,但可以认为,通常有一部分锁能满足上述性质)。那么,对于竞争这些锁的而言,因为锁阻塞造成线程切换的时间与锁持有的时间相当,减少线程阻塞造成的线程切换,能得到较大的性能提升。具体如下:
- 当前线程竞争锁失败时,打算阻塞自己
- 不直接阻塞自己,而是自旋(空等待,比如一个空的有限for循环)一会
- 在自旋的同时重新竞争锁
- 如果自旋结束前获得了锁,那么锁获取成功;否则,自旋结束后阻塞自己
如果在自旋的时间内,锁就被旧owner释放了,那么当前线程就不需要阻塞自己(也不需要在未来锁释放时恢复),减少了一次线程切换
缺点
- 单核处理器上,不存在实际的并行,当前线程不阻塞自己的话,旧owner就不能执行,锁永远不会释放,此时不管自旋多久都是浪费;进而,如果线程多而处理器少,自旋也会造成不少无谓的浪费。
- 自旋锁要占用CPU,如果是计算密集型任务,这一优化通常得不偿失,减少锁的使用是更好的选择。
- 如果锁竞争的时间比较长,那么自旋通常不能获得锁,白白浪费了自旋占用的CPU时间。这通常发生在锁持有时间长,且竞争激烈的场景中,此时应主动禁用自旋锁。
自适应自旋锁
自适应意味着自旋的时间不再固定了,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定:
- 如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也很有可能再次成功,进而它将允许自旋等待持续相对更长的时间,比如100个循环。
- 相反的,如果对于某个锁,自旋很少成功获得过,那在以后要获取这个锁时将可能减少自旋时间甚至省略自旋过程,以避免浪费处理器资源。
自适应自旋解决的是“锁竞争时间不确定”的问题。JVM很难感知到确切的锁竞争时间,而交给用户分析就违反了JVM的设计初衷。自适应自旋假定不同线程持有同一个锁对象的时间基本相当,竞争程度趋于稳定,因此,可以根据上一次自旋的时间与结果调整下一次自旋的时间。
缺点
然而,自适应自旋也没能彻底解决该问题,如果默认的自旋次数设置不合理(过高或过低),那么自适应的过程将很难收敛到合适的值。
轻量级锁
自旋锁的目标是降低线程切换的成本。如果锁竞争激烈,我们不得不依赖于重量级锁,让竞争失败的线程阻塞;如果完全没有实际的锁竞争,那么申请重量级锁都是浪费的。轻量级锁的目标是,减少无实际竞争情况下,使用重量级锁产生的性能消耗,包括系统调用引起的内核态与用户态切换、线程阻塞造成的线程切换等。
顾名思义,轻量级锁是相对于重量级锁而言的。使用轻量级锁时,不需要申请互斥量,仅仅将Mark Word中的部分字节CAS更新指向线程栈中的Lock Record,如果更新成功,则轻量级锁获取成功,记录锁状态为轻量级锁;否则,说明已经有线程获得了轻量级锁,目前发生了锁竞争(不适合继续使用轻量级锁),接下来膨胀为重量级锁。
Mark Word是对象头的一部分;每个线程都拥有自己的线程栈(虚拟机栈),记录线程和函数调用的基本信息。二者属于JVM的基础内容,此处不做介绍。
当然,由于轻量级锁天然瞄准不存在锁竞争的场景,如果存在锁竞争但不激烈,仍然可以用自旋锁优化,自旋失败后再膨胀为重量级锁。
缺点
同自旋锁相似:
- 如果锁竞争激烈,那么轻量级将很快膨胀为重量级锁,那么维持轻量级锁的过程就成了浪费。
不会使用互斥量,而是使用CAS
偏向锁
在没有实际竞争的情况下,还能够针对部分场景继续优化。如果不仅仅没有实际竞争,自始至终,使用锁的线程都只有一个,那么,维护轻量级锁都是浪费的。偏向锁的目标是,减少无竞争且只有一个线程使用锁的情况下,使用轻量级锁产生的性能消耗。轻量级锁每次申请、释放锁都至少需要一次CAS,但偏向锁只有初始化时需要一次CAS。
“偏向”的意思是,偏向锁假定将来只有第一个申请锁的线程会使用锁(不会有任何线程再来申请锁),因此,只需要在Mark Word中CAS记录owner(本质上也是更新,但初始值为空),如果记录成功,则偏向锁获取成功,记录锁状态为偏向锁,以后当前线程等于owner就可以零成本的直接获得锁;否则,说明有其他线程竞争,膨胀为轻量级锁。
偏向锁无法使用自旋锁优化,因为一旦有其他线程申请锁,就破坏了偏向锁的假定。
缺点
同样的,如果明显存在其他线程申请锁,那么偏向锁将很快膨胀为轻量级锁。
不过这个副作用已经小的多。
如果需要,使用参数-XX:-UseBiasedLocking禁止偏向锁优化(默认打开)。
简述具有五层协议的网络体系结构各层的主要功能,每一层所用到的协议
⑴物理层: 物理层的任务就是透明地传送比特流,确定连接电缆插头的定义及连接法。
⑵数据链路层: 数据链路层的任务是在两个相邻结点间的线路上无差错地传送以帧(frame)为单位的数据。每一帧包括数据和必要的控制信息。
⑶网络层:网络层的任务就是要选择合适的路由,使发送站的运输层所传下来的分组能够正确无误地按照地址找到目的站,并交付给目的站的运输层。
⑷运输层:运输层的任务是向上一层的进行通信的两个进程之间提供一个可靠的端到端服务,使它们看不见运输层以下的数据通信的细节。
⑸应用层:应用层直接为用户的应用进程提供服务。
- TCP/IP:
数据链路层:ARP,RARP
网络层: IP,ICMP,IGMP
传输层:TCP ,UDP,UGP
应用层:Telnet,FTP,SMTP,SNMP.
OSI:
物理层:EIA/TIA-232, EIA/TIA-499, V.35, V.24, RJ45, Ethernet, 802.3, 802.5, FDDI, NRZI, NRZ, B8ZS
数据链路层:Frame Relay, HDLC, PPP, IEEE 802.3/802.2, FDDI, ATM, IEEE 802.5/802.2
网络层:IP,IPX,AppleTalk DDP
传输层:TCP,UDP,SPX
会话层:RPC,SQL,NFS,NetBIOS,names,AppleTalk,ASP,DECnet,SCP
表示层:TIFF,GIF,JPEG,PICT,ASCII,EBCDIC,encryption,MPEG,MIDI,HTML
应用层:FTP,WWW,Telnet,NFS,SMTP,Gateway,SNMP
检测mysql中sql语句的效率的方法
1、通过查询日志
Windows下开启MySQL慢查询
Linux下启用MySQL慢查询
2.show processlist 命令
3、explain来了解SQL执行的状态
java间接实现多继承的方法
一、 接口
二、内部类
常见的几种负载均衡算法
1、轮询法
将请求按顺序轮流地分配到后端服务器上,它均衡地对待后端的每一台服务器,而不关心服务器实际的连接数和当前的系统负载。
2、随机法
通过系统的随机算法,根据后端服务器的列表大小值来随机选取其中的一台服务器进行访问。由概率统计理论可以得知,随着客户端调用服务端的次数增多,
其实际效果越来越接近于平均分配调用量到后端的每一台服务器,也就是轮询的结果。
3、源地址哈希法
源地址哈希的思想是根据获取客户端的IP地址,通过哈希函数计算得到的一个数值,用该数值对服务器列表的大小进行取模运算,得到的结果便是客服端要访问服务器的序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会映射到同一台后端服务器进行访问。
4、加权轮询法
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。
5、加权随机法
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
6、最小连接数法
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前
积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
反射可以获得参数名么
一般来说,通过反射是很难获得参数名的,只能取到参数类型,因为在编译时,参数名有可能是会改变的,需要在编译时加入参数才不会改变。
hashmap扩容是怎么扩容的,为什么是2的幂,
为什么说扩容机制很好玩呢,因为它会将原来的链表同过计算e.hash&oldCap==0分成两条链表,再将两条链表散列到新数组的不同位置上
1. 这个算法实际就是取模,hash%length,计算机中直接求余效率不如位移运算,源码中做了优化hash&(length-1),
hash%length==hash&(length-1)的前提是length是2的n次方;
2. 方便分成两个链表
怎样重写equals()方法?
重写equals方法的要求:
1、自反性:对于任何非空引用x,x.equals(x)应该返回true。
2、对称性:对于任何引用x和y,如果x.equals(y)返回true,那么y.equals(x)也应该返回true。
3、传递性:对于任何引用x、y和z,如果x.equals(y)返回true,y.equals(z)返回true,那么x.equals(z)也应该返回true。
4、一致性:如果x和y引用的对象没有发生变化,那么反复调用x.equals(y)应该返回同样的结果。
5、非空性:对于任意非空引用x,x.equals(null)应该返回false。
HTTP常用状态码
2开头 (请求成功)表示成功处理了请求的状态代码。
200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
201 (已创建) 请求成功并且服务器创建了新的资源。
202 (已接受) 服务器已接受请求,但尚未处理。
203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。
206 (部分内容) 服务器成功处理了部分 GET 请求。
3开头 (请求被重定向)表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
4开头 (请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。
400 (错误请求) 服务器不理解请求的语法。
401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403 (禁止) 服务器拒绝请求。
404 (未找到) 服务器找不到请求的网页。
405 (方法禁用) 禁用请求中指定的方法。
406 (不接受) 无法使用请求的内容特性响应请求的网页。
407 (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。
408 (请求超时) 服务器等候请求时发生超时。
409 (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。
410 (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。
411 (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
412 (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
413 (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414 (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
415 (不支持的媒体类型) 请求的格式不受请求页面的支持。
416 (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。
417 (未满足期望值) 服务器未满足"期望"请求标头字段的要求。
5开头(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
java 内存溢出 栈溢出的原因与排查方法
1、 内存溢出的原因是什么?
内存溢出是由于没被引用的对象(垃圾)过多造成JVM没有及时回收,造成的内存溢出。如果出现这种现象可行代码排查:
一)是否App中的类中和引用变量过多使用了Static修饰 如public staitc Student s;在类中的属性中使用 static修饰的最好只用基本类型或字符串。如public static int i = 0; //public static String str;
二)是否App中使用了大量的递归或无限递归(递归中用到了大量的建新的对象)
三)是否App中使用了大量循环或死循环(循环中用到了大量的新建的对象)
四)检查App中是否使用了向数据库查询所有记录的方法。即一次性全部查询的方法,如果数据量超过10万多条了,就可能会造成内存溢出。所以在查询时应采用“分页查询”。
五)检查是否有数组,List,Map中存放的是对象的引用而不是对象,因为这些引用会让对应的对象不能被释放。会大量存储在内存中。
六)检查是否使用了“非字面量字符串进行+”的操作。因为String类的内容是不可变的,每次运行"+"就会产生新的对象,如果过多会造成新String对象过多,从而导致JVM没有及时回收而出现内存溢出。
如String s1 = "My name";
String s2 = "is";
String s3 = "xuwei";
String str = s1 + s2 + s3 +.........;这是会容易造成内存溢出的
但是String str = "My name" + " is " + " xuwei" + " nice " + " to " + " meet you"; //但是这种就不会造成内存溢出。因为这是”字面量字符串“,在运行"+"时就会在编译期间运行好。不会按照JVM来执行的。
在使用String,StringBuffer,StringBuilder时,如果是字面量字符串进行"+"时,应选用String性能更好;如果是String类进行"+"时,在不考虑线程安全时,应选用StringBuilder性能更好。
- public class Test {
- public void testHeap(){
- for(;;){ //死循环一直创建对象,堆溢出
- ArrayList list = new ArrayList (2000);
- }
- }
- int num=1;
- public void testStack(){ //无出口的递归调用,栈溢出
- num++;
- this.testStack();
- }
- public static void main(String[] args){
- Test t = new Test ();
- t.testHeap();
- t.testStack();
- }
- }
七)使用 DDMS工具进行查找内存溢出的大概位置
2、栈溢出的原因
一)、是否有递归调用
二)、是否有大量循环或死循环
三)、全局变量是否过多
四)、 数组、List、map数据是否过大
五)使用DDMS工具进行查找大概出现栈溢出的位置
方法区和运行时常量池溢出
如果要向运行时常量池中添加内容,最简单的做法就是使用String.intern()这个Native方法。该方法的作用是:如果字
符串常量池中已经包含一个等于此String对象的字符串,则返回代表池中这个字符串的String对象;否则,将此String对象包含的字符串添加到常量池中,并且返回此String对象的引用。
String为什么是final
1、从设计安全上讲,
1)、确保它们不会在子类中改变语义。String类是final类,这意味着不允许任何人定义String的子类。
换言之,
如果有一个String的引用,它引用的一定是一个String对象,而不可能是其他类的对象。
2)、String 一旦被创建是不能被修改的,
2、从效率上讲:
1)、设计成final,JVM才不用对相关方法在虚函数表中查询,而直接定位到String类的相关方法上,提高了执行效率。
2)、Java设计者认为共享带来的效率更高。
静态绑定
(final、static、private)在程序执行前已经被绑定,也就是说在编译过程中就已经知道这个方法是哪个类的方法,此时由编译器获取其他连接程序实现。针对java简单的可以理解为程序编译期的绑定
private:不能被继承,则不能通过子类对象调用,而只能通过类本身的对象进行调用,所以可以说private方法和方法所属的类绑定;
final:final方法虽然可以被继承,但是不能被重写(覆盖),虽然子类对象可以调用,但是调用的都是父类中的final方法(因此可以看出当类中的方法声明为final的时候,一是为了防止方法被覆盖,而是为了有效关闭java的动态绑定);
static:static方法可以被子类继承,但是不能被子类重写(覆盖),但是可以被子类隐藏。(这里意思是说如果父类里有一个static方法,它的子类里如果没有对应的方法,那么当子类对象调用这个方法时就会使用父类中的方法。而如果子类中定义了相同的方法,则会调用子类的中定义的方法。唯一的不同就是,当子类对象上转型为父类对象时,不论子类中有没有定义这个静态方法,该对象都会使用父类中的静态方法。因此这里说静态方法可以被隐藏而不能被覆盖。这与子类隐藏父类中的成员变量是一样的。隐藏和覆盖的区别在于,子类对象转换成父类对象后,能够访问父类被隐藏的变量和方法,而不能访问父类被覆盖的方法)。
volatile底层实现原理
Java语言提供了Violatile来确保多处理开发中,共享变量的“可见性”,即当另外一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。它是轻量级的synchronized,不会引起线程上下文的切换和调度,执行开销更小。
使用Violatile修饰的变量在汇编阶段,会多出一条lock前缀指令,它在多核处理器下回引发两件事情:
- 将当前处理器缓存行的数据写回到系统内存
- 这个写回内存的操作会使在其他CPU里缓存了该内存地址的数据无效。
通常处理器和内存之间都有几级缓存来提高处理速度,处理器先将内存中的数据读取到内部缓存后再进行操作,但是对于缓存写会内存的时机则无法得知,因此在一个处理器里修改的变量值,不一定能及时写会缓存,这种变量修改对其他处理器变得“不可见”了。但是,使用Volatile修饰的变量,在写操作的时候,会强制将这个变量所在缓存行的数据写回到内存中,但即使写回到内存,其他处理器也有可能使用内部的缓存数据,从而导致变量不一致,所以,在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期,如果过期,就会将该缓存行设置成无效状态,下次要使用就会重新从内存中读取。
分布式环境下,怎么保证线程安全
避免并发
在分布式环境中,如果存在并发问题,那么很难通过技术去解决,或者解决的代价很大,所以我们首先要想想是不是可以通过某些策略和业务设计来避免并发。比如通过合理的时间调度,避开共享资源的存取冲突。另外,在并行任务设计上可以通过适当的策略,保证任务与任务之间不存在共享资源,比如在以前博文中提到的例子,我们需要用多线程或分布式集群来计算一堆客户的相关统计值,由于客户的统计值是共享数据,因此会有并发潜在可能。但从业务上我们可以分析出客户与客户之间 数据是不共享的,因此可以设计一个规则来保证一个客户的计算工作和数据访问只会被一个线程或一台工作机完成,而不是把一个客户的计算工作分配给多个线程去 完成。这种规则很容易设计,例如可以采用hash算法。
时间戳
分布式环境中并发是没法保证时序的,无论是通过远程接口的同步调用或异步消息,因此很容易造成某些对时序性有要求的业务在高并发时产生错误。比如系统A需要把某个值的变更同步到系统B,由于通知的时序问题会导致一个过期的值覆盖了有效值。对于这个问题,常用的办法就是采用时间戳的方式,每次系统A发送变更给系统B的时候需要带上一个能标示时序的时间戳,系统B接到通知后会拿时间戳与存在的时间戳比较,只有当通知的时间戳大于存在的时间戳,才做更新。这种方式比较简单,但关键在于调用方一般要保证时间戳的时序有效性。
串行化
有的时候可以通过串行化可能产生并发问题操作,牺牲性能和扩展性,来满足对数据一致性的要求。比如分布式消息系统就没法保证消息的有序性,但可以通过变分布式消息系统为单一系统就可以保证消息的有序性了。另外,当接收方没法处理调用有序性,可以通过一个队列先把调用信息缓存起来,然后再串行地处理这些调用。
数据库
分布式环境中的共享资源不能通过Java里同步方法或加锁来保证线程安全,但数据库是分布式各服务器的共享点,可以通过数据库的高可靠一致性机制来满足需求。比如,可以通过唯一性索引来解决并发过程中重复数据的生产或重复任务的执行;另外有些更新计算操作也尽量通过sql来完成,因为在程序段计算好后再去更新就有可能发生脏复写问题,但通过一条sql来完成计算和更新就可以通过数据库的锁机制来保证update操作的一致性。
行锁
有的事务比较复杂,无法通过一条sql解决问题,并且有存在并发问题,这时就需要通过行锁来解决,一般行锁可以通过以下方式来实现:
对于Oracle数据库,可以采用select ... for update方式。这种方式会有潜在的危险,就是如果没有commit就会造成这行数据被锁住,其他有涉及到这行数据的任务都会被挂起,应该谨慎使用
在表里添加一个标示锁的字段,每次操作前,先通过update这个锁字段来完成类似竞争锁的操作,操作完成后在update锁字段复位,标示已归还锁。这种方式比较安全,不好的地方在于这些update锁字段的操作就是额外的性能消耗
统一触发途径
当一个数据可能会被多个触发点或多个业务涉及到,就有并发问题产生的隐患,因此可以通过前期架构和业务设计,尽量统一触发途径,触发途径少了一是减少并发的可能,也有利于对于并发问题的分析和判断。
静态代码块什么时候会被执行?
结论:加载一个类时,同时执行静态代码块,作初始化用,其内部类不会同时被加载。一个类被加载,当且仅当其某个静态成员(静态域、构造器、静态方法等)被调用时发生。
在多线程中使用静态方法时候会有线程安全问题
静态方法如果没有使用静态变量,则没有线程安全问题。
为什么呢?因为静态方法内声明的变量,每个线程调用时,都会新创建一份,而不会共用一个存储单元。比如这里的tmp,每个线程都会创建自己的一份,因此不会有线程安全问题。
注意:静态变量,由于是在类加载时占用一个存储区,每个线程都是共用这个存储区的,所以如果在静态方法里使用了静态变量,这就会有线程安全问题!
IoC的实现原理
根据给出的类名(字符串方式)来动态地生成对象,这种编程方式可以让对象在生成时才被决定到底是哪一种对象
我们可以把IOC容器的工作模式看做是工厂模式的升华,可以把IOC容器看作是一个工厂,这个工厂里要生产的对象都在配置文件中给出定义,然后利用编程语言提供的反射机制,根据配置文件中给出的类名生成相应的对象。从实现来看,IOC是把以前在工厂方法里写死的对象生成代码,改变为由配置文件来定义,也就是把工厂和对象生成这两者独立分隔开来,目的就是提高灵活性和可维护性。
网络端口的作用及分类
一、什么是端口?
我们这里所说的端口,不是计算机硬件的I/O端口,而是软件形式上的概念.工具提供服务类型的不同,端口分为两种,一种是TCP端口,一种是UDP端口。计算机之间相互通信的时候,分为两种方式:一种是发送信息以后,可以确认信息是否到达,也就是有应答的方式,这种方式大多采用TCP协议;一种是发送以后就不管了,不去确认信息是否到达,这种方式大多采用UDP协议。对应这两种协议的服务提供的端口,也就分为TCP端口和UDP端口。
二、端口号范围:1~65535
四、网络端口的分类:
按端口号可分为3大类:
(1)公认端口(Well-KnownPorts):范围从0到1023
它们紧密绑定(binding)于一些服务。通常这些端口的通讯明确表明了某种服务的协议。例如:21端口分配给FTP服务,25端口分配给SMTP(简单邮件传输协议)服务,80端口分配给HTTP服务,135端口分配给RPC(远程过程调用)服务等等。
我们在IE的地址栏里输入一个网址的时候( 比如www.cce.com.cn)是不必指定端口号的,因为在默认情况下WWW服务的端口 号是“80”。
网络服务是可以使用其他端口号的,如果不是默认的端口号则应该在 地址栏上指定端口号,方法是在地址后面加上冒号“:”(半角),再加上端口 号。比如使用“8080”作为WWW服务的端口,则需要在地址栏里输入“www.cce.com.cn:8080”。
但是有些系统协议使用固定的端口号,它是不能被改变的,比如139 端口专门用于NetBIOS与TCP/IP之间的通信,不能手动改变。
(2)动态端口(Dynamic Ports):范围从1024到65535
之所以称为动态端口,是因为它 一般不固定分配某种服务,而是动态分配。动态分配是指当一个系统进程或应用 程序进程需要网络通信时,它向主机申请一个端口,主机从可用的端口号中分配 一个供它使用。当这个进程关闭时,同时也就释放了所占用的端口号。
(2.1)注册端口(RegisteredPorts):从1024到49151。它们松散地绑定于一些服务。也就是说有许多服务绑定于这些端口,这些端口同样用 于许多其它目的。例如:许多系统处理动态端口从1024左右开始。
(2.2)动态和/或私有端口(Dynamicand/orPrivatePorts):从49152到65535。理论上,不应为服务分配这些端口。实际上,机器通常从1024 起分配动态端口。但也有例外:SUN的RPC端口从32768开始。
前后端数据交互的几个方法
1. 利用cookie
2. 利用Ajax
3. jsonp
4. 服务端渲染
5. webSocket 和 Socket.io
Apach ab压测工具
ab -n 100 -c 10 http://www.baidu.com/s
-n 表示请求数,-c 表示并发数.
s为path,表示指定测试地址,不指定可能会报”ab: invalid url” 错误.
另外还有-t 表示多少s内并发和请求
自定义java.lang.Object类会怎样
所以当我们加载自己写的java.lang.Object时,会默认调用Appliation ClassLoader,这是系统提供的类加载器,肯定支持”双亲委派模型”,所以我们的请求会一步步提交到Bootstrap ClassLoader那里,这个类默认加载的类位于$JAVA_HOME/jre/lib下面的rt.jar包,可以找到我们需要的java.lang.Object类,所以加载的自然就不是我们自己写的Object类了.
Innodb间隙锁
什么是间隙锁
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(NEXT-KEY)锁。
危害
因为Query执行过程中通过范围查找的话,他会锁定整个范围内所有的索引键值,即使这个键值并不存在。
间隙锁有一个比较致命的弱点,就是当锁定一个范围键值之后,即使某些不存在的键值也会被无辜的锁定,而造成在锁定的时候无法插入锁定值范围内的任何数据,在某些场景下这可能会针对性造成很大的危害。
理解HashSet及其使用
HashSet实现Set接口,由哈希表(实际上是一个HashMap实例)支持。它不保证set 的迭代顺序;特别是它不保证该顺序恒久不变,此类允许使用null元素。
在HashSet中,元素都存到HashMap键值对的Key上面,而Value时有一个统一的值private static final Object PRESENT = new Object();,
- 说白了,HashSet就是限制了功能的HashMap,所以了解HashMap的实现原理,这个HashSet自然就通
- 对于HashSet中保存的对象,主要要正确重写equals方法和hashCode方法,以保证放入Set对象的唯一性
- 虽说时Set是对于重复的元素不放入,倒不如直接说是底层的Map直接把原值替代了(这个Set的put方法的返回值真有意思)
- HashSet没有提供get()方法,愿意是同HashMap一样,Set内部是无序的,只能通过迭代的方式获得
Mybatis实现分页 转:https://blog.csdn.net/chenbaige/article/details/70846902
一.借助数组进行分页
原理:进行数据库查询操作时,获取到数据库中所有满足条件的记录,保存在应用的临时数组中,再通过List的subList方法,获取到满足条件的所有记录。
二.借助Sql语句进行分页
在了解到通过数组分页的缺陷后,我们发现不能每次都对数据库中的所有数据都检索。然后在程序中对获取到的大量数据进行二次操作,这样对空间和性能都是极大的损耗。所以我们希望能直接在数据库语言中只检索符合条件的记录,不需要在通过程序对其作处理。这时,Sql语句分页技术横空出世。
实现:通过sql语句实现分页也是非常简单的,只是需要改变我们查询的语句就能实现了,即在sql语句后面添加limit分页语句。
三.拦截器分页
上面提到的数组分页和sql语句分页都不是我们今天讲解的重点,今天需要实现的是利用拦截器达到分页的效果。自定义拦截器实现了拦截所有以ByPage结尾的查询语句,并且利用获取到的分页相关参数统一在sql语句后面加上limit分页的相关语句,一劳永逸。不再需要在每个语句中单独去配置分页相关的参数了。。
四.RowBounds实现分页
原理:通过RowBounds实现分页和通过数组方式分页原理差不多,都是一次获取所有符合条件的数据,然后在内存中对大数据进行操作,实现分页效果。只是数组分页需要我们自己去实现分页逻辑,这里更加简化而已。