Python自然语言处理—文本分类基础介绍
本篇文章将简单介绍分类的流程,并详细解读书上的程序,尤其是6.1节最后一个程序。
一 分类的定义
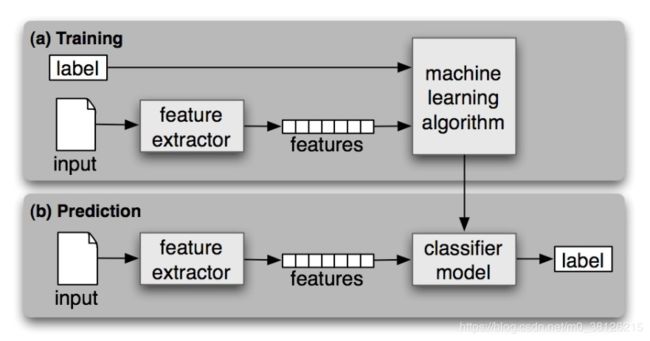
首先要说明自动分类任务是通过有监督的机器学习解决的,盗用原文的图。分类任务首先要通过有标签的数据进行学习,学习出一套打标签的逻辑,再把这套逻辑用在无标签的数据上!
文本分类的应用很多,例如新闻的主题判定,情感分析和垃圾邮件的判定等等
二 文本分类的实现
1特征选择
模型会学习你输入的数据,在创建分类器时第一步是要思考你想输入的特征是什么,直接将原始数据集放入训练可能导致训练的效果不好。特征的选择是需要相关的背景知识的,例如书中给的例子根据姓名判定男女,抽取的特征就是名字最后一个字母。
def gender_features(word):
return {'last_letter': word[-1]}
2将数据分为训练集和测试集
标准的切分应该是训练集,开发集合测试集。在训练集上训练模型,利用开发集进行错误分析,重新训练模型,最终用训练集评价这个模型。
原因很简单,如果只有训练集和测试集,你在训练集上训练用测试集进行错误分析,那么你最终测试集的结果肯定很好!!因为你训练的模型其实是根据测试集进行的调整,你光用测试集对模型测试并不能展现这个模型的泛化能力,你需要一个新的数据集来测试模型。此时此刻,你的测试集其实就是开发集了,而新的数据集就是测试集了。书里为了简化只用了测试集
featuresets = [(gender_features(n), g) for (n,g) in names] # 抽取特征
train_set, test_set = featuresets[500:], featuresets[:500] # 数据集拆分成训练集和测试集
classifier = nltk.NaiveBayesClassifier.train(train_set) # 利用朴素贝叶斯训练模型3评价模型的好坏
分析模型跑出的测试集结果和测试集的标准结果的同异来评价模型的好坏。
1.最简单的方法,准确度,计算Ñ个样本中模型跑对了多少个。
print(nltk.classify.accuracy(classifier, test_set))2.准确度有时候会误导别人,在搜索任务中,试图找出与特定任务相关的文档,由于不相关的文档非常非常多,如果模型将所有文档都标记为不相关,那么准确度就很高了,这时候引入了新的概念。
精准度=模型标记为相关文档中有多少标记正确,即:准确度= TP /(TP + FP)
召回率=真正相关的文档有多少被找到了,即:召回= TP /(TP + FN)
F-度量=将进准度和召唤率合在一起看,不如就求一个调和平均吧,即1 / F1 = 1 /召回+ 1 /精度
当多分类问题时,相似的理念被提出 - 混淆矩阵,被应该被分到A的被分到B的有多少?
cm = nltk.ConfusionMatrix(gold, test) # 请注意这里gold是标准分类的list,test是模型的结果list4注意
1.复杂模型的训练不是一次性能成功的,需要反复测试,反复训练。特征的重新提取,模型的调整都是不错的调整策略。例如用名字判断性别的例子,是不是可以提取名字的后两位+后三位呢?
def gender_features(word):
return {'suffix1': word[-1:],'suffix2': word[-2:]}2.模型的训练过程中会遇到两类问题,欠拟合和过拟合。
欠拟合就是你的模型在训练集上就变现的很差了,需要考虑重新提取特征,或者更换模型。
过拟合就是你的模型在训练集上完美,但是测试集上一塌糊涂泛化能力几乎没有,这时候需要考虑增大训练集的数据量或者利用一些正则化的方法,解决该问题。
三 例子
用的是书上6.1节最后一个词性标注的例子。例子实现的是,词的前一个词的词性会影响到标注的结果。实现的难度在于如何获取到前一个词的词性信息。例子难在继承了一个已有的类,并且调用了其中的方法评估方法,为了便于阅读我直接将原方法粘贴出来了。
def pos_features(sentence, i, history): # 提取特征的方法
# 首先提取词的后几位
features = {"suffix(1)": sentence[i][-1:],
"suffix(2)": sentence[i][-2:],
"suffix(3)": sentence[i][-3:]}
# 接着提取词的前一个词的信息
if i == 0: # 如果词是首词的处理方式
features["prev-word"] = ""
features["prev-tag"] = ""
else: # 如果词不是首词则获取前一个词和它的词性
features["prev-word"] = sentence[i-1]
features["prev-tag"] = history[i-1]
return features
class ConsecutivePosTagger(nltk.TaggerI): # 定义一个类继承于nltk.TaggerI
# 这样定义的好处是有些方法就不用自己手写了,比如下文用到了tagger.evaluate,evaluate的方法其实是继承下来的
def __init__(self, train_sents): # 初始化,利用训练集训练模型
train_set = []
# 训练集的特征提取很简单,如下循环
for tagged_sent in train_sents:
untagged_sent = nltk.tag.untag(tagged_sent)
history = []
for i, (word, tag) in enumerate(tagged_sent):
featureset = pos_features(untagged_sent, i, history)
train_set.append( (featureset, tag) )
history.append(tag)
#训练一个朴素贝叶斯模型
self.classifier = nltk.NaiveBayesClassifier.train(train_set)
def tag(self, sentence): # 重写一个打标签的方法
# 重复调用训练好的贝叶斯模型,挨个给数据打标签
history = []
for i, word in enumerate(sentence):
featureset = pos_features(sentence, i, history)
tag = self.classifier.classify(featureset)
history.append(tag)
# 最终将原始句子和结果压缩在一起
return zip(sentence, history)
#这就是nltk.TaggerI的evaluate方法,首先用tag_sents方法给句子打标签(tag_sents会调用tag方法)
#接着把标准结果和模型的结果做一个准确度的比较 chain的用法简单理解成拼接比较好
'''
def tag_sents(self, sentences):
"""
Apply ``self.tag()`` to each element of *sentences*. I.e.:
return [self.tag(sent) for sent in sentences]
"""
return [self.tag(sent) for sent in sentences]
def evaluate(self, gold):
"""
Score the accuracy of the tagger against the gold standard.
Strip the tags from the gold standard text, retag it using
the tagger, then compute the accuracy score.
:type gold: list(list(tuple(str, str)))
:param gold: The list of tagged sentences to score the tagger on.
:rtype: float
"""
tagged_sents = self.tag_sents(untag(sent) for sent in gold)
gold_tokens = list(chain(*gold))
test_tokens = list(chain(*tagged_sents))
return accuracy(gold_tokens, test_tokens)
'''
tagged_sents = brown.tagged_sents(categories='news')
size = int(len(tagged_sents) * 0.1)
train_sents, test_sents = tagged_sents[size:], tagged_sents[:size]
tagger = ConsecutivePosTagger(train_sents)
print(tagger.evaluate(test_sents)) 下一篇文章,我将介绍一下朴素贝叶斯,决策树和最大熵模型。